How to Solve Cache Penetration?
Cache penetration occurs when requests for non-existent data bypass the cache and hit the database repeatedly. Solutions include:
- Caching Empty Results: Store empty results for non-existent keys with a short expiration time.
- Bloom Filters: Use a Bloom filter to check if a key exists before querying the database.
- Rate Limiting: Limit requests for certain keys to prevent overwhelming the database with requests for non-existent data.
How to Solve Cache Avalanche?
Cache avalanche involves a massive number of database hits due to the simultaneous expiration of many cache entries or a cache server failure.
While rate limiting (a solution for cache penetration) can help mitigate the impact of a cache avalanche by reducing the load on the database, it doesn’t prevent the avalanche itself. The core of solving a cache avalanche lies in different strategies:
- Staggered Expiration: Instead of setting the same expiration time for all cache entries, vary the expiration times slightly to prevent mass simultaneous expirations.
- Cache Clustering/Redundancy: Use multiple cache servers to distribute the load and provide redundancy. If one server fails, others can continue serving requests.
- Cache Pre-warming: For frequently accessed data, proactively load it into the cache before it’s requested.
- Circuit Breakers: Implement circuit breakers to prevent cascading failures. If the database becomes overloaded, the circuit breaker can temporarily stop sending requests to it, preventing further overload.
What Are the Communication Methods Between Different Services?
Different services can communicate through various methods:
- HTTP/REST APIs: Synchronous communication using standard HTTP methods.

- gRPC: High-performance RPC framework using HTTP/2.
- Message Queues: Asynchronous communication via message brokers like RabbitMQ or Kafka.
- WebSockets: For real-time bidirectional communication between clients and servers.
What Are the Steps Involved in an RPC Call?
An RPC call typically involves these steps:
- The client sends an RPC request to the server.
- The client stub serializes the request into a suitable format (e.g., JSON or Protobuf).
- The request is sent over the network to the server.
- The server receives and deserializes the request.
- The server processes the request and prepares a response.
- The response is serialized and sent back to the client.
- The client stub deserializes the response for use.
How Can Performance Tuning Be Done in RPC Frameworks?
To optimize performance in RPC frameworks:
- Use efficient serialization formats (e.g., Protobuf).
- Implement connection pooling to reuse connections.
- Use asynchronous calls where possible to avoid blocking.
- Optimize network latency through compression or batching requests.
Which RPC Frameworks Have You Used?
Commonly used RPC frameworks include:
- gRPC: A modern high-performance framework developed by Google.
- Apache Thrift: A cross-language framework developed by Facebook.
- Dubbo: A Java-based RPC framework from Alibaba.
- JSON-RPC: A remote procedure call protocol encoded in JSON.
Describe Circuit Breaker, Rate Limiting, Downgrading, and Avalanche Effects
- Circuit Breaker: Prevents repeated calls to failing services by temporarily blocking requests until they recover.
- Rate Limiting: Controls how often users can access resources within a specified timeframe to prevent abuse or overload.
- Downgrading: Provides fallback mechanisms when certain features are unavailable or degraded due to failures.
- Avalanche Effect: Occurs when multiple dependent services fail simultaneously due to cascading failures from one service’s downtime.
What Open Source Frameworks Do You Know for Circuit Breaking and Downgrading?
Notable open-source frameworks include:
- Hystrix: A circuit breaker library from Netflix designed for fault tolerance in distributed systems.
- Resilience4j: A lightweight alternative for Java applications providing circuit breaking capabilities.
- Sentinel: An open-source project from Alibaba that provides circuit breaking and rate limiting features.
What Are the Differences Between Docker and Virtual Machines?
| Feature | Docker | Virtual Machine |
|---|---|---|
| Operating System | Shares host OS kernel | Requires separate OS per VM |
| Performance | Lightweight with faster startup times | Heavier due to full OS overhead |
| Portability | Highly portable across environments | Less portable due to size |
| Resource Usage | More efficient resource utilization | Consumes more resources |
What Problems Does Service Mesh Solve?
Service mesh addresses challenges in microservices architectures such as:
- Service discovery
- Load balancing
- Traffic management
- Security (e.g., authentication)
- Observability (e.g., monitoring and tracing)
By abstracting these concerns away from application code, service mesh allows developers to focus on business logic while ensuring robust inter-service communication.
