Intro
“Building effective agents” 是 Anthropic 24 年 12 月发布的 Blog, “Demystifying evals for AI agents” 则是 26 年 1 月发布的 Blog,两者是有一定联系的,一个是如何构建高效的 Agent,一个是如何评估 Agent.
Part1: Building effective agents
Building blocks, workflows, and agents
Building block: The augmented LLM
LLM + 检索(retrieval)+ 工具(tools)+ 记忆(memory)
⇒ 为 LLM 提供一个简单、清晰、文档完善的统一接口
⇒ Model Context Protocol,

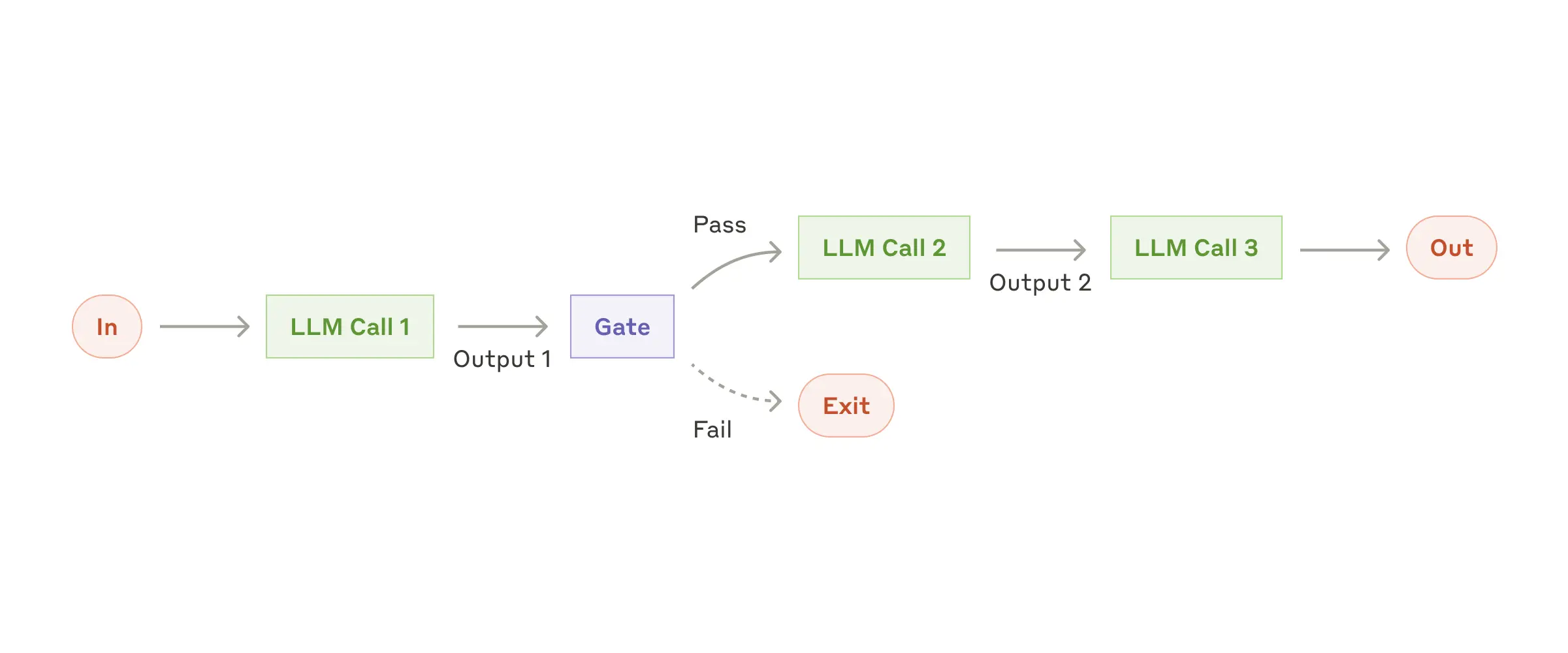
Workflow: Prompt chaining
- 将任务拆解为一系列步骤
- 示例:先做前置检查(pre-check),再进入正式处理(process)
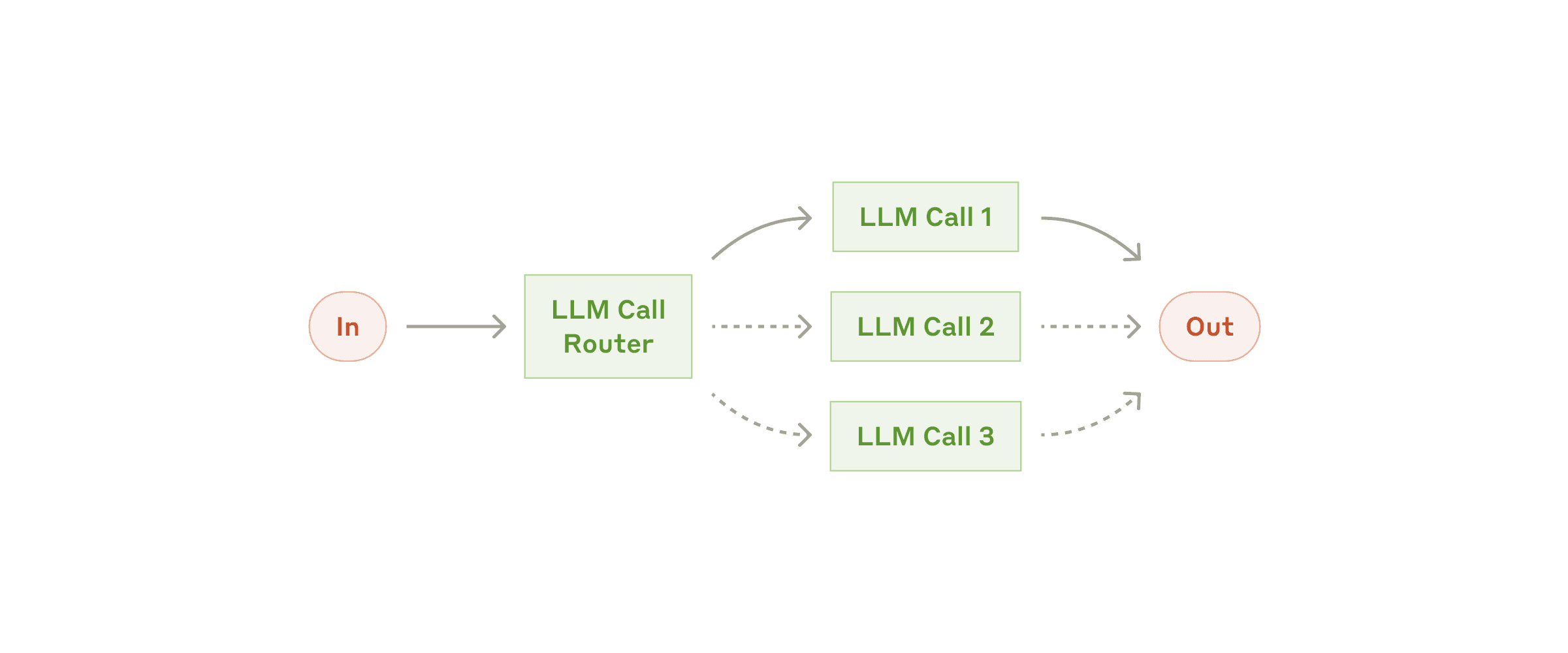
Workflow: Routing
- 对输入进行分类,并将其分发到对应的专用后续任务
- 示例:文本输入 → 文本模型;图片输入 → 视觉模型
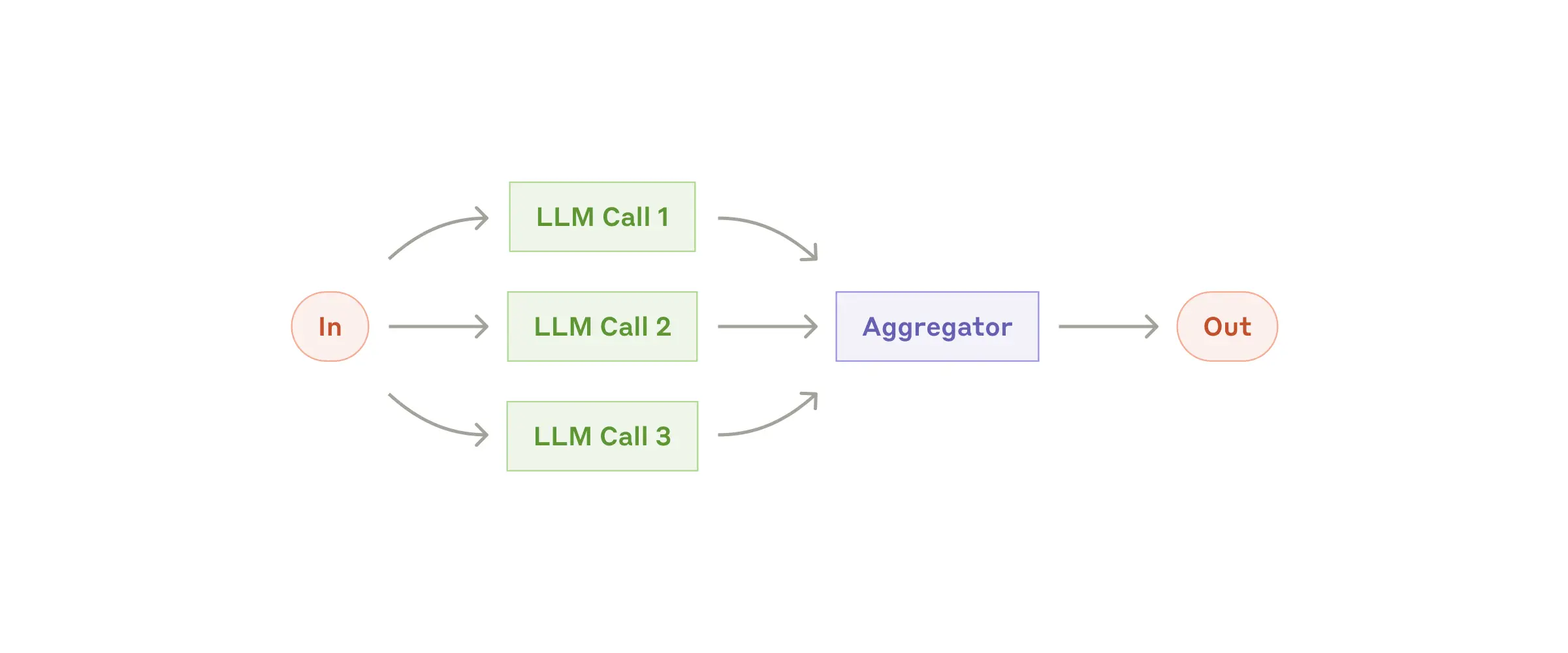
Workflow: Parallelization
- Sectioning(拆分并行):把一个任务拆成彼此独立的子任务,同时并行执行
- Voting(投票):对同一个任务多次运行,得到不同结果后再综合判断
- 示例:使用多个裁判(multiple judges)共同给出最终结论
