评估AI Agent的上下文压缩策略
执行摘要
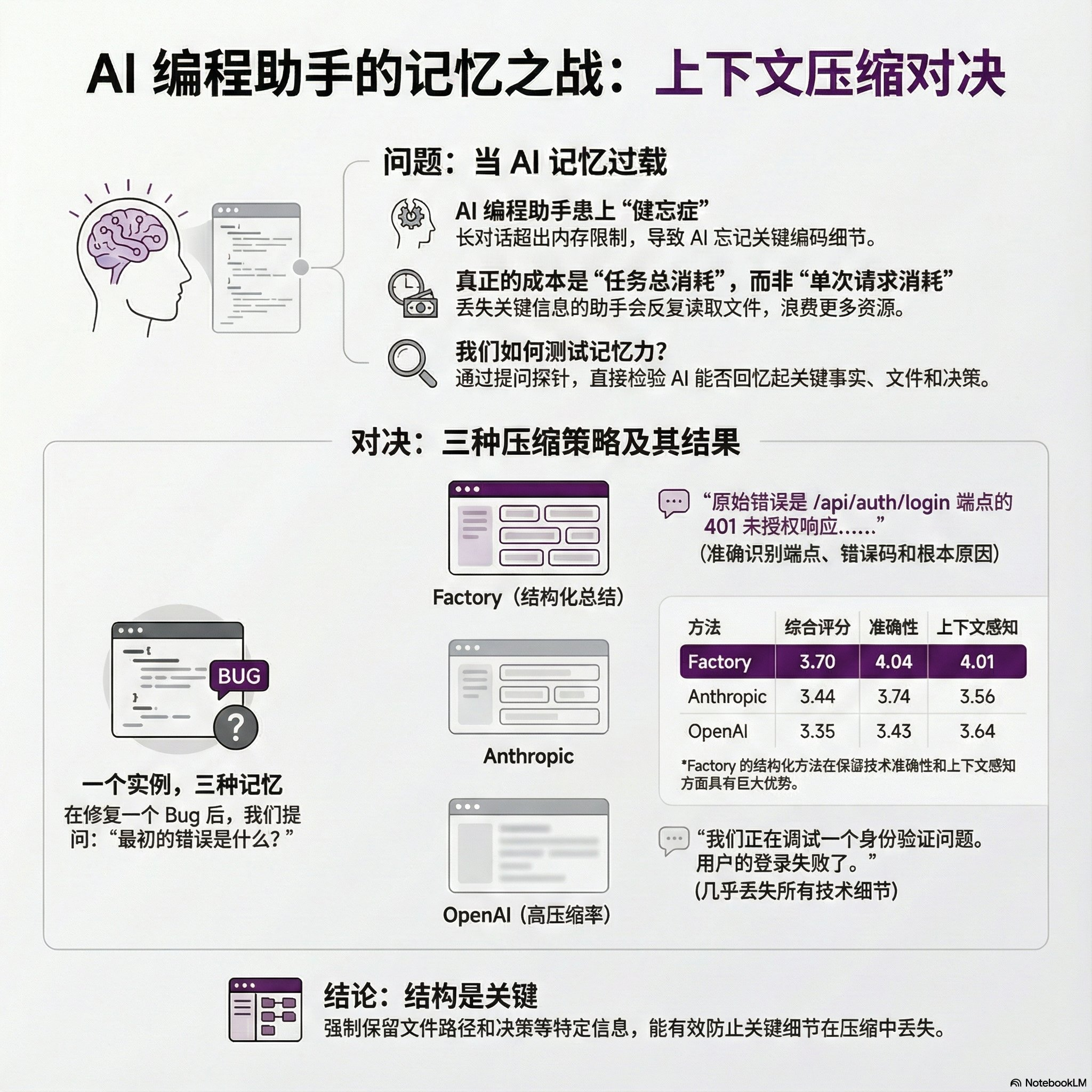
长会话超出上下文窗口会让AI Agent丢失关键信息。Factory.ai为此构建了基于探针的评估框架,用来衡量不同上下文压缩策略的“功能质量”。对比Factory、OpenAI与Anthropic三种方法,Factory的“锚定迭代式摘要”在保留技术细节上最佳:通过持续维护并增量合并结构化摘要,在准确性与上下文感知上领先,说明结构比单纯的压缩率更决定任务成败。
1. 核心问题:长对话中的上下文丢失
AI Agent在调试、代码审查或功能实现等复杂任务中,会产生数百万Token的对话历史,远超模型上下文窗口。激进压缩常导致代理遗忘关键信息(如改动过的文件、已尝试的方案),从而反复读取、重复探索。
研究指出,优化目标不应是“单次请求的Token数”(tokens per request),而应是“完成任务所需的总Token数”(tokens per task)。更高质量的上下文保留能减少返工,进而降低总消耗。
2. 评估框架:基于探针的功能性质询
传统摘要指标(如ROUGE或嵌入相似度)无法回答关键问题:压缩后的上下文还能否支撑代理继续工作。Factory.ai因此设计探针评估:向压缩后的代理提问必须依赖具体历史细节的问题,以直接衡量其功能质量。
探针类型
该框架使用四种探针,覆盖不同维度的信息保留:
| 探针类型 | 测试内容 | 示例问题 |
|---|---|---|
| 回忆(Recall) | 事实性信息的保留 | “最初的错误信息是什么?” |
| 工件(Artifact) | 文件追踪 | “我们修改了哪些文件?描述每个文件的变化。” |
| 延续(Continuation) | 任务规划 | “我们下一步该做什么?” |
| 决策(Decision) | 推理链 | “我们针对Redis问题讨论了哪些方案,最终决定是什么?” |
评估维度
由LLM裁判(GPT-5.2)按六个维度评分(0-5分),面向软件开发场景:
准确性 (Accuracy): 技术细节(如文件路径、函数名)是否正确。
上下文感知 (Context Awareness): 响应是否反映了当前的对话状态。
工件追踪 (Artifact Trail): 代理是否知道哪些文件被读取或修改过。
完整性 (Completeness): 响应是否解决了问题的所有部分。
连续性 (Continuity): 工作能否在不重新获取信息的情况下继续。
指令遵循 (Instruction Following): 响应是否遵循了格式或约束要求。
3. 三种压缩策略对比
研究评估了三种生产级的压缩策略:
Factory:锚定迭代式摘要 (Anchored Iterative Summarization)
机制: 维护一个包含明确分区(如会话意图、文件修改、决策)的持久化结构性摘要。当需要压缩时,仅对新截断的对话部分进行摘要,并将其合并到现有摘要中。
核心洞察: 结构强制保留。通过为特定信息类型设置专门的区域,可以防止关键细节(如文件路径)在自由形式的摘要中被无声地丢弃。
OpenAI:不透明压缩端点(
