Manus Context Engineering
来源:https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
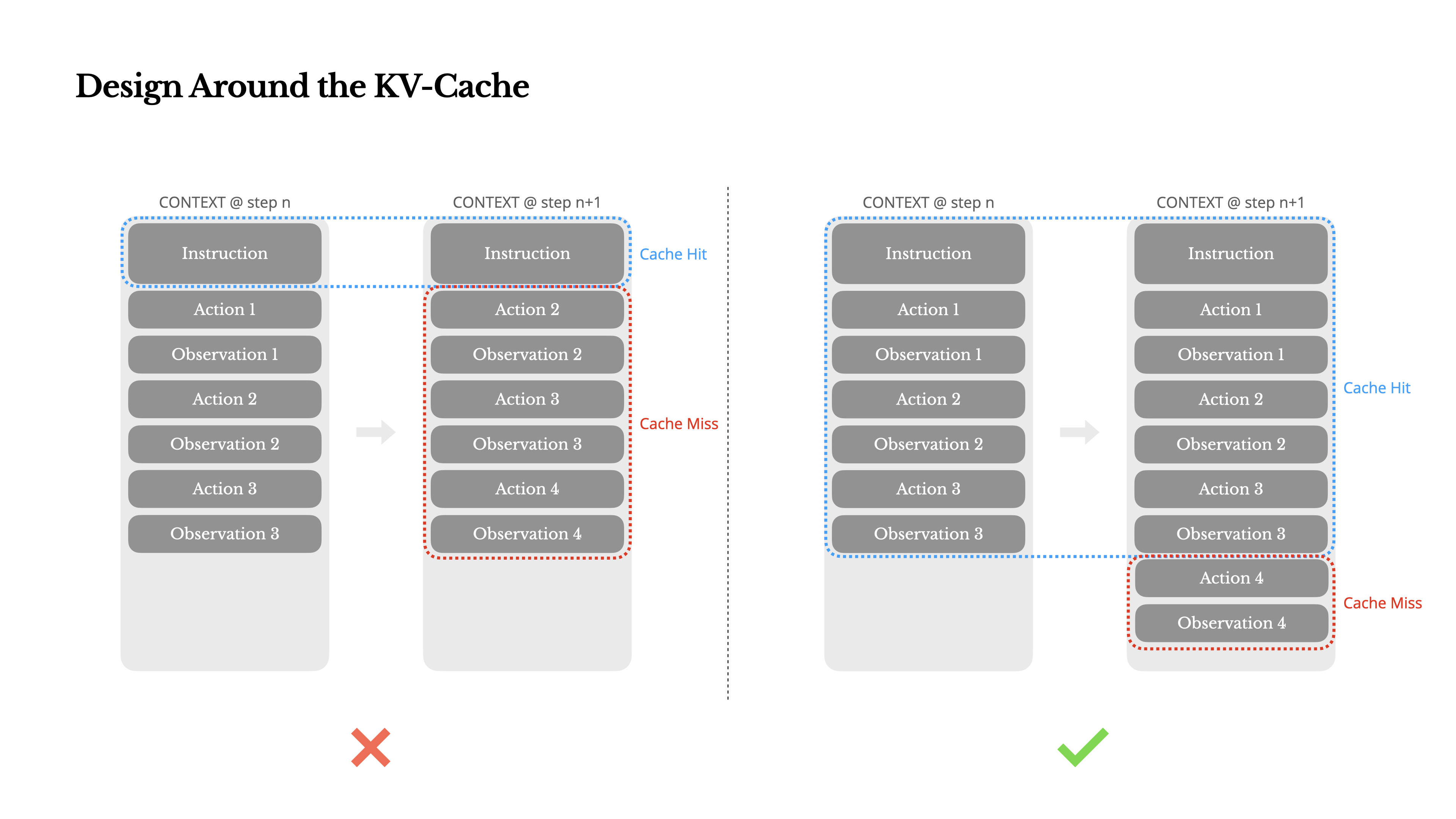
Design Around the KV-Cache
缓存命中率:如果只能选择一个指标,选择 KV-cache hit rate 作为生产阶段 agent 的最重要指标。
- 保持提示词前缀稳定(Keep your prompt prefix stable)
- 保持提示词往后追加(Make your context append-only)
- 缓存断点(Mark cache breakpoints explicitly when needed)
- a. 主流的商业 LLM API(如 OpenAI、Claude 等)或现代的开源高性能推理框架(如 vLLM、TensorRT-LLM),通常不需要显式设置缓存断点,它们会自动处理。
- b. 在较低层次上使用模型(例如,手动管理 Hugging Face Transformers 的
past_key_values),或者在构建自定义推理服务时,需要自行实现 KV Cache 的管理策略。在这种情况下,需要决定在哪里“切分”上下文,将前面的部分缓存起来,以便后续的请求可以高效地重用。
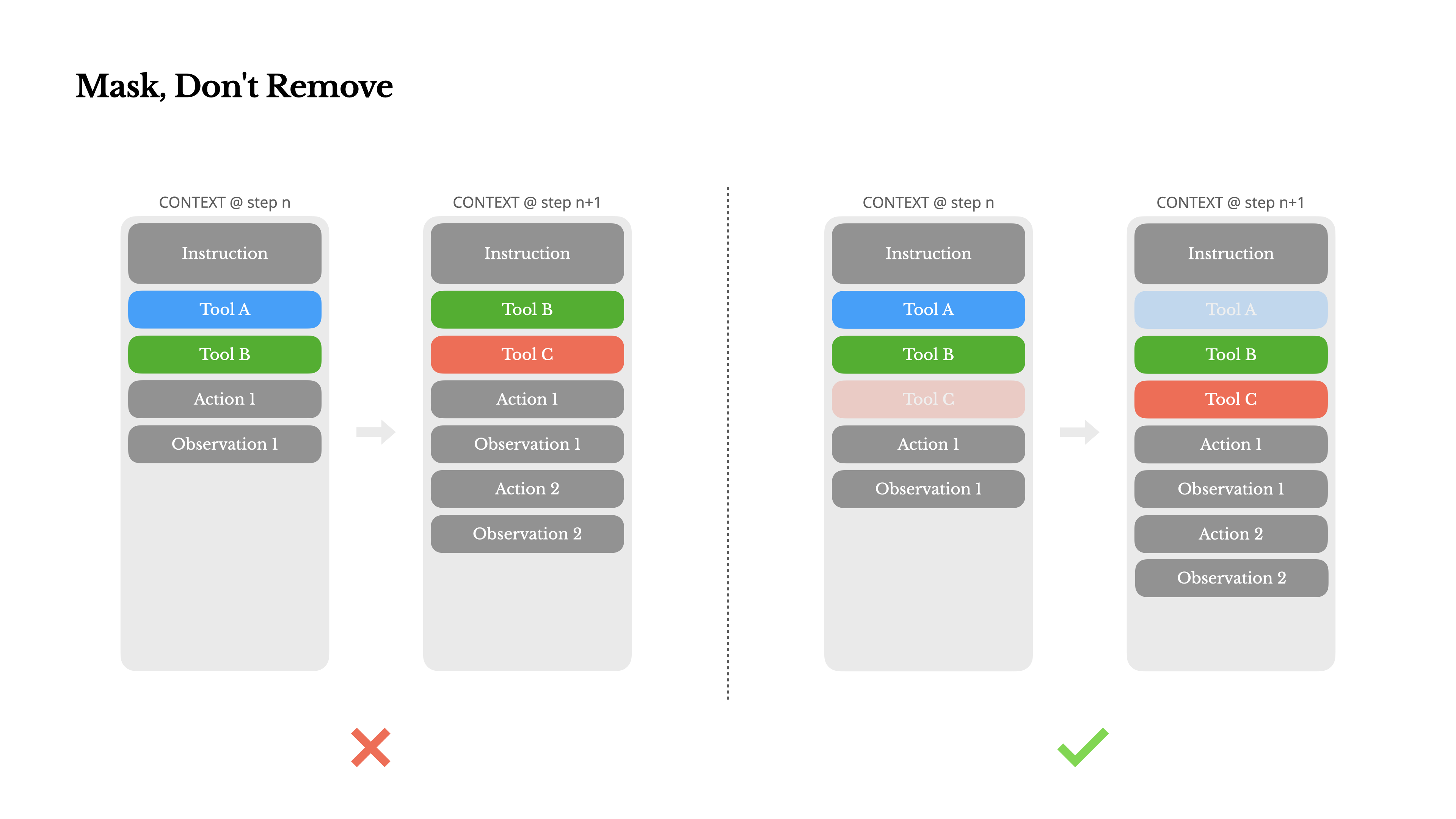
Mask, Don’t Remove
避免在迭代中动态增加或者移除工具。
- 大部分 LLM 在序列化后,工具定义在上下文前面,通常在系统提示词前或后。
- 当之前的 actions、observations 还在引用没有定义在当前上下文里的工具,模型会容易幻觉
Manus 使用 context-aware state machine 管理工具。
实践中,大部分 LLM 提供商或者推理框架支持 response prefill,约束 action space 而不用修改工具定义。