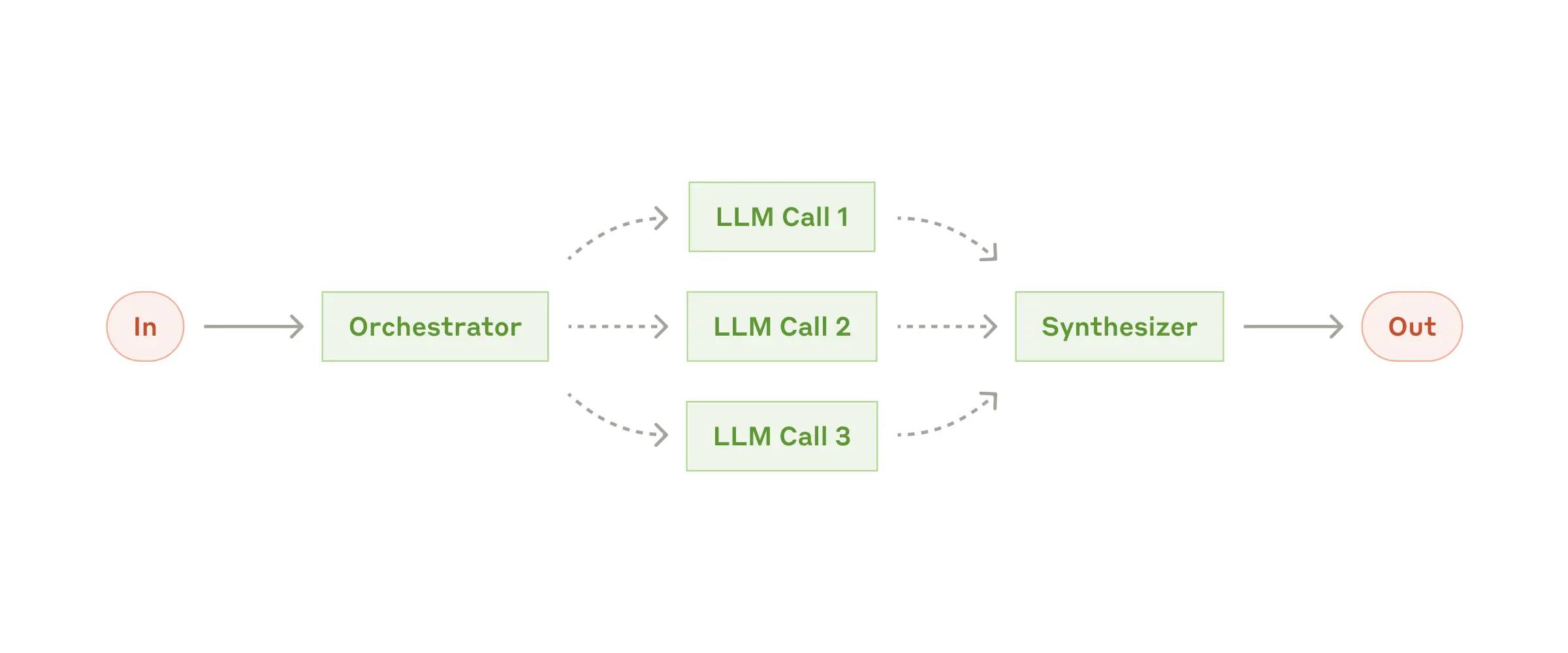
Workflow: Orchestrator-workers
由一个核心 LLM 动态拆解任务
→ 把子任务分配给多个 worker LLM
→ 最后再统一汇总、整合结果Parallelization(并行) vs Orchestrator–Workers(编排者-工作者)
- 并行:子任务是事先定义好的
- 编排者-工作者:子任务是运行过程中动态决定的
示例:Coding Agent
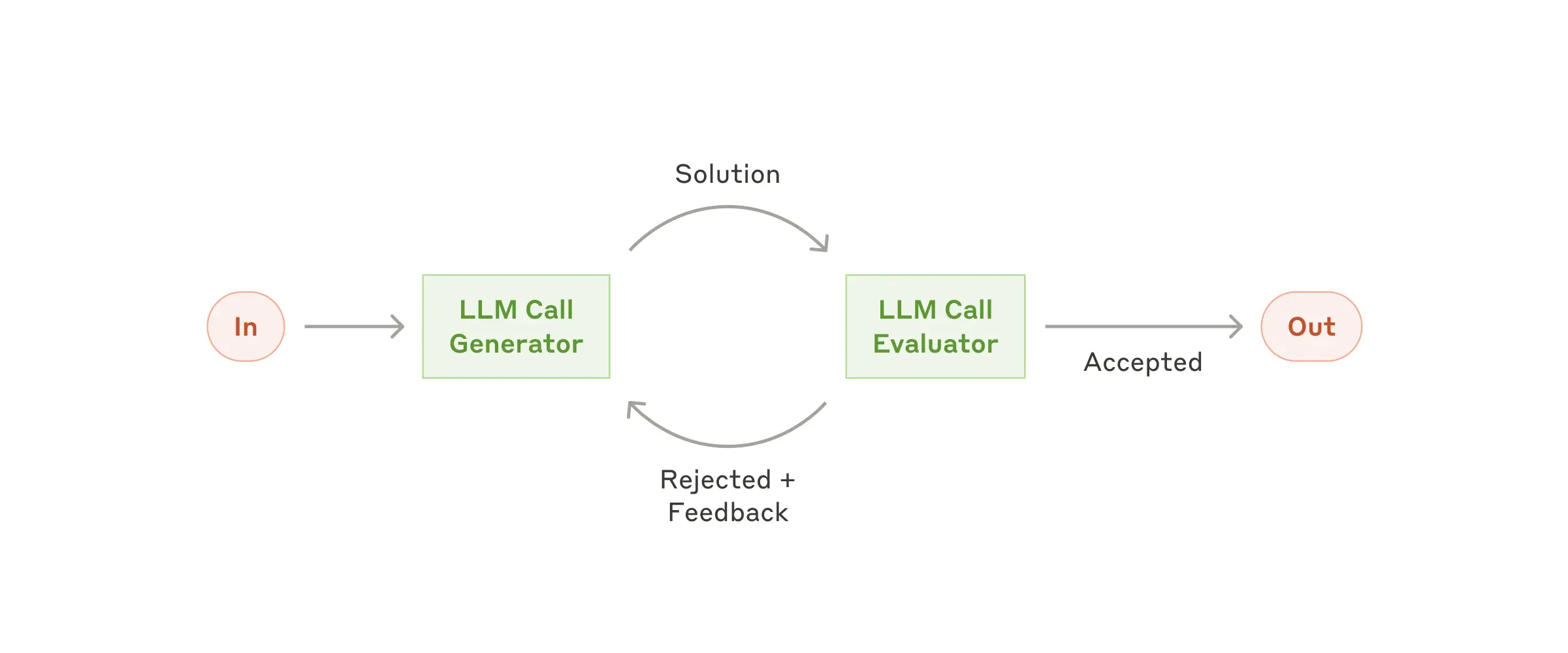
Workflow: Evaluator-optimizer
- 循环机制:一个 LLM 负责生成结果,另一个 LLM 负责评估并给出反馈
- 流程:生成 ↔ 评估 ↔ 修正,反复迭代
- 示例:复杂搜索任务(complex search tasks)
Agents
自主型 Agent
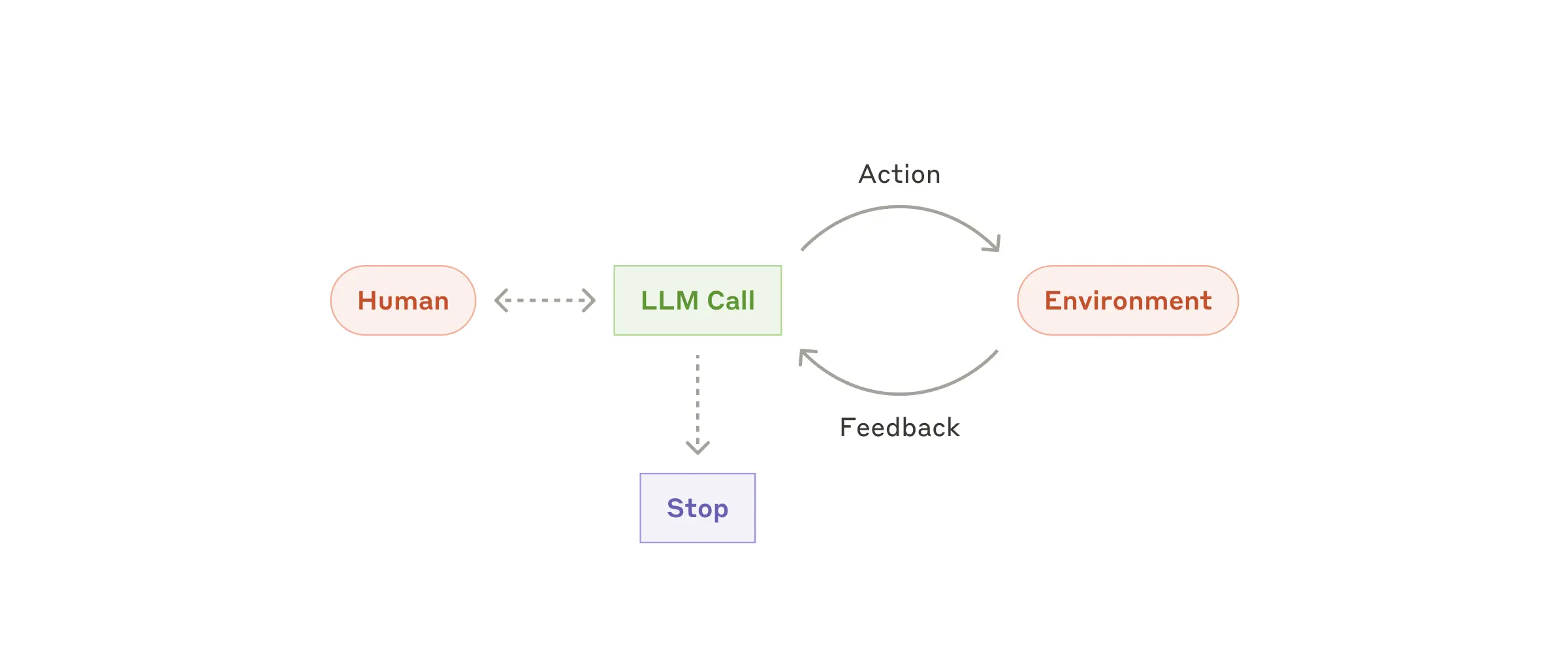
- 示例:一个自动写代码的 Agent,用来解决 SWE-bench 上的工程级问题
Part2: Demystifying evals for AI agents
The structure of an evaluation
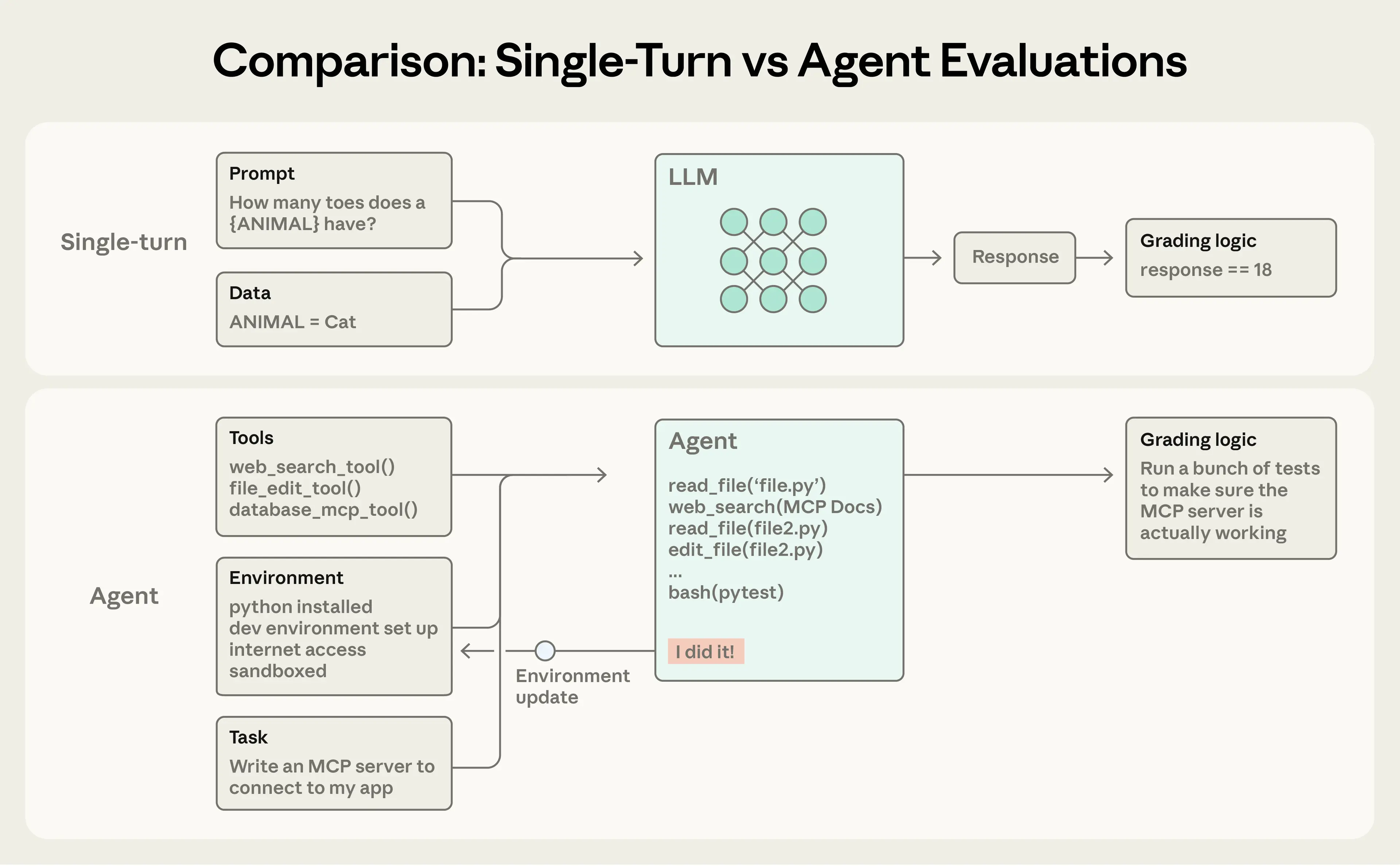
Single-turn evaluations(单轮评测):
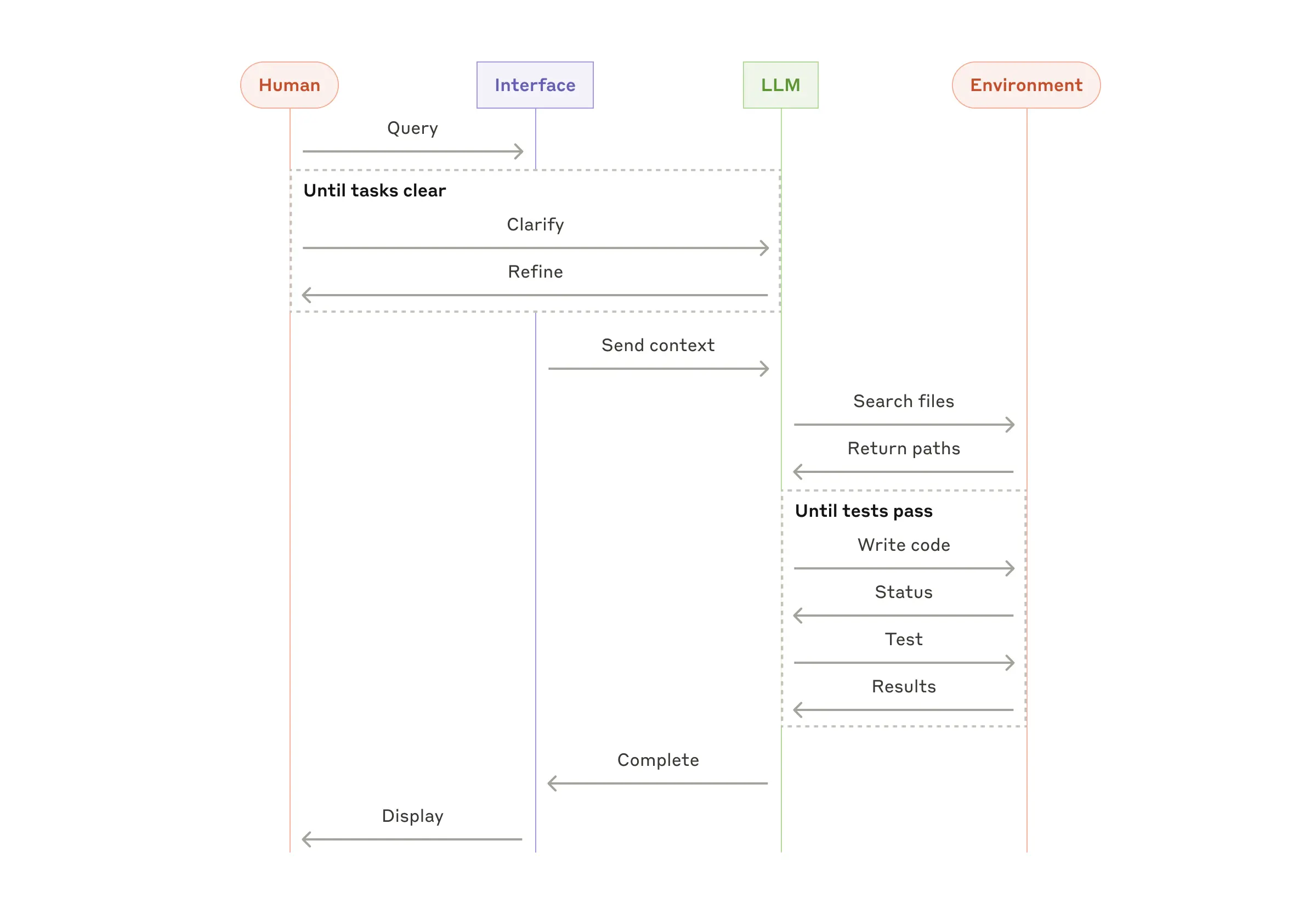
一个提示 → 一个回复 → 一次评估Multi-turn evaluations(多轮评测):
以 Coding Agent 为例:
工具 + 运行环境 + 任务
→ 进入「agent loop」(反复思考、调用工具、修改)
