Coding Agent
🧩 Structured Communication(结构化交流)

核心流程:
与用户交流:了解挑战与需求。
提炼洞察:从交流中发现问题并构思目标。
规划方法:制定实现目标的策略。
分享计划:与团队成员同步。
转化代码:将计划落地为实际实现。
验证结果:测试与验证输出是否符合目标。
核心理念:把“思考—设计—实现—验证”过程显式化,让 AI 与人类都能在同一“规格语言(Spec)”下协作。
Kiro 的双模式:Vibe 与 Spec
| 模式 | 核心特征 | 适用场景 |
|---|---|---|
| Vibe 模式 | 对话式交互,快速提问、澄清、解释。 | 适用于探索性思考、需求分析、头脑风暴。 |
| Spec 模式 | 结构化任务处理,将想法转化为系统化的开发计划。 | 适用于项目落地、任务分解、进度跟踪。 |
🧩 两者关系:Vibe 强调互动与理解,帮助构建上下文;Spec 强调结构与执行,确保落地与追踪。二者并非对立,而是应融合使用。
工具与生态
spec-driven development 的发展

| 工具 / 模式 | 核心定位 | 特点 |
|---|---|---|
| Kiro Spec | AWS 规格驱动开发 IDE | 从编写规格开始开发,规格为核心工件,支持自动化与持续验证。 |