Hermes-Function-Calling
- a. Auto:模型可选是否调用,
<|im_start|>assistant - b. Required:模型必须调用,
<|im_start|>assistant<tool_call> - c. Specified:模型必须调用特定子集合,
<|im_start|>assistant<tool_call>{"name": “browser_
| 模式 | 目的 | 高级API实现 (OpenAI) | 开源模型直接实现 (Hermes格式) |
|---|---|---|---|
| 自动 (Auto) | 模型自由决定 | 设置 tool_choice=“auto” 或不设置 | 预填充到 <|im_start|>assistant |
| 必需 (Required) | 强制模型调用工具 | 设置 tool_choice=“required” | 预填充到 <|im_start|>assistant<tool_call> |
| 指定 (Specified) | 强制模型调用特定工具/工具组 | 设置 tool_choice={“function”: {“name”: …}} | 预填充到函数名前缀,如 <|im_start|>assistant<tool_call>{"name": “browser__ |
“移除”的含义
- 在构建 API 请求时,从
tools参数列表中物理上删除某些工具的定义。
例子:假设我们有 tools = [tool_A, tool_B, tool_C]。如果想禁止模型使用 tool_C:
# “移除”的方式
client.chat.completions.create(
model="...",
messages=...,
tools=[tool_A, tool_B] # 在这里物理上删除了 tool_C
)
“屏蔽”的含义