→ 最终用单元测试(unit tests)来验证结果
 Agent evaluations
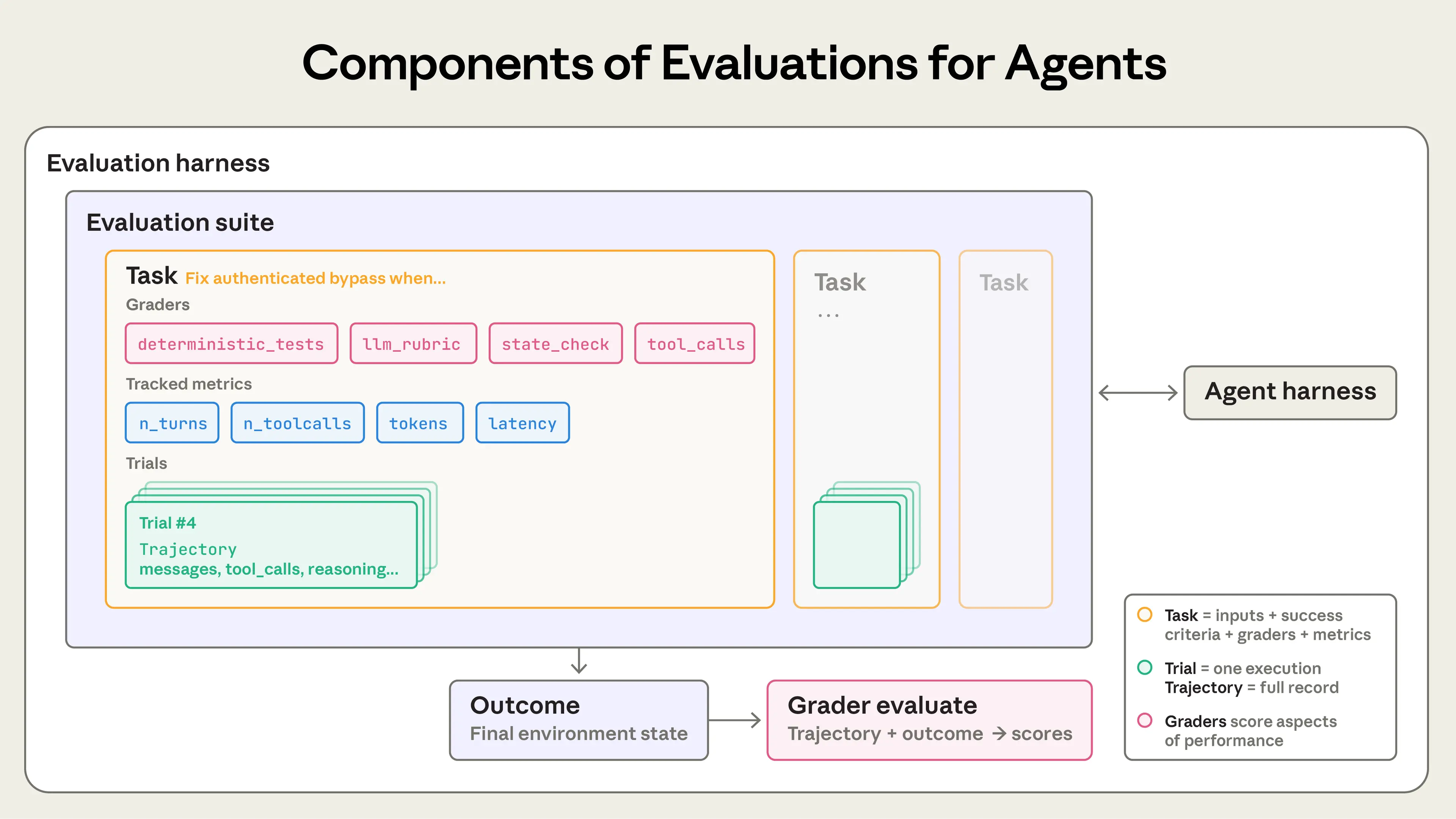
Agent evaluations
- Task(任务):一个具体测试题,有固定输入和“是否成功”的标准
- Trial(一次尝试):模型跑这个任务的一次执行
- Grader(评分器):用规则或代码打分
- Assertion(断言 / 检查点):评分器里的某一条具体检查
- Transcript(全过程记录):一次尝试的完整日志,包括模型输出、工具调用、中间步骤等
- Outcome(最终结果):这次尝试在真实环境中留下的最终状态
- Evaluation Harness(评测框架):把任务跑起来、记录过程、打分并汇总结果的一整套系统
- Agent Harness(Agent 外壳):让模型能当 Agent 用的那层系统,负责调度模型和工具
- Evaluation Suite(评测集):一组相关任务,用来测试某一类能力
Why build evaluations?
没有 evals,agent 只能靠感觉进化;有 evals,agent 才能被工程化地持续改进和规模化。
How to evaluate AI agents
Types of graders for agents
Code-based graders
| Methods | Strengths | Weaknesses |
|---|---|---|
| String match checks:字符串匹配检查(完全匹配、正则匹配、模糊匹配等) | 快 | 对于不完全符合预期模式但实际合理的变体很脆弱 |
| Binary tests:二元测试(失败→通过、通过→仍通过) | 成本低 | 缺乏精细度 |
