本质上,重构就是在代码写完之后改进其设计。
如果你想给程序添加一个功能,但发现由于结构不佳导致代码不易修改,那么应该先重构,让它更容易加功能,然后再加功能。
正是需求的变化使得重构变得必要。
重构的技巧是以极小的步幅修改程序。一旦出错,也更容易被发现。
好代码的检验标准:它有多容易被修改。
总结:
高效且有条理的重构关键点是:小步快跑、让代码始终处于可工作的状态、微小改动最终会累积成更好的系统设计。重构不是“银弹”,更像“银钳子”——它能帮助你始终牢牢控制住代码。重构是一种工具。
1. 代码中的坏味道(Bad Smells)
1. 神秘命名(Mysterious Name)
计算机科学只有两件难事:缓存失效(cache invalidation) 以及命名(naming things)—— Phil Karlton
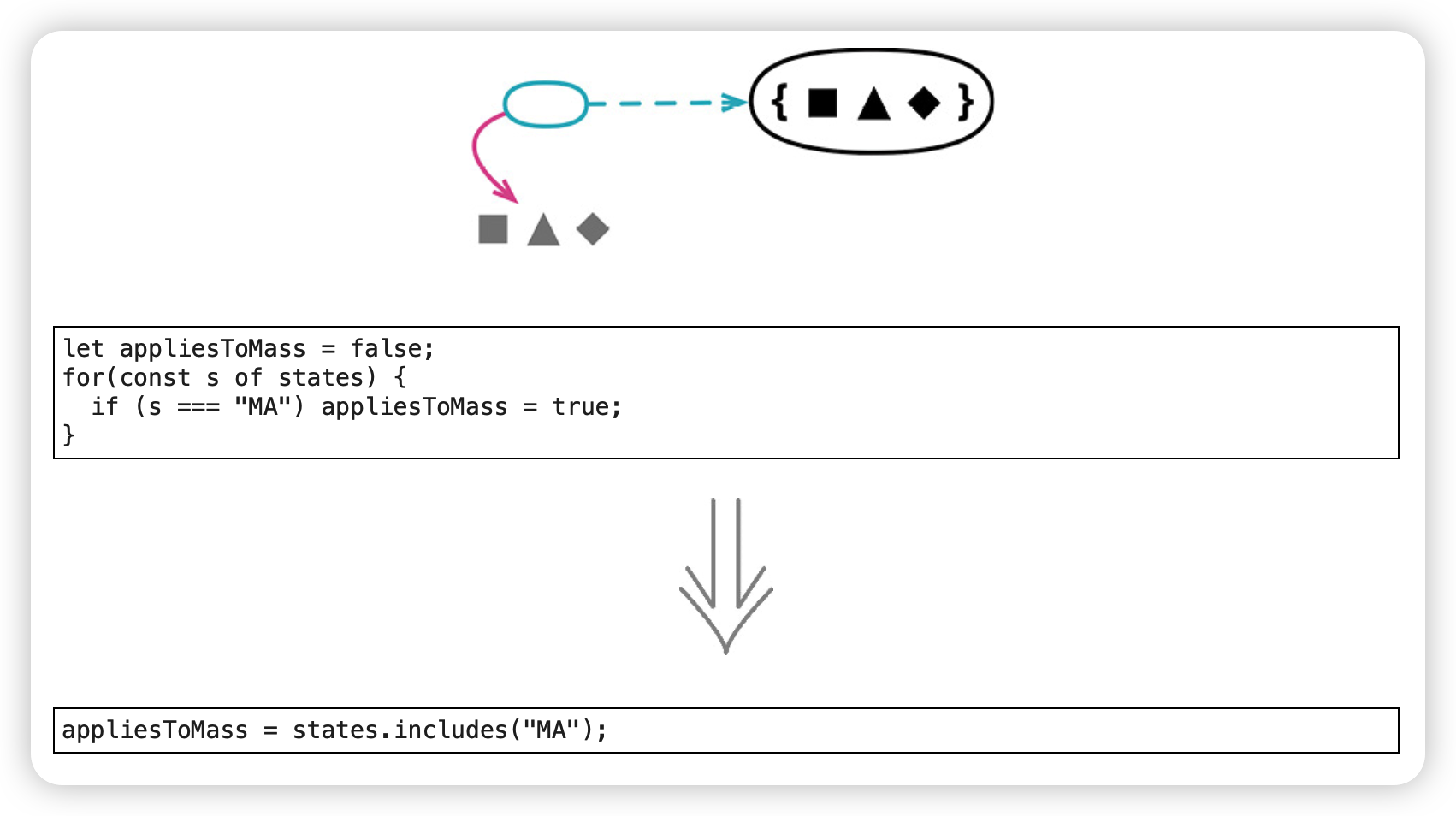
命名是编程中最难的两件事之一。因此,重命名大概也是最常用的重构手法:包括修改函数声明(用于重命名函数)、重命名变量、重命名字段。
2. 全局数据(Global Data)
封装变量(Wrapped Variables)。少量全局数据未必有害,但数量越多,处理起来的难度往往呈指数级上升。