| GitHub Spec Kit | 开源规格工具包 | /specify 写规格、/plan 定方案、/tasks 拆任务;标准化流程并纳入版本控制。 |
| Cursor Plan | AI IDE | 编码前自动生成结构化开发计划。 |
| Claude Code/ Codex / Droid | CLI | 支持规划功能 |
哪个价值更为认可
代码 -> 编译器/解释器 -> 可执行程序
Spec doc -> LLMs -> 代码
评测
| 评测工具 | 核心定位 | 特点/说明 |
|---|---|---|
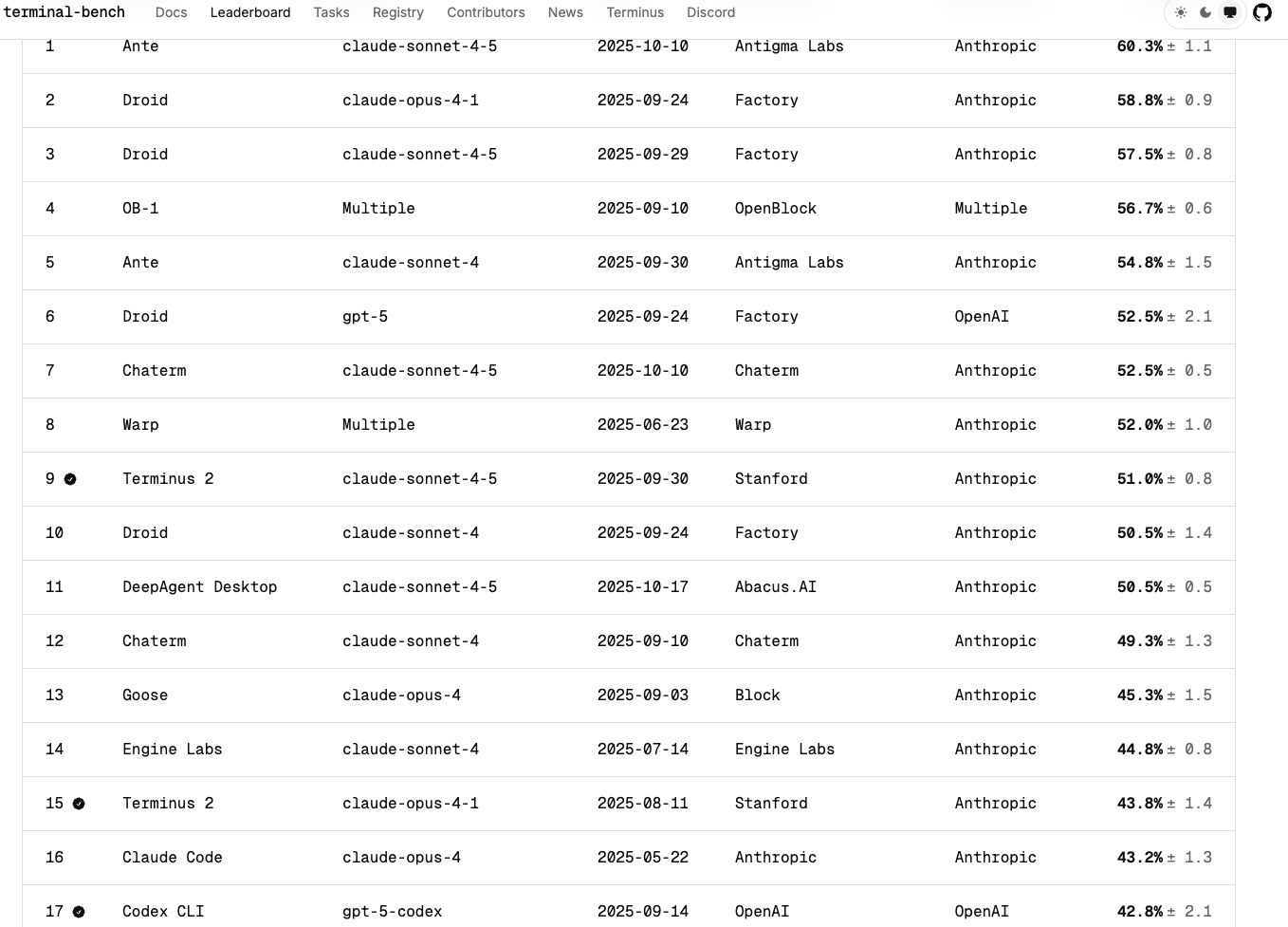
| Terminal-Bench | 开源的终端环境(CLI/命令行)AI Agent能力评测基准 | 包含真实的终端任务(如编译、安装、服务器配置、脚本执行)以及执行框架。 |
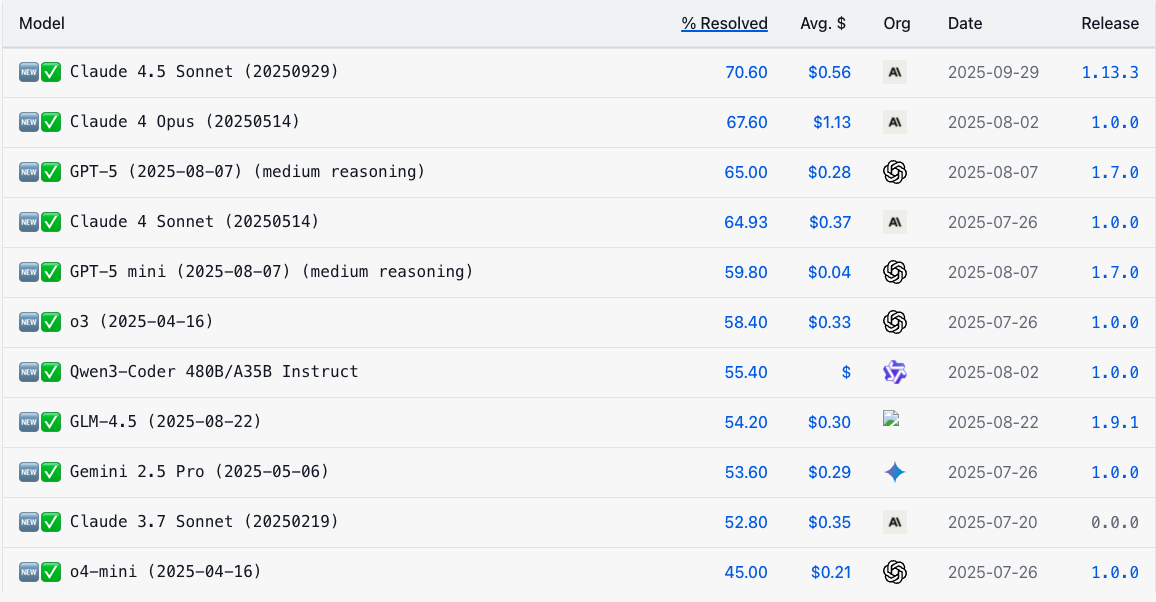
| SWE-bench | 真实软件工程任务(GitHub issues/bug 修复)评测基准 | 每个任务包含一个代码库和一个待解决的问题/缺陷,模型需要生成修补代码(patch)并通过测试。 |
terminal-bench leaderboard
swe-bench leaderboard
mini-swe-agent:极简主义 AI Agent