| Static analysis:静态分析(代码规范、类型检查、安全检查) | 客观 | 对一些更主观的任务评估能力有限 |
| Outcome verification:结果验证 | 可复现 | |
| Tool calls verification:工具调用验证(使用的工具、参数) | 易于调试 | |
| Transcript analysis:对话记录分析(交互轮数、Token 使用量) | 可验证特定条件 |
Model-based graders
| Methods | Strengths | Weaknesses |
|---|---|---|
| Rubric-based scoring:基于评分标准的打分 | 灵活 | 非确定性 |
| Natural language assertions:自然语言断言 | 可扩展 | 成本高于代码评分 |
| Pairwise comparison:成对比较 | 能捕捉细微差别 | 需要与人工评分进行校准以保证准确性 |
| Reference-based evaluation:基于参考答案的评估 | 能处理开放式任务 | |
| Multi-judge consensus:多评审一致性 | 能处理自由格式输出 |
Human graders
| Methods | Strengths | Weaknesses |
|---|---|---|
| SME review:领域专家评审(Subject Matter Expert) | 高标准质量 | 成本高 |
| Crowdsourced judgment:众包评判(把评估任务分发给大量普通标注者) | 与专家用户判断一致 | 慢 |
| Spot-check sampling:抽样检查 | 用于校准 Model-based graders | 往往需要一定规模的领域专家 |