3. 可变数据(Mutable Data)
封装变量可以确保所有数据更新操作都通过很少的几个函数完成,从而更易监控与演进。
如果一个变量在不同时间存放不同含义的东西,可以用“拆分变量(Split Variable)”把它拆成各司其职的多个变量,从而避免危险的更新操作。
使用“搬移语句(Move Statements)”与“提炼函数(Extract Function)”,尽量把逻辑从处理更新操作的代码里挪出去,把无副作用的代码与执行数据更新的代码分离开。
在设计 API 时,可以使用 命令-查询分离(Command-Query Separation, CQS) 来分离查询函数与修改函数。
尽早使用 移除设值函数(Remove Setting Method / Remove set-value functions) 来缩小变量的作用域。
4. 过长函数(Long Functions)
主动分解函数。
原则:每当我们觉得需要用注释解释某段代码时,就把需要解释的内容提炼成一个独立函数,并按“目的”命名(而不是按实现方式命名)。
什么样的函数算太长?超过 50 行?超过 70 行?关键不在于行数,而在于函数的“做什么(what)”与“怎么做(how)”之间的语义距离有多远。
如何判断应该提炼哪段代码?一个好技巧是去找注释:注释往往提示了“做什么”与“怎么做”的语义距离。
条件表达式和循环也常常是需要提炼的信号。 条件表达式可以通过分解条件(Extract/Decompose Conditional)来处理。
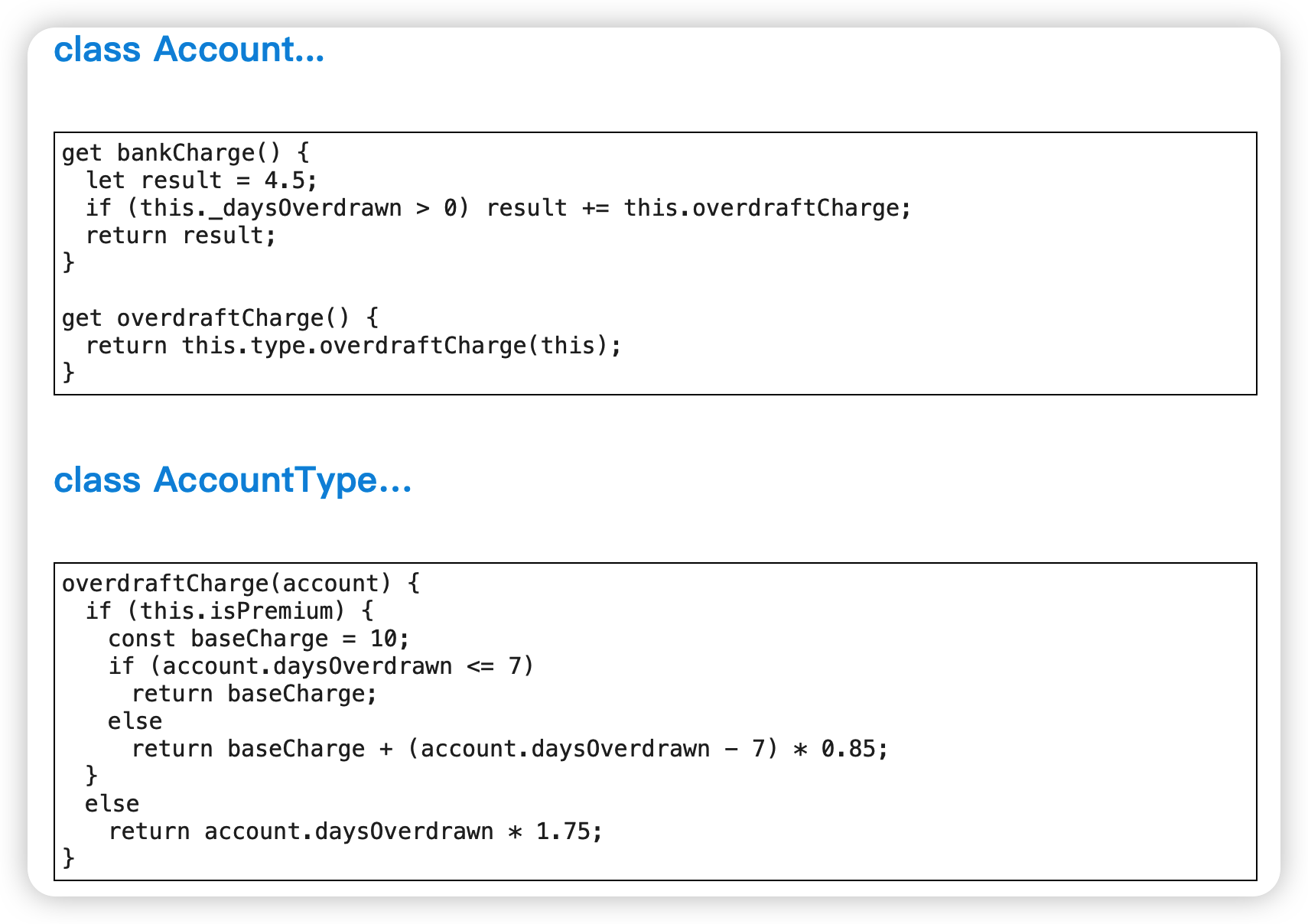
对于巨大的 switch,每个分支都应该通过提炼函数变成一次独立的函数调用。 如果存在多个 switch 都基于同一个条件进行分支选择,应考虑用多态替换条件表达式(Replace Conditional with Polymorphism)。
循环以及循环内部的代码也应该被提炼成独立函数。 如果你发现提炼后的循环难以命名,可能是因为它同时做了多件事;这时就该果断使用拆分循环(Split Loop),把不同任务拆开。
5. 过长参数列表(Long Parameter List)
如果可以用某个参数发起查询得到另一个参数的值,那么后者就可以通过“以查询取代参数(Replace Parameter with Query)”移除。
如果你发现自己总是从现有数据结构中抽取一堆字段出来传参,考虑使用 保持对象完整(Preserve Whole Object / Keep Objects Intact) 直接传入原始对象。如果有几个参数总是结伴出现,可以通过“引入参数对象(Introduce Parameter Object)”把它们合并成一个对象。
