MathReal:多模态大模型数学推理基准
来源:https://github.com/junfeng0288/MathReal
结论先行 (TL;DR)
新基准:关注真实世界中带有噪声的图像
现有困境:现有基准多使用清晰图像,未能反映真实教育场景中图像质量下降、透视变化和无关内容干扰等常见挑战
数据集:2,000 道手机拍摄的数学题
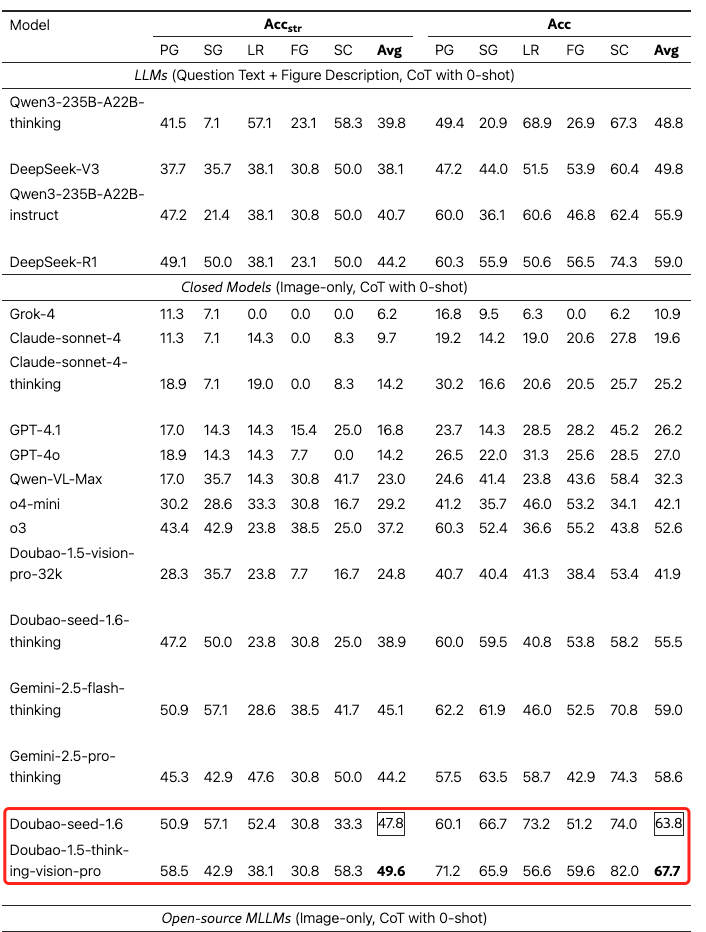
结果:即使是先进的 MLLM 在处理真实世界噪声时也面临显著挑战,其性能远低于在干净图像上的表现,Qwen-VL-Max 下降了 9.9%,Doubao-1.5-vision-pro 下降了 7.6%
MindMap
FAQ
Acc strict 和 Acc 区别
Acc str (Strict Accuracy) - 严格准确度
- 定义:要求一道问题中的所有子答案都必须正确,模型才能获得分数。如果任何一个子答案不正确,则整个问题都被标记为错误。
- 计算方式:如果问题的所有子答案都与参考答案数学等价,则得 1 分,否则为 0 分
Acc (Loose Accuracy) - 宽松准确度
- 定义:允许部分正确性,并根据每个问题中正确回答的子问题的比例进行计算
- 计算方式:它计算每个问题中正确预测的子答案占总子答案的比例,然后对所有问题求平均
主要区别与启示
- Acc str 和 Acc 之间存在明显差距,如 Gemini-2.5-pro-thinking 在 Acc 下得分为 48.1%,但在 Acc str 评估下下降到 42.9%
实验中提示词有可以参考的吗?比如裁判提示词?裁判用的是什么?