| A/B testing:A/B 测试 | ||
| Inter-annotator agreement:标注者一致性(看多个标注者对同一结果的判断是否一致) |
Capability vs. regression evals
- 能力评测(Capability evals)
关注“能做到什么”,通过率通常较低,用于推动能力提升。 - 回归评测(Regression evals)
关注“是否还能做到”,通过率接近 100%(曾经做对的题是否还能做对),用于防止能力倒退。
Evaluating coding agents
基本思路
Coding Agent 像人类开发者一样写代码、跑命令、调试和导航代码库。有效评测依赖于:
- 明确定义的任务
- 稳定的测试环境
- 完整、可重复的测试用例
确定性评分器 是首选
典型基准:
- SWE-bench Verified:给真实 GitHub issue,跑测试;修好失败测试且不破坏原有测试才算通过
- Terminal-Bench:评测端到端工程任务(如编译 Linux 内核、训练模型)
进展
LLM 在 SWE-bench Verified 上一年内从约 40% => 80% 以上。
进阶评测:看过程
在“过 / 不过”结果之外,还应评测过程本身:
- 代码质量:基于规则的代码质量检查
- 基于模型的评分器,评估工具调用方式、交互行为等
示例:Coding Agent 的理论评测
设想一个编程任务:Agent 需要修复一个认证绕过漏洞。
参考YAML 文件,可以同时使用评分器(graders) 和 指标(metrics) 来评估该 agent
task:
id: "fix-auth-bypass_1"
desc: "Fix authentication bypass when password field is empty and ..."