如果某个参数只是用作区分函数行为的旗标(flag),就移除这个旗标参数。
使用类可以有效缩短参数列表。 当多个函数共享同一组参数时,引入一个类尤其合适:把这些共同参数变成该类的字段,然后把相关函数组合进类中。
6. 霰弹式修改(Shotgun Surgery)
如果每次遇到某类变化,你都不得不在许多不同的类里做很多细碎改动,那你面对的坏味道就是霰弹式修改。
搬移函数与搬移字段可以把需要一起修改的代码放到同一个模块中。若有很多函数操作相似的数据,可以用“组合函数成类(Combine Functions into Class)”。若某些函数用于转换或丰富数据结构,可以把它们组合成转换流程。若多个函数的输出可以组合并提供给一段专门使用这些计算结果的逻辑,常常适合使用拆分阶段(Split Phase,例如:先解析订单,再计算订单价格)。
常见策略是先用与“内联(inline)”相关的重构(例如 内联函数(Inline Function) 或内联类)把不该四散的逻辑先“拽回一处”。内联完成后,你可能会闻到“函数过长”或“类过大”的味道,再用提炼相关的重构把它拆成更合理的块。
7. 注释(Comments)
如果你需要注释来解释某段代码在做什么,先尝试提炼函数;如果函数已经提炼了仍需要注释解释其行为,尝试通过“修改函数声明(Change Function Declaration)”重命名;如果你需要注释来解释某个系统需求的规格,考虑引入断言(Introduce Assertion)。
当你觉得需要写注释时,先尝试重构,让注释变得多余。
8. 数据泥团(Data Clumps)
总是一起出现的一组数据,真的应该拥有自己的对象。
9. 重复的 Switch(Repeated Switches)
多态(Polymorphism)。
10. 懒惰元素(Lazy Element)
随着重构推进,一个类可能变得越来越小,最后只剩一个函数。及时移除这个类,改用内联函数或内联类。
11. 被拒绝的遗赠(Refused Bequest)
子类应该继承父类的函数和数据。
如果你不想支持父类的接口,就别假装使用继承体系:用**委托(delegation,组合优于继承)**来替代继承(用组合/委托代替子类化),明确划清边界。
2. 第一组重构手法(First Set of Refactorings)
1. 提炼函数(Extract Function)
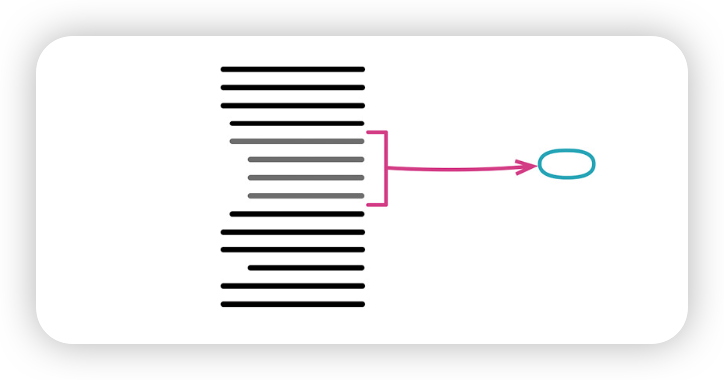