答案评估提示词(Mathematical Answer Evaluation Prompt)
以及一个前置的答案提取提示词(Answer Extraction Prompt)
裁判:GPT-4.1-nano
答案提取提示词 (Prompt for Answer Extraction Task)
◦ 角色定位:一个专业的答案提取专家。
◦ 核心任务:从模型输出文本中尽可能准确地提取最终答案,并严格遵循优先级策略。
◦ 优先级策略:
▪ 优先级1:寻找显式答案关键词:搜索“final answer”、“answer”、“result”、“the answer is”、“the result is”等关键词,或“therefore”、“so”、“in conclusion”等总结性词语,并提取紧随其后的内容。
▪ 优先级2:从文本末尾提取:如果在上一步中没有找到明确的答案,则尝试从文本的最后一段或最后一句话中提取最可能的答案。
◦ 重要要求:
▪ 多个答案应以分号 (;) 分隔。
▪ 只返回答案内容本身,不包含额外解释或格式。
▪ 如果无法确定答案,则返回“null”。
数学答案评估提示词 (Prompt for Mathematical Answer Evaluation Task)
◦ 角色定位:一个顶级的数学评估专家,任务是严谨而精确地判断模型生成答案的正确性。
◦ 核心任务:确定“模型答案”与“参考答案”在数学和选项上是否完全等价,并根据正确组件的比例分配部分分数。
◦ 评估原则:
▪ 数值核心优先级:只关注最终的数值、表达式、选项或结论。忽略解题过程、解释性文本(例如“the answer is:”)、变量名(例如D, E, Q1)和无关描述。
▪ 数学等价性(严格判断):
• 分数和小数:例如 1/2 等价于 0.5。
• 数值格式:例如 10 等价于 10.0,1,887,800 等价于 1887800(忽略千位分隔符)。
• 特殊符号:π 仅在问题明确允许近似时等价于 3.14。
• 代数表达式:x² + y 等价于 y + x²,但 18+6√3 与 18-6√3 不等价。
• 格式:例如 (√3+3)/2 等价于 √3/2 + 3/2。
• 范围表示法:x ∈ 等价于 0 ≤ x ≤ 1。
• 运算符敏感性:+、-、×、÷、^(幂)等必须严格一致,任何符号错误都导致表达式不等价。
• 坐标点:(x, y) 值必须数值相同。将 x 和 y 视为两个子组件,如果一个正确一个错误,则该点得 0.5 分。
• 空格影响格式的差异:例如“y=2x+3”和“y = 2 x + 3”等价。
▪ 单位处理:
• 参考答案无单位:模型答案包含正确合理单位(例如 15 vs 15m)被视为正确。
• 参考答案有单位:单位不正确(例如 15m vs 15cm)被视为错误;模型答案无单位但数值正确,被视为正确。
• 忽略单位格式差异:例如“180 dm²”和“180dm²”等价。
▪ 多部分答案处理(关键!):
• 必须根据结构将参考答案分解为所有子答案(空白)。
• 每个换行符“\n”、分号“;”或主要部分“(1)”、“(2)”表示一个单独的空白。
• 对于每个空白,如果包含多个组件,则进一步分解:
◦ “或”连接的答案:例如“5 or -75”→ 两个有效解。如果模型只回答“5”,则该空白得 0.5 分。
◦ 坐标对:例如 (5, 0) → 视为两个值。如果模型回答 (5, 1),得 0.5 分。
◦ 多个点:例如 (1, 0), (9, 8), (-1, 9) → 三个点。每个正确的点得 1/3 分。
• 总分 = 所有正确子组件的总和 / 子组件总数。
• 始终允许按比例的部分分数,除非明确说明。
▪ 多选题特殊规则:
• 如果参考答案是单一选项(例如“B”),则只要模型答案包含该选项字母(例如“B”、“B.”、“Option B”、“B. f’(x0)>g’(x0)”)且不包含其他选项,则视为正确 → 1.0。
• 如果出现多个选项或选择了不正确的选项,则视为错误 → 0.0。
▪ 语义等价性:即使措辞不同,只要数学意义相同,即视为正确。
▪ 证明或绘图题:如果问题类型是证明或绘图题,默认接受模型答案;不评分,直接返回 <score>1.0</score>。
◦ 评分标准:
▪ 1.0:所有组件都正确。
▪ 0.0–1.0:根据正确子组件的数量按比例分配部分分数。
▪ 0.0:没有组件正确。
▪ 四舍五入到小数点后两位。
◦ 输出格式:必须严格只返回包含分数的XML标签,不包含额外文本或解释:<score>score</score>