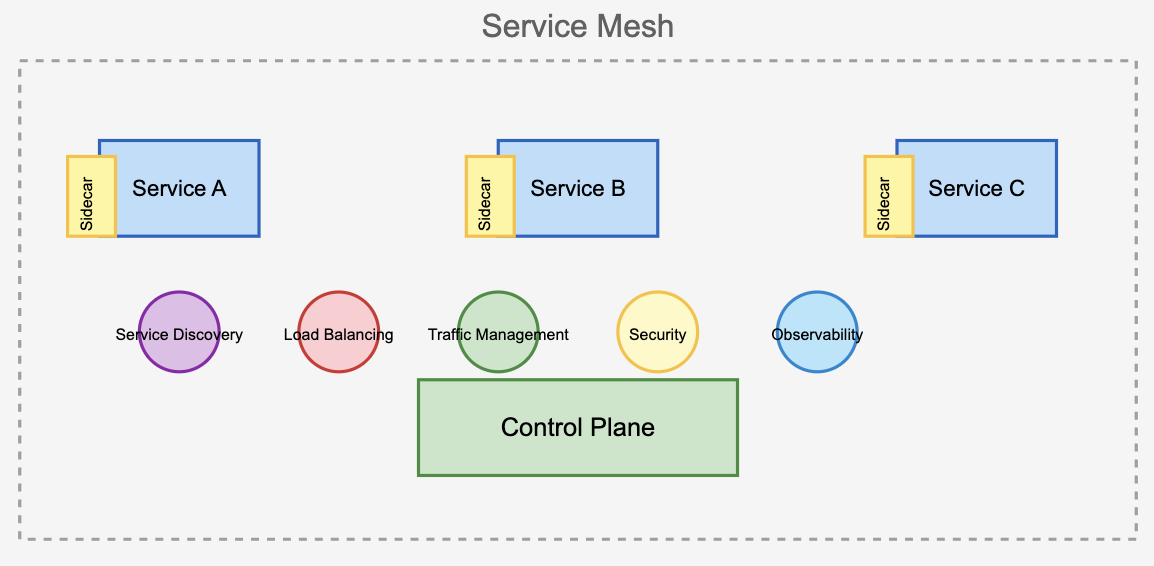
How does a service mesh work?
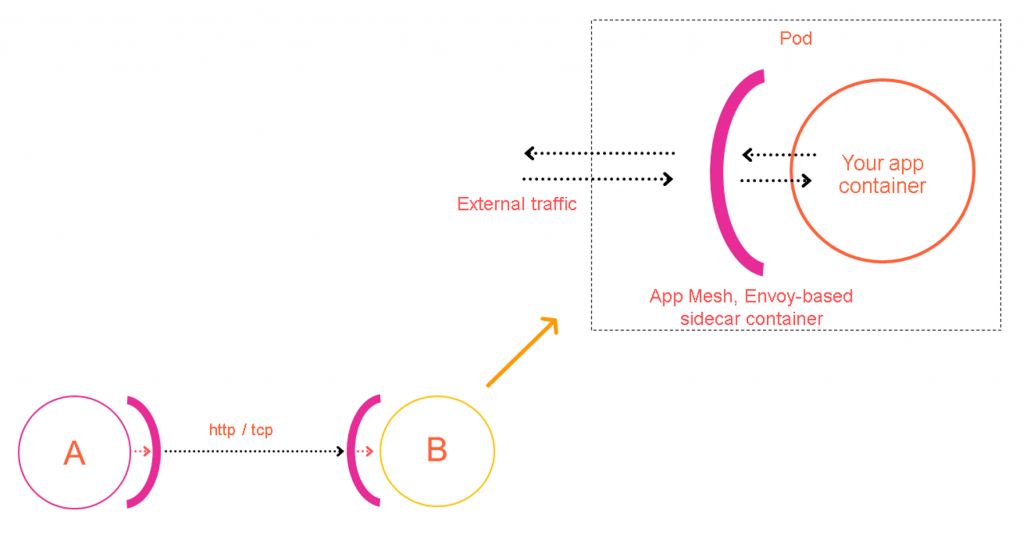
A service mesh simplifies inter-service communication in a microservices architecture by abstracting it into a dedicated infrastructure layer. This layer uses network proxies, often called sidecars, deployed alongside each service. All traffic flows through these proxies.