graders:
- type: deterministic_tests
required: [test_empty_pw_rejected.py, test_null_pw_rejected.py]
- type: llm_rubric
rubric: prompts/code_quality.md
- type: static_analysis
commands: [ruff, mypy, bandit]
- type: state_check
expect:
security_logs: {event_type: "auth_blocked"}
- type: tool_calls
required:
- {tool: read_file, params: {path: "src/auth/*"}}
- {tool: edit_file}
- {tool: run_tests}
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_token
Evaluating conversational agents
基本思路
对话型 Agent 像真人一样与用户持续交互,维护状态、调用工具,并在对话中采取行动。与其他 agent 不同的是,交互质量本身就是评测目标的一部分。有效评测依赖于:
- 明确定义的任务目标与成功状态
- 可验证的最终结果(state)
- 清晰的对话与行为规范
评分方式选择
对话型 Agent 通常无法只用确定性测试完成评估,需要结合多种方式:
- 状态检查(问题是否解决)
- 对话约束(轮数、时长、是否跑偏)
- 基于评分标准的模型评分(语气、清晰度、帮助程度)
典型基准
- τ-Bench:多轮对话基准,覆盖零售客服等真实场景
- τ2-Bench:τ-Bench 的升级版,引入更复杂的用户行为与任务组合
评测特点
对话成功往往是多维的,例如:
- 是否完成任务(如退款是否成功)
- 是否在合理轮数内完成
- 语气是否得体、专业、不激化冲突
进阶评测:看过程
在“完成 / 未完成”之外,还应评测对话过程本身:
- 行为质量:是否合理调用工具、是否多余或遗漏关键步骤
- 交互质量:是否清晰、礼貌、符合用户情绪
- 资源消耗:对话轮数、Token 使用量、总体成本
示例:对话型 Agent 的理论评测
设想一个客服任务:agent 需要为一位情绪不满的客户处理退款请求。
graders:
- type: llm_rubric
rubric: prompts/support_quality.md
assertions:
- "Agent showed empathy for customer's frustration"
- "Resolution was clearly explained"
- "Agent's response grounded in fetch_policy tool results"
- type: state_check
expect:
tickets: {status: resolved}
refunds: {status: processed}
- type: tool_calls
required:
- {tool: verify_identity}
- {tool: process_refund, params: {amount: "<=100"}}
- {tool: send_confirmation}
- type: transcript
max_turns: 10
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_token
Evaluating research agents
基本思路