/responses/compact)机制: 生成面向重建保真度的不透明压缩表示。
特点: 压缩率最高(99.3%),但牺牲了解释性,用户无法直接读取压缩内容以验证保留了哪些信息。
Anthropic:内置上下文压缩 (Claude SDK)
机制: 生成包含分析、文件、待办任务等部分的详细结构化摘要。
与Factory的区别: 每次压缩时都会重新生成完整的摘要,而不是像Factory那样进行增量合并。这影响了摘要在多次压缩循环中的一致性。
4. 关键发现与量化结果
研究分析了来自生产环境(涉及代码审查、测试、错误修复等)的超过36,000条消息。
示例对比
在一个调试会话后,针对探针问题“最初的错误是什么?”,三种方法的响应质量差异显著:
Factory (4.8/5分): 准确指出了“/api/auth/login”端点的“401 Unauthorized”错误,并说明了根本原因是“Redis连接陈旧”。
Anthropic (3.9/5分): 提到了401错误,但丢失了具体的端点路径。
OpenAI (3.2/5分): 响应非常笼统,几乎丢失了所有技术细节,只提到“正在调试一个认证问题”。
总体性能数据
下表展示了三种方法在六个维度上的平均得分:
| 方法 | 总体得分 | 准确性 | 上下文感知 | 工件追踪 | 完整性 | 连续性 | 指令遵循 |
|---|---|---|---|---|---|---|---|
| Factory | 3.70 | 4.04 | 4.01 | 2.45 | 4.44 | 3.80 | 4.99 |
| Anthropic | 3.44 | 3.74 | 3.56 | 2.33 | 4.37 | 3.67 | 4.95 |
| OpenAI | 3.35 | 3.43 | 3.64 | 2.19 | 4.37 | 3.77 | 4.92 |
Factory表现领先: 总体得分比OpenAI高0.35分,比Anthropic高0.26分。其在准确性和上下文感知方面的优势最大,这直接归功于其结构化的摘要方法。
工件追踪是普遍弱点: 所有方法的得分都较低(2.19-2.45),表明仅靠通用摘要难以有效追踪文件修改历史。
压缩率与质量的权衡
OpenAI: 99.3%
Anthropic: 98.7%
Factory: 98.6%
尽管Factory的压缩率比OpenAI低0.7%,但其质量得分高出0.35分。这一权衡通常划算:更高质量的上下文可减少因信息丢失导致的重试,从而节省总Token。
5. 核心结论
结构至关重要: 通用摘要将所有内容一视同仁,而Factory的结构化方法强制保留了对任务至关重要的信息(如文件路径和决策),有效防止了“信息漂移”。
压缩率是错误指标: 真正的衡量标准是“完成任务的总Token数”。牺牲少量压缩率以换取更高的上下文质量,可以避免代价高昂的返工,从而提高整体效率。
工件追踪是未解难题: 所有被测方法在追踪文件创建和修改方面都表现不佳。这表明需要超越通用摘要的专门解决方案,例如独立的工件索引或显式的状态跟踪机制。
探针评估更有效: 与衡量词汇相似度的传统指标不同,基于探针的评估直接衡量摘要是否能支持代理继续执行任务,这对于代理工作流至关重要。