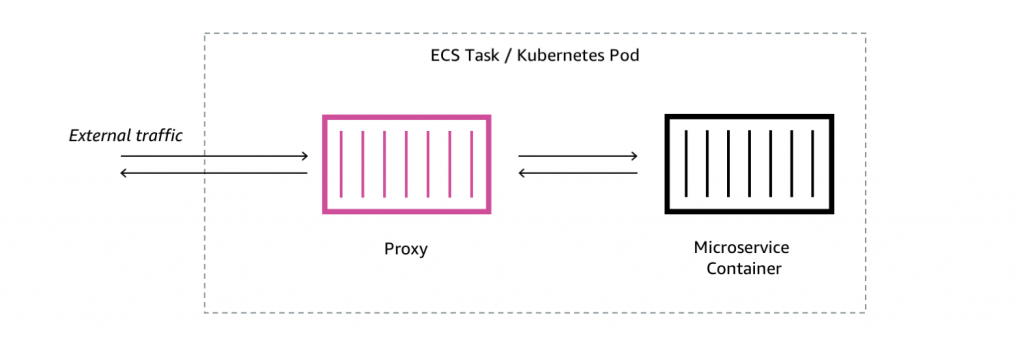
The mesh comprises two key components:
Data Plane: This consists of the sidecar proxies. They intercept requests, establish secure connections, and handle low-level messaging, including features like circuit breaking and retries. Core functionality such as load balancing, service discovery, and routing resides here.
Control Plane: This acts as the central management layer. Administrators use it to define and configure services, including endpoints, routing rules, load balancing, and security settings. The control plane distributes this configuration to the data plane proxies, allowing for dynamic adjustments without service restarts. It typically includes a service registry, automatic service discovery, and telemetry data collection.
What Technologies Are Related to DevOps?
Key technologies related to DevOps include:
- Version Control Systems: Git, SVN
- Continuous Integration/Continuous Deployment (CI/CD): Jenkins, GitLab CI
- Containerization: Docker, Kubernetes
- Configuration Management Tools: Ansible, Puppet
- Monitoring Tools: Prometheus, Grafana
- Infrastructure as Code (IaC): Terraform
What is microservices architecture?
Microservices architecture is an approach to developing a single application as a suite of small, independently deployable services. Each service runs in its own process and communicates with lightweight mechanisms, often HTTP-based APIs.
What is serverless computing?
Serverless computing is a cloud computing model where the cloud provider manages the infrastructure, automatically provisioning and scaling servers as needed. Developers focus on writing code in the form of functions, which are executed in response to events.
What are the main HTTP methods used in RESTful APIs?
- GET: Retrieve a resource
- POST: Create a new resource
- PUT: Update an existing resource
- DELETE: Remove a resource
- PATCH: Partially modify a resource
What is OAuth and how does it work?
OAuth is an open standard for access delegation. It allows users to grant third-party applications access to their resources without sharing their credentials. It works by issuing access tokens to third-party clients with the approval of the resource owner.
What is CORS and why is it important?
CORS (Cross-Origin Resource Sharing) is a security mechanism that allows a web page from one domain to request resources from another domain. It’s important for enabling secure cross-origin data transfers in web applications.
What is SQL injection and how can it be prevented?
SQL injection is a code injection technique used to attack data-driven applications. It can be prevented by using parameterized queries, prepared statements, and input validation.
What is horizontal scaling vs vertical scaling?
- Horizontal scaling (scaling out): Adding more machines to a system
- Vertical scaling (scaling up): Adding more power (CPU, RAM) to an existing machine
Explain the concept of Infrastructure as Code (IaC).
Infrastructure as Code is the practice of managing and provisioning computing infrastructure through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools.
Example: Configuring a Network using Ansible
Ansible is another popular IaC tool, often used for configuration management. This example shows how Ansible can configure a network device (e.g., a router) using a playbook.
Explain the CAP theorem.
The CAP theorem states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
- Consistency
- Availability
- Partition tolerance
What is Blue/Green Deployments
Blue/Green Deployment is a way to update software with almost no downtime:
- You have two identical environments: Blue and Green.
- Blue is currently live and serving users.
- You update the Green environment with the new version.
- You test Green to make sure it works correctly.
- You quickly switch all user traffic from Blue to Green.
- Green is now live, and Blue becomes idle.
If something goes wrong, you can easily switch back to Blue.
This method reduces risks and makes it easy to roll back if needed, but it does require more server resources.
What tools can be used for data collection?
ELK Stack (Elasticsearch, Logstash, Kibana):
- Logstash is a powerful data collection component.