将意图与实现分离(Separate Intent from Implementation):如果你需要花时间浏览一段代码才能搞清楚它到底在做什么,那就把它提炼成一个函数,并根据“它做什么”来命名。因为大多数时候,你不需要关心它是如何实现目的的(那是函数内部的事)。
好名字的一个线索:在大函数里,常见做法是先写注释说明某段代码要做的事,然后把那段代码提炼成函数——而注释本身往往就是一个好名字。
Practice:
创建一个新函数:按“做什么”命名,而不是按“怎么做”命名。
没有局部变量:直接提炼成函数;
有局部变量但只读:作为参数传给目标函数;
局部变量会被赋值:若仅在提炼出的函数中使用,就在该函数中声明;若提炼后还需在外部使用,就将其作为返回值;若需要修改多个变量,考虑返回一个对象,或使用其他重构手法(例如:以查询取代临时变量、拆分变量等)。
2. 内联函数(Inline Function)
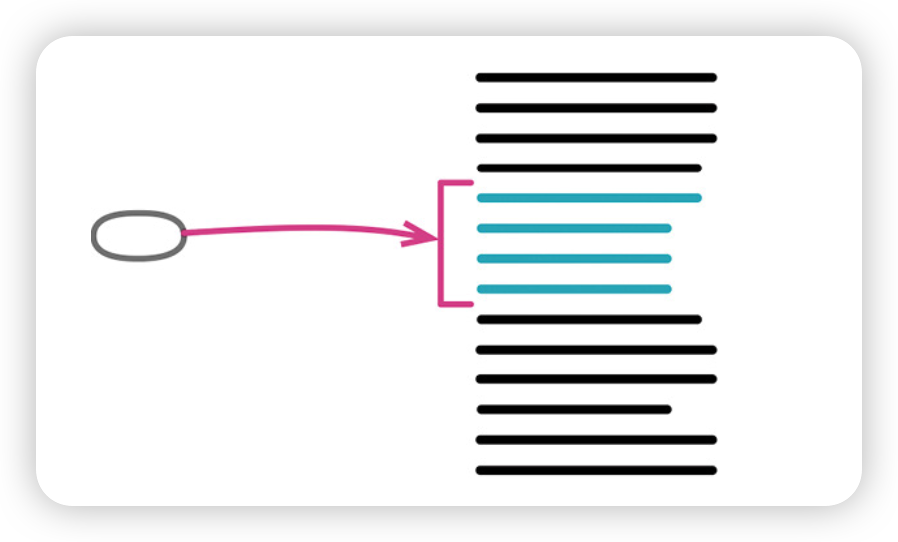

间接层可能有帮助,但不必要的间接层总让人不舒服。
有些函数本身内容和名字都清晰易读,就没必要绕一层。
若一组函数组织得很差,先把它们内联回一个大函数里,再重新提炼整理。
3. 提炼变量(Extract Variable)