“屏蔽”(Masking)或“标记”是一种更动态、更底层的实现方式。具体做法是:
- API 请求中,
tools参数列表依然包含所有工具的完整定义。 - 通过一个额外的参数(如
tool_choice)或底层的 Logit Masking 机制,在模型生成回复的瞬间,动态地禁止某些 Token 的生成。
例子:禁止所有工具调用(即屏蔽 <tool_call>):
# “屏蔽”的方式
client.chat.completions.create(
model="...",
messages=...,
tools=[tool_A, tool_B, tool_C], # 所有的工具定义都在这里!
tool_choice="none" # 这个参数告诉后端:“请屏蔽掉 <tool_call>”
)
Logits:是 LLM 在预测下一个 token 时,为所有可能的 token 计算出的原始分数。分数越高,模型选择该 token 的可能性越大。
掩盖(Masking):就是将某些不希望模型选择的 token 的 logit 分数设置为一个非常小的值(接近负无穷),从而有效地阻止模型选择这些 token。
结合预填充:当你预填充了 <tool_call> 时,就相当于在后台“掩盖”了所有非工具调用的 token(比如普通文字的 token)的 logits,强制模型进入工具调用路径。
具体例子:
- 强制立即回复:在某些情况下(例如用户刚输入完),AI 代理需要立即提供一个自然语言的回复,而不是执行某个动作(调用工具)。这时,就可以通过掩盖
<tool_call>这个 token 的 logits,来强制模型生成一个文本响应。 - 工具命名规范化:Manus 团队特意设计了工具名称的命名规则,比如所有浏览器相关的工具都以
browser_开头,命令行工具以shell_开头。- 好处:结合“指定”模式的预填充,比如预填充
{"name": “browser_,可以非常方便地限制模型只能选择特定前缀的工具。
- 好处:结合“指定”模式的预填充,比如预填充