- It can collect data from various sources and send it to Elasticsearch for search and analysis.
Filebeat:
- A lightweight tool for reading data from log files.
- Particularly suitable for collecting log data already written to files.
- Can send data to Logstash or Elasticsearch for processing.
Fluentd:
- An open-source data collector.
- Supports functionality extension through plugins.
- Can collect data from multiple sources and forward it.
Apache Kafka:
- While primarily used for stream data processing, its Producer API can be used for data collection.
- Suitable for high-throughput data processing.
- Combined with Kafka Streams or other consumer applications, it can implement powerful real-time data processing systems.
What are the key principles of BI (Business Intelligence) data reporting?
Data Collection:
- Frontend, backend, Database transactions
Data Transmission:
- Real-time transmission: Using WebSocket or HTTP requests to send data immediately.
- Batch transmission: Sending collected data periodically to reduce network overhead.
Data Reception:
- API endpoints: Providing interfaces to receive reported data.
- Message queues: Using middleware like Kafka to receive data.
Data Processing:
- Data cleansing: Removing invalid or duplicate data.
- Data transformation: Converting raw data into formats suitable for analysis.
- Data aggregation: Summarizing data to generate statistical information.
Data Storage:
- Data warehouses: Using systems like Hive or Snowflake to store large volumes of structured data.
- Time-series databases: Employing databases like InfluxDB for time-series data.
Data Analysis:
- OLAP analysis: Using tools like Druid for multi-dimensional data analysis.
- Machine learning: Applying algorithms to discover patterns and trends in data.
Data Visualization:
- Dashboards: Creating intuitive data presentation interfaces using tools like Tableau or PowerBI.
- Report generation: Automatically generating periodic reports.
Data Security:
- Encryption: Protecting sensitive data in transit and at rest.
- Access control: Ensuring only authorized personnel can access the data.
Data Governance:
- Metadata management: Maintaining descriptive information about the data.
- Data quality control: Ensuring data accuracy and consistency.
Certainly! I’ll organize the information into an English markdown table format and include the question at the top.
What are the differences between Cookies, Sessions, and Tokens?
| Feature | Cookie | Session | Token |
|---|---|---|---|
| Storage Location | Client-side (browser) | Server-side | Client-side (usually localStorage or sessionStorage) |
| Main Purpose | Store small amounts of data on client, remember user preferences or login status | Store user session-related information | Authentication and authorization, especially in stateless APIs |
| Security | Relatively low, can be modified or stolen by client | Higher, data stored on server, client only keeps session ID | Higher, can contain encrypted information, not easily tampered with |
| Expiration | Can set expiration time, supports long-term storage | Usually short-lived, expires on user logout or inactivity | Flexible, can be set for short-term or long-term validity |
| Cross-domain Support | Not supported by default | Not supported | Supported |
| Scalability | Limited in distributed systems | Challenges in distributed systems | Well-suited for distributed systems and microservices |
| State | Stateful | Stateful | Stateless |
| Size Limit | Limited (usually 4KB) | Depends on server configuration | Can be larger, but should be kept small for efficiency |
| Vulnerability to XSS | Vulnerable if not secured properly | Less vulnerable (if cookie-based sessions are properly secured) | Less vulnerable, but still needs proper handling |
| Implementation Complexity | Simple | Moderate | Can be complex, especially with refresh tokens |
What are the main differences between single token and double token authentication?
| Feature | Single Token | Double Token |
|---|---|---|
| Structure | Uses one token for authentication | Uses two tokens: access token and refresh token |
| Token Types | Typically just an access token | Access token (short-lived) and refresh token (long-lived) |
| Lifespan | Usually longer-lived to reduce frequent logins | Access token is short-lived, refresh token is long-lived |
| Security | Potentially less secure if compromised | More secure, access tokens expire quickly, refresh tokens can be invalidated |
| User Experience | May require more frequent logins if kept short-lived | Provides seamless re-authentication without user intervention |
| Revocation | Requires blacklisting or waiting for expiration | Can revoke refresh tokens to log out users across all devices |
| Implementation Complexity | Simpler to implement | More complex, requires managing two types of tokens |
| API Calls | Every API call uses the same token | Uses access token for API calls, refresh token only for getting new access tokens |
| Storage | Typically stored in local storage or session storage | Access token in memory, refresh token in secure HTTP-only cookie or secure storage |