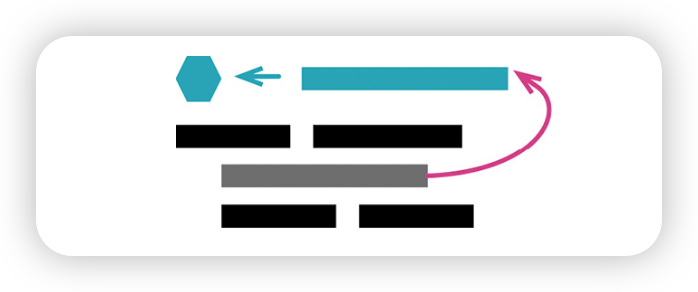
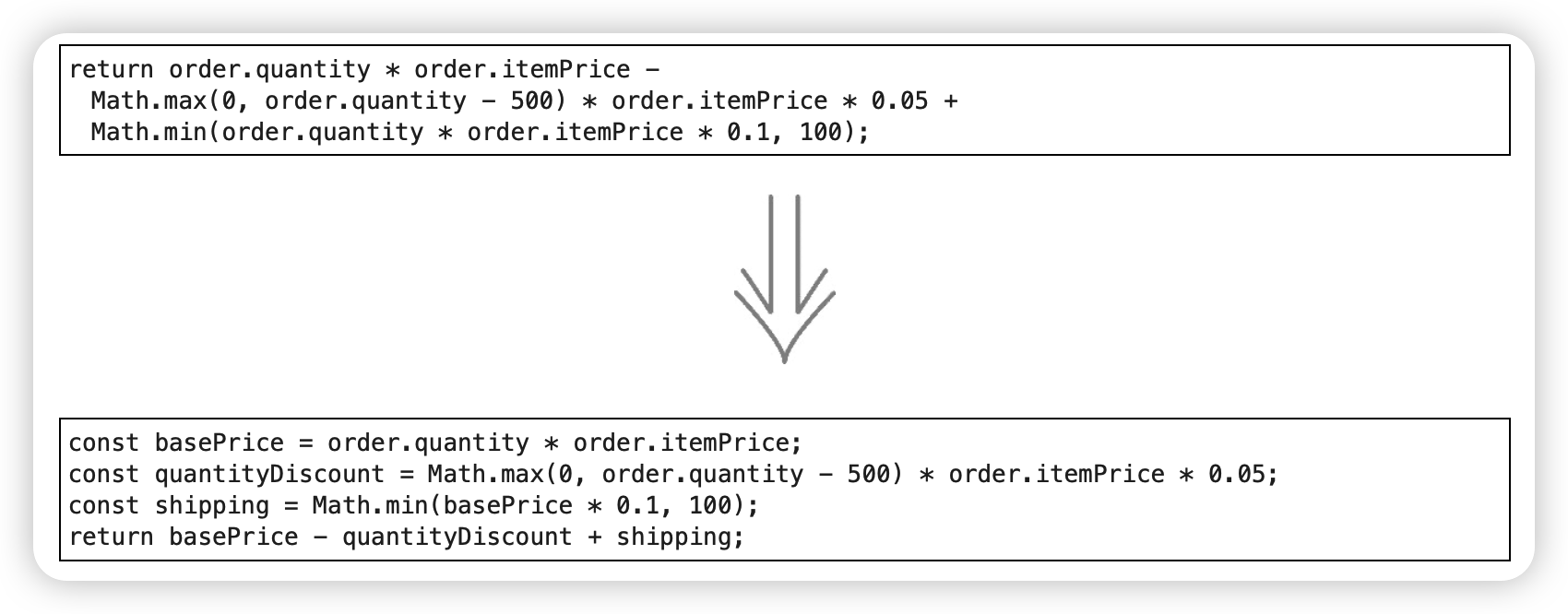
变量提供了合适的上下文:它能把复杂表达式拆成更易管理的形式,也更容易理解某一部分代码在做什么。
《The Tao of Tidy Code》提到:“使用解释性变量,把计算拆成一系列命名良好的中间值。”
4. 内联变量(Inline Variable)
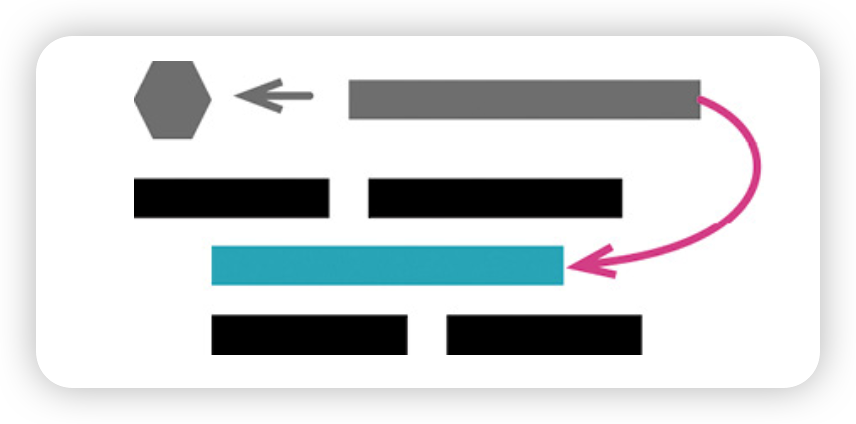
有时,变量名并不比表达式本身更有表现力;也有时变量会妨碍附近代码的重构。
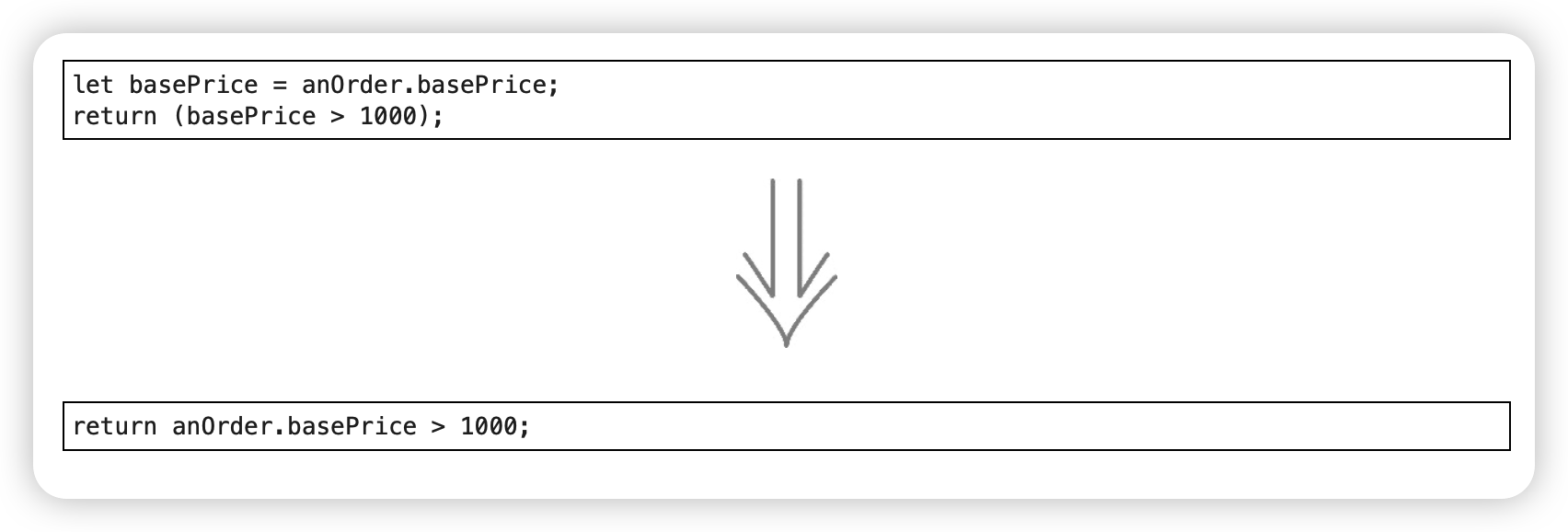
5. 重命名变量(Rename Variable)
变量名应该解释程序在做什么,对作用域超出单次函数调用的字段命名要更谨慎。
6. 修改函数声明(Change Function Declaration)
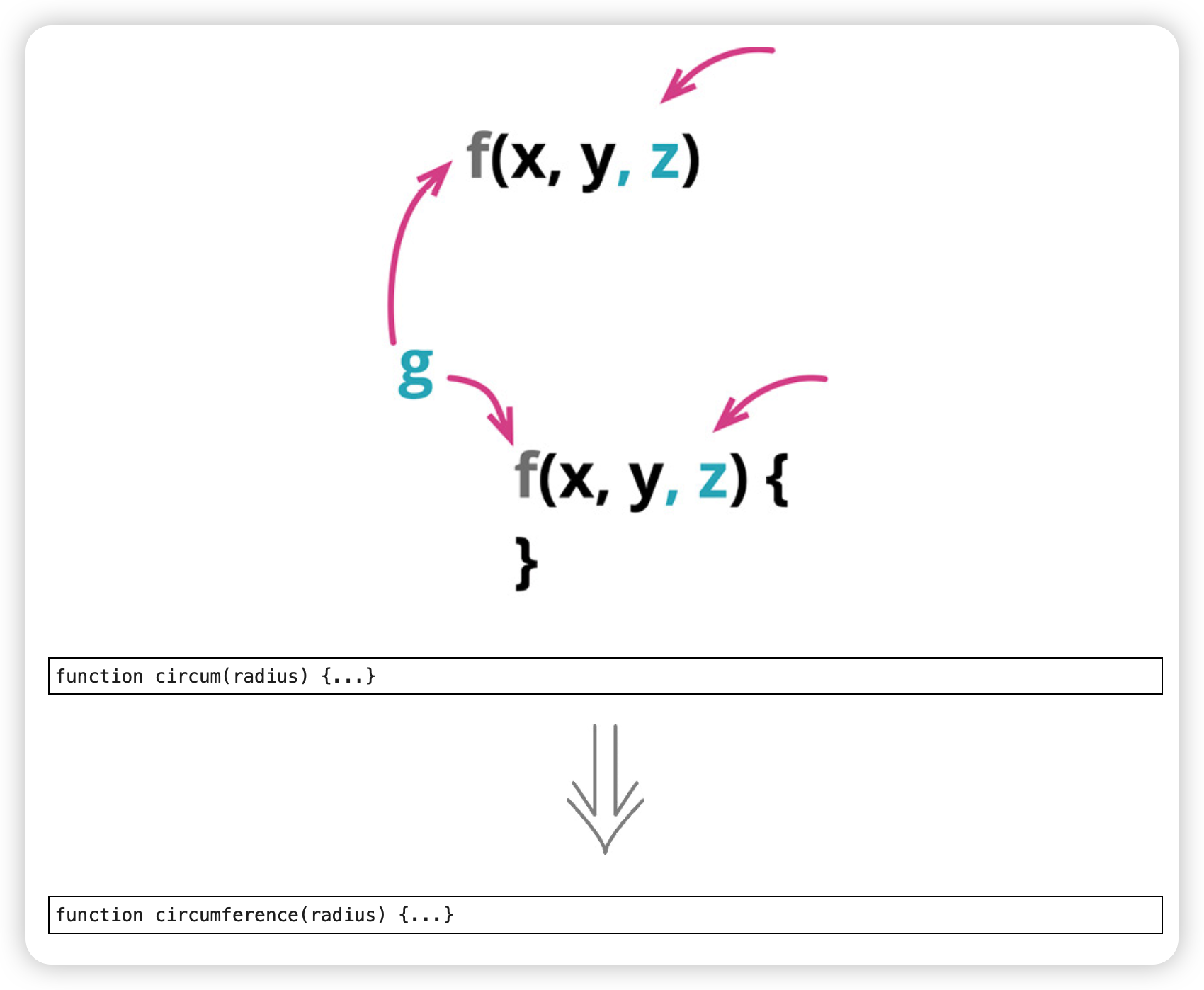
好名字能立刻提示这个函数用来做什么;
函数的参数列表描述了它与外部世界如何共处。调整参数列表不仅能扩大函数适用范围,也能通过改变模块连接所需条件来移除不必要的耦合。