🎯 核心定位:100 行 Python 代码的 AI Agent,SWE-bench 验证集准确率 >70%
🔑 设计原则:
- 纯 Bash 交互 — 不使用任何自定义工具,不依赖 LM 的 tool-calling 接口
- 让 LM 直接生成 bash 命令(
cat,grep,sed,git等)而非调用预定义函数 - Shell 原生命令即工具集,通用性强、无需安装依赖
- 让 LM 直接生成 bash 命令(
- 完全线性历史 — 每步操作仅追加消息,轨迹 = 传给 LM 的提示词
- 传统 Agent:复杂的历史压缩、状态管理、上下文重组
- mini 方式:简单追加
- 优势:① 调试透明(看到的就是 LM 看到的)② 无信息损失
- 无状态执行 — 独立执行每个动作,易于切换沙箱环境
- 传统方式:保持持久 shell 会话,变量/环境/目录状态跨命令保留
- mini 方式:每个命令都是全新进程,不依赖前序状态
- 优势:① 单个命令失败不影响全局 ② 每个动作可独立沙箱化 ③ 易于并行执行
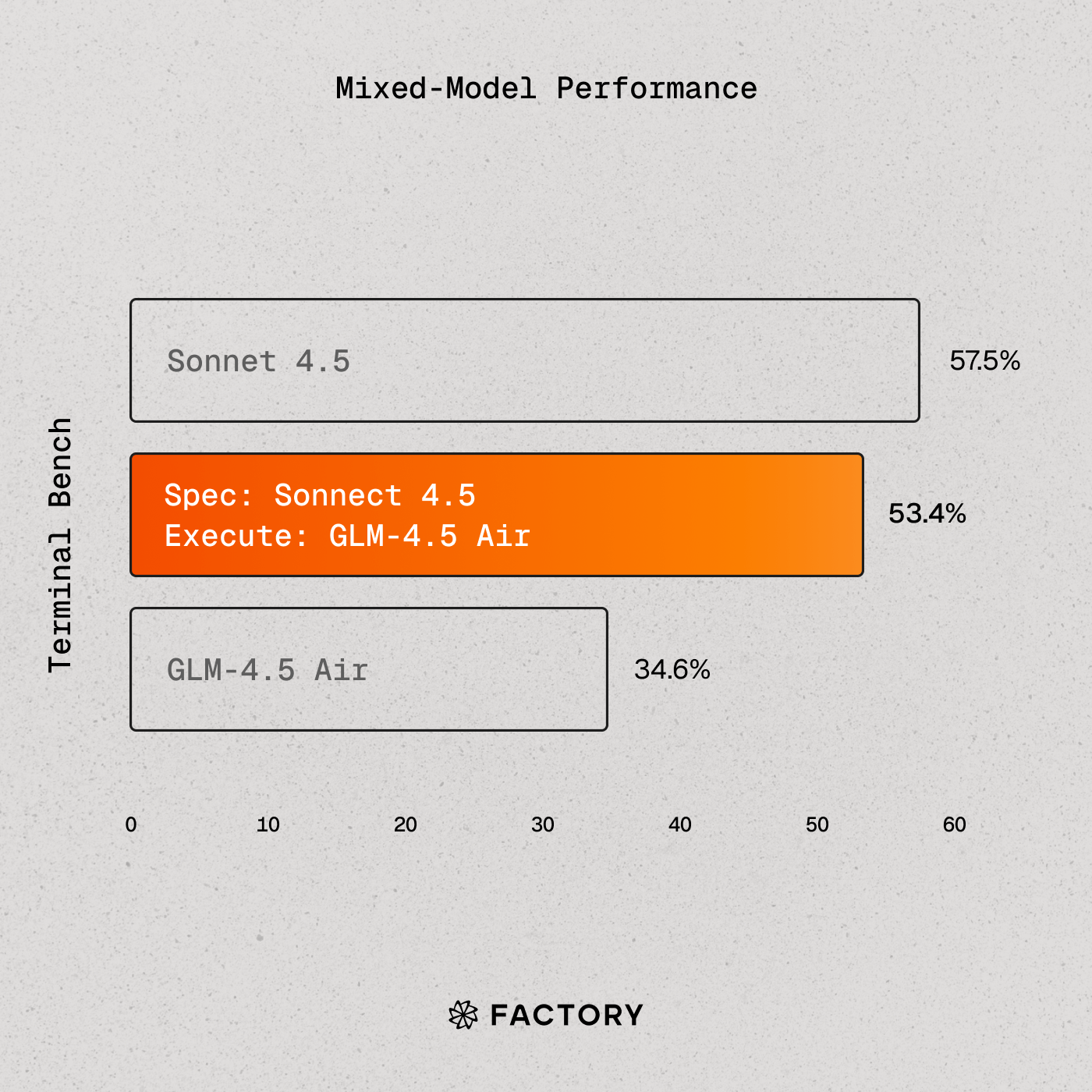
混合模型策略
Droid 支持混合模型
build a specification: a SOTA model
execute: a more cost-efficient model