Research Agent 做信息检索、整合与分析,输出答案或报告。研究质量无法简单用对 / 错衡量,需结合具体任务评估。
评测方式
- 精确匹配:用于客观事实问题
- 覆盖度与依据性检查:是否包含关键事实、是否有可靠来源
- 基于模型的评分器:评估整体质量
典型基准
- BrowseComp:开放网络中的高难度检索评测
关键点
研究评测具有主观性,模型评分需与专家判断持续校准。
Computer use agents
基本思路
Computer use Agent 通过截图、鼠标、键盘等 GUI 方式操作软件,而不是通过 API 或代码。评测需要在真实或沙箱环境中运行 agent,并验证其是否达成预期结果。
评测方式
- 页面与状态检查:是否导航到正确页面
- 后端状态验证:是否真正修改了数据,而非只看到确认页面
- 环境检查:文件系统、配置、数据库、UI 元素状态等
典型基准
- WebArena:浏览器任务评测
- OSWorld:全操作系统级别评测
进阶评测:工具选择
浏览器 agent 需在延迟与 token 成本之间权衡:
- DOM 操作:快但 token 高
- 截图操作:慢但 token 低
评测重点之一是:是否在不同场景下选择了合适的交互方式,以提升整体效率与准确性。
How to think about non-determinism in evaluations for agents
无论哪类 agent,多次运行的行为都会不同,同一任务可能一次成功、下一次失败。因此评测关注的不只是“是否成功”,而是成功的概率。
两个关键指标:
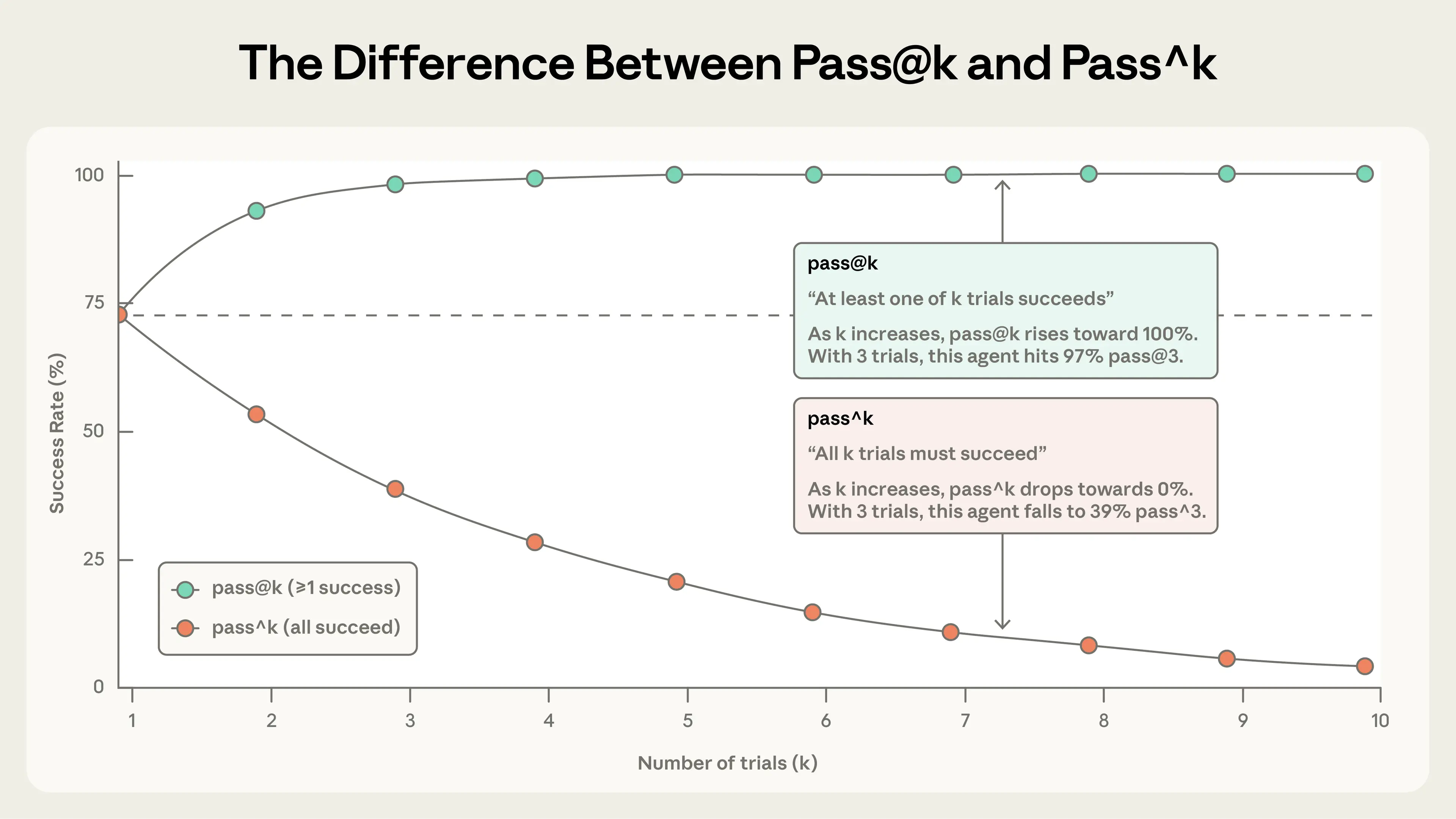
pass@k
衡量在 k 次尝试中至少成功一次 的概率。
- k 越大,pass@k 越高
- pass@1 表示首次尝试的成功率
- 适用于允许多次尝试、只需一次成功的场景
pass^k
衡量在 k 次尝试中全部成功 的概率。
- k 越大,pass^k 越低
- 强调一致性与稳定性
- 适用于要求每次都可靠的场景
直觉对比:
- 当 k = 1 时,pass@k = pass^k
- 随着 k 增大,pass@k → 100%,而 pass^k → 0
选择原则:
- 一次成功即可 → 使用 pass@k
- 每次都要稳定 → 使用 pass^k
Going from zero to one: a roadmap to great evals for agents
核心原则:尽早定义成功、清晰度量、持续迭代。Evals 是 agent 工程化的基础设施。
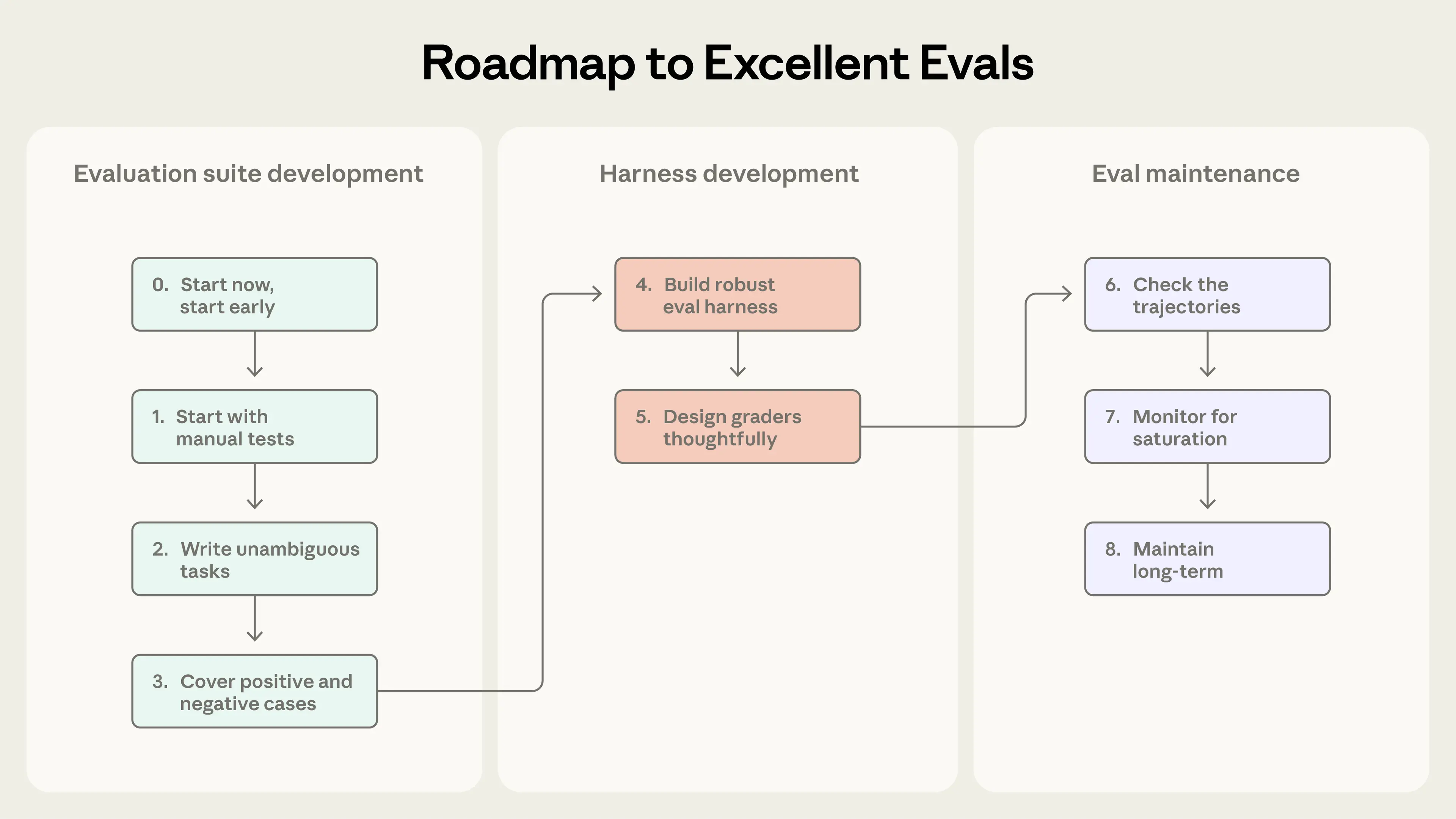
Step 0:尽早开始
- 不需要上来就几百题
- 20–50 个来自真实失败的任务就足够
Step 1:从已有人工检查开始
- 从 Bug tracker / 支持工单中提取任务
- 按用户影响优先级排序
Step 2:写清晰、无歧义的任务 + 参考解
- 两个专家应能给出一致的通过 / 不通过判断
- grader 检查的内容必须在任务描述中明确
- 0% pass@k 往往是任务或 grader 有问题
- 每个任务都应有一个参考解,证明任务可解、grader 正确
Step 3:构建平衡的问题集
- 同时测试「应该发生」和「不该发生」
Step 4:稳定的 eval harness
- eval 中的 agent 行为应接近生产环境
- 每次 trial 必须 环境隔离
- 避免共享状态(缓存、文件、资源耗尽)
Step 5:谨慎设计 graders
- 优先 确定性 grader,必要时用 LLM grader
- 少用「强约束路径检查」,多评结果而非过程
- 复杂任务应支持 部分得分
- LLM grader 需与人工专家频繁校准