“改进函数名的一个好办法:先写一条注释描述这个函数用来做什么,然后把这条注释变成函数名。”
7. 引入参数对象(Introduce Parameter Object)
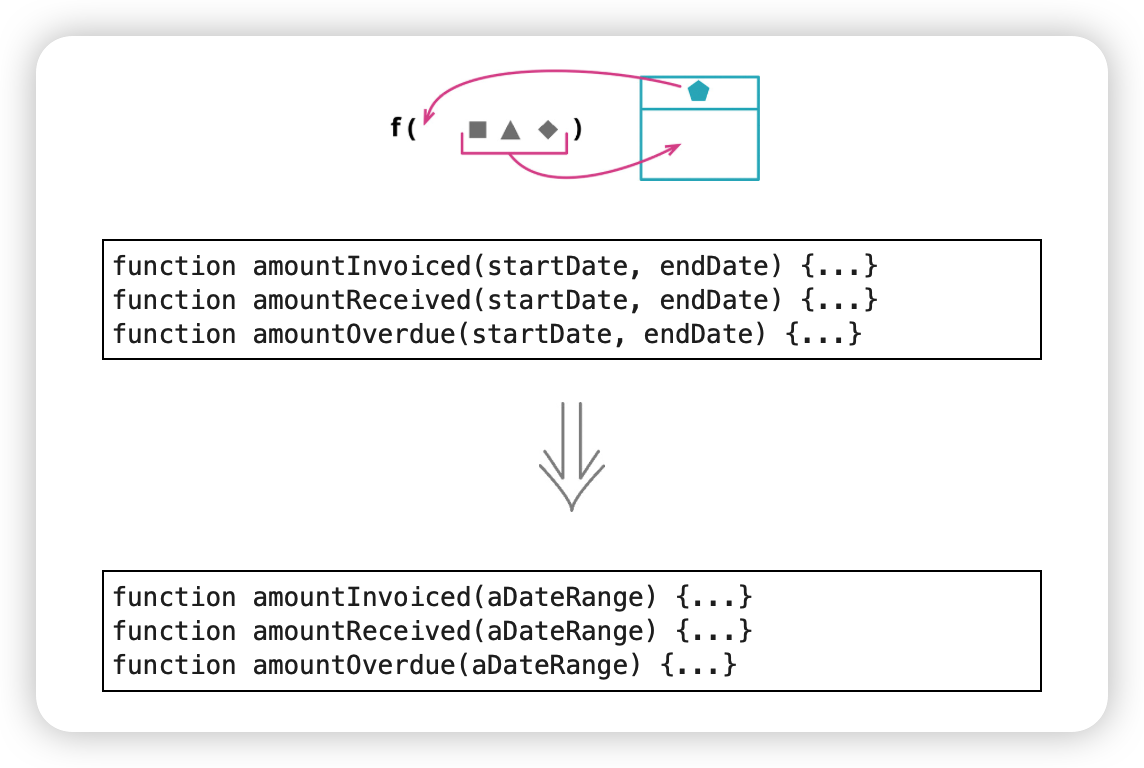
把数据组织成结构,让数据项之间的关系更清晰;
更短的参数列表;
一致性:所有使用该数据结构的函数,都能用同样的名字访问其中元素。
改变代码的概念图景,会把这些数据结构提升为新的抽象。
8. 组合函数成类(Combine Functions into Class)
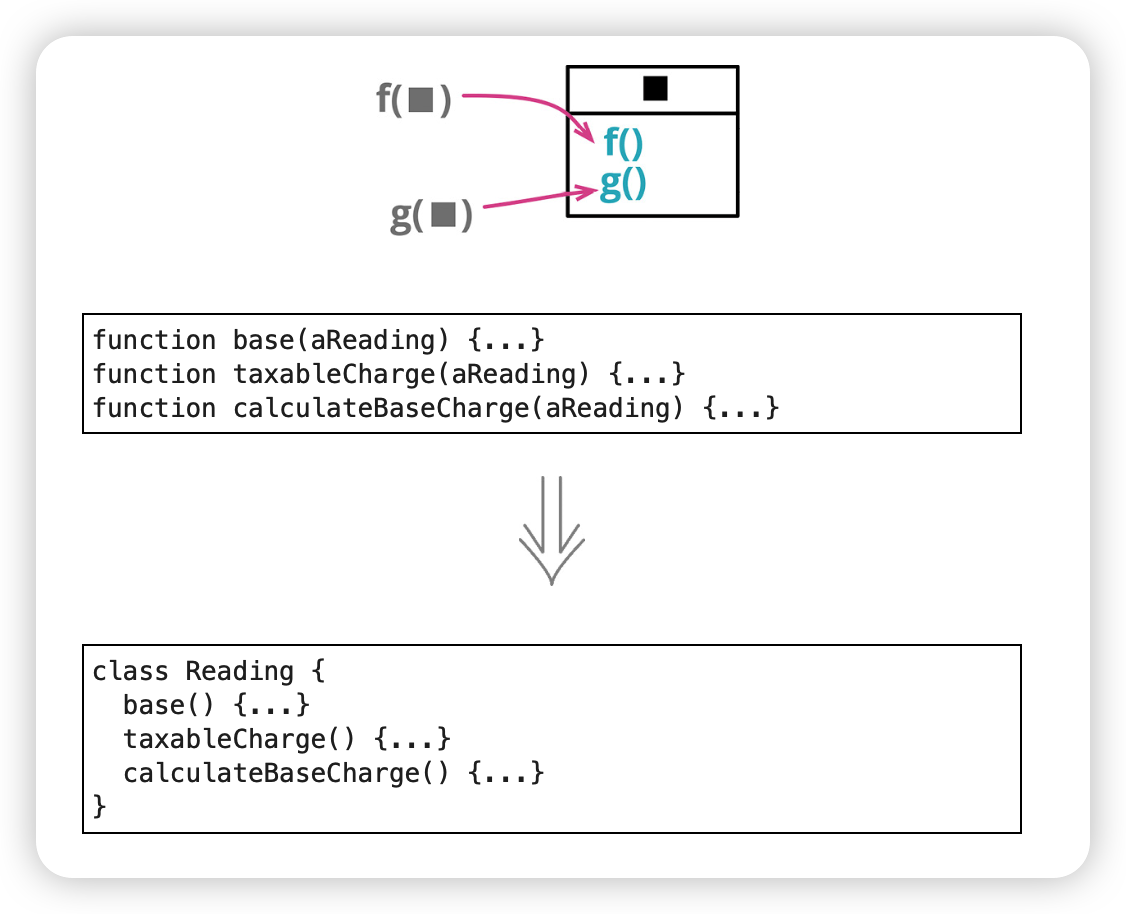
如果你发现一组函数在操纵同一块数据(通常是把那块数据作为参数传入函数),就该把它们组织成一个类了。 类显式提供一个共同环境;从对象内部调用这些函数时,可以通过更少的参数传递来简化调用。
9. 拆分阶段(Split Phase)
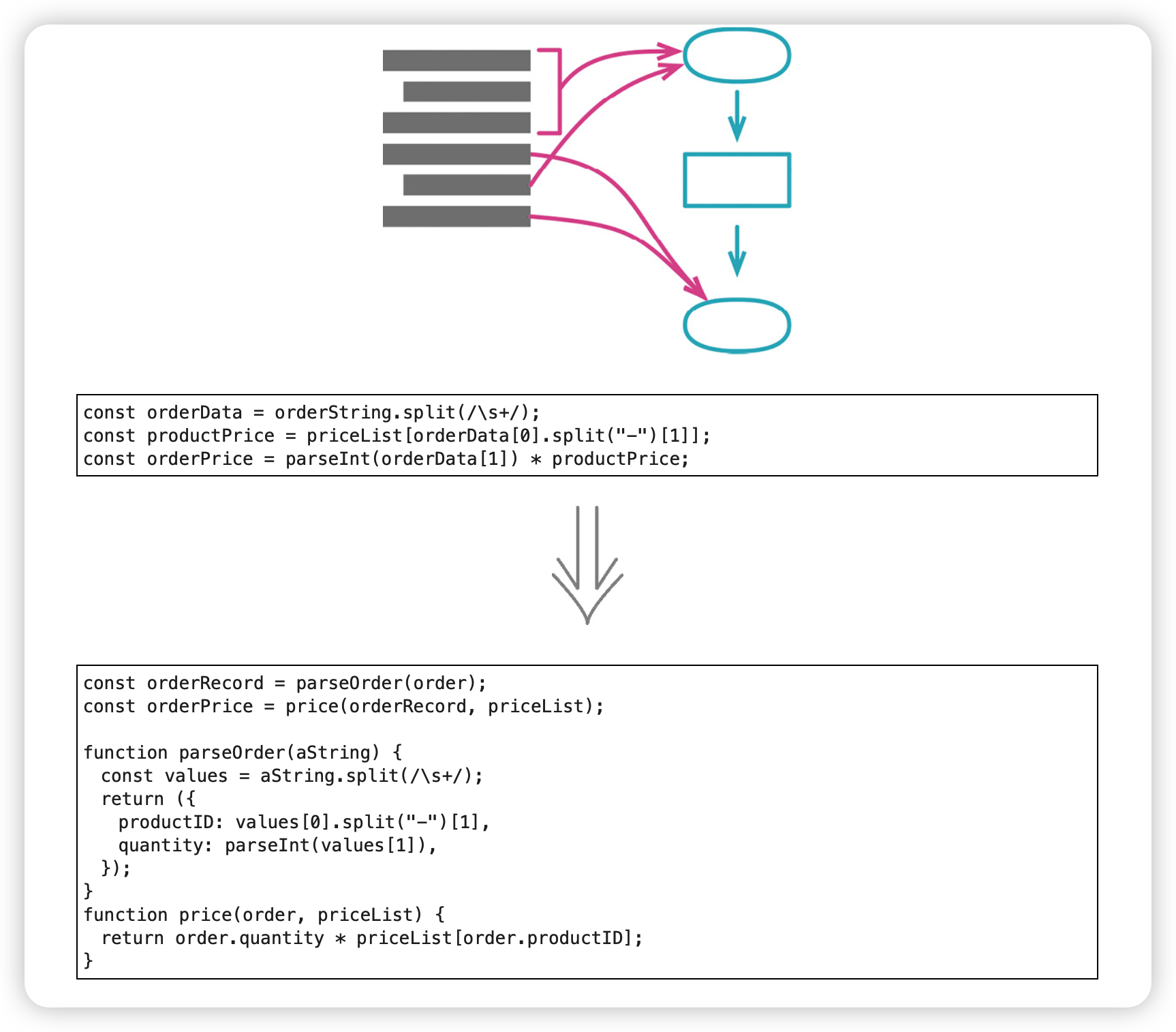
一段代码如果同时处理两件不同的事情,就应该考虑拆分成独立模块:这样在需要改动时,每个主题都能分别处理。
3. 封装(Encapsulate)
1. 封装记录(Encapsulate Record)