- 允许返回 Unknown 以避免幻觉
- 防止 grader 被绕过或作弊
Step 6:阅读 transcripts
- 成功 or 失败应当是公平、可解释的
Step 7:警惕能力评测饱和
- 100% eval 只防回归,不推动进步
- 饱和后,真实能力提升可能只反映为小幅分数变化
- 必须引入 更难、更 agentic 的 eval
Step 8:长期维护 eval 套件
- eval 驱动开发(eval-driven development):
- 先写 eval,再等模型追上
一句话总结:
好的 eval 能在功能失败前暴露问题,在模型升级时放大收益。
How evals fit with other methods for a holistic understanding of agents
评测与其他方法如何配合
自动化 eval 只是理解 agent 表现的一部分,完整视角需要多种方法结合。
核心方法与作用:
- 自动化 eval:快、可复现、适合 CI 与上线前,防止回归
- 生产监控:反映真实用户行为,发现合成评测遗漏的问题
- A/B 测试:验证重大改动对真实用户指标的影响
- 用户反馈:暴露未预期的问题,但信号稀疏
- 人工阅读对话:发现细微质量问题,用于校准直觉
- 系统化人工评测:主观任务的金标准,用于校准模型评分器
使用原则:
- 上线前靠 自动化 eval
- 上线后靠 生产监控 + A/B 测试
- 全程辅以 用户反馈与人工复查
瑞士奶酪模型
- 每一层奶酪 = 一种评测方式
(自动化 eval、人工复查、线上监控、A/B 测试、用户反馈等) - 每个洞 = 这种方法必然漏掉的问题
- 一条失败路径 = 一个 bug / 坏行为
单层评测:
洞可能正好对齐 → 问题直接漏过去 ❌
多层评测叠加:
洞不可能完全对齐 →
即使漏过一层,也会在下一层被拦住 ✅
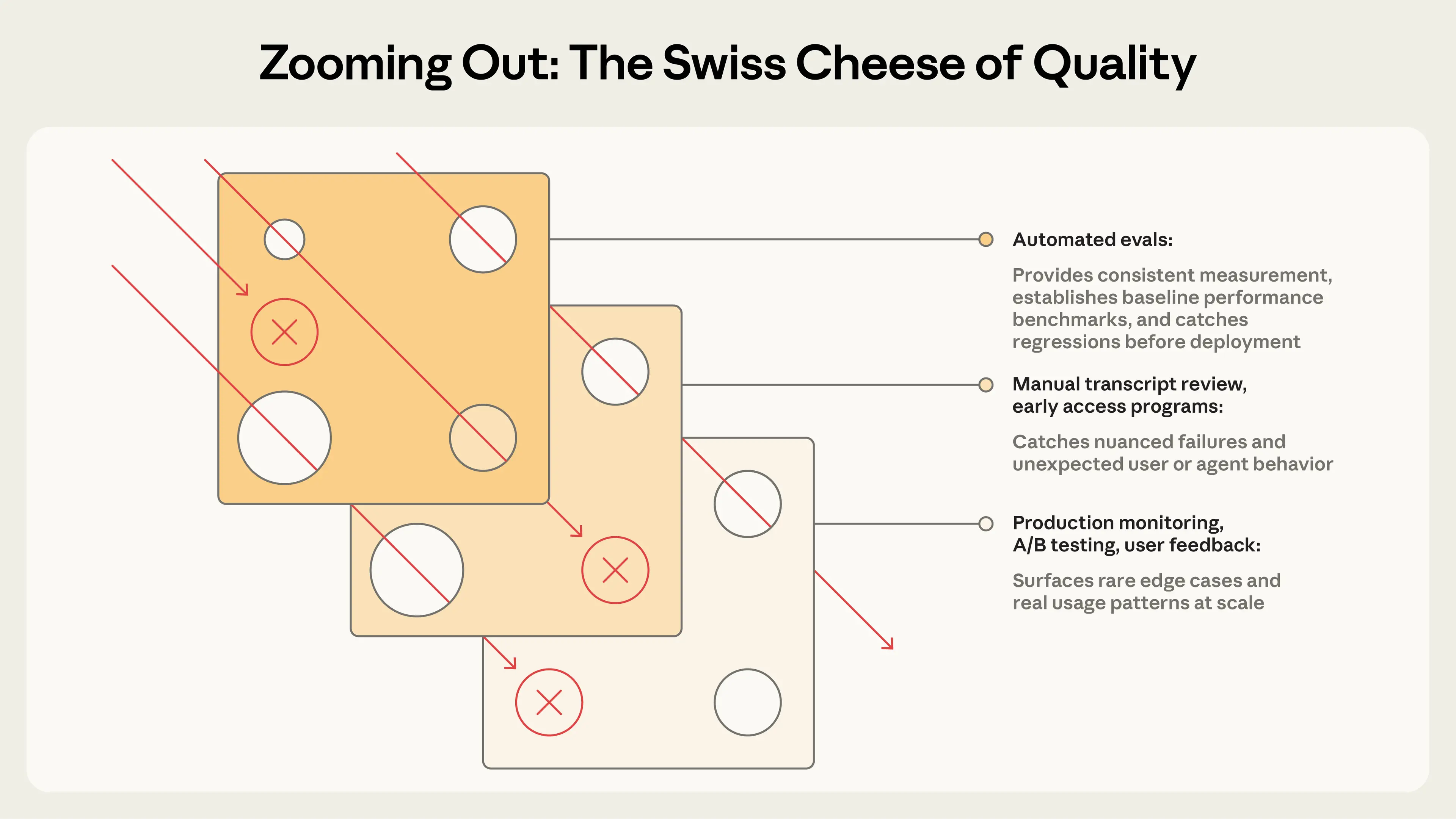
一句话总结:
没有单一方法能覆盖所有问题,只有多层评测组合才能可靠理解 agent 表现。
Conclusion
把 eval 当作核心基础设施,而不是事后补丁。 AI agent 评测仍是一个快速演进的领域。随着 agent 任务变长、多 agent 协作增多、工作更具主观性,评测方法也需要不断调整。
Appendix: Eval frameworks
有多种开源与商业框架可帮助团队快速落地 agent 评测,而无需从零搭建基础设施。选择取决于 agent 类型、现有技术栈,以及是偏离线评测、线上监控,还是两者兼顾。
Harbor
面向容器化 agent 的评测框架,支持跨云大规模运行 trial,并提供统一的任务与 grader 定义格式。
如 Terminal-Bench 2.0 等基准可直接通过 Harbor registry 运行。
Promptfoo
轻量、灵活、开源,基于声明式 YAML 配置做 prompt 与 agent 评测。
支持从字符串匹配到 LLM-as-judge 的多种断言,是常见的产品评测起点。
Braintrust
结合离线评测、线上可观测性与实验追踪的平台。
其 autoevals 库内置事实性、相关性等常用评分器,适合同时开发与生产监控的团队。
LangSmith / Langfuse
- LangSmith:提供 tracing、离线/在线评测与数据集管理,深度集成 LangChain
- Langfuse:功能相近的自托管开源方案,适合有数据合规要求的团队
实践中,很多团队会组合多种工具,或先用简单脚本起步。
关键不在于框架本身,而在于:
评测任务与 grader 的质量决定了 eval 的价值。
最佳策略通常是:先选一个顺手的框架,再把精力投入到高质量任务与评分标准的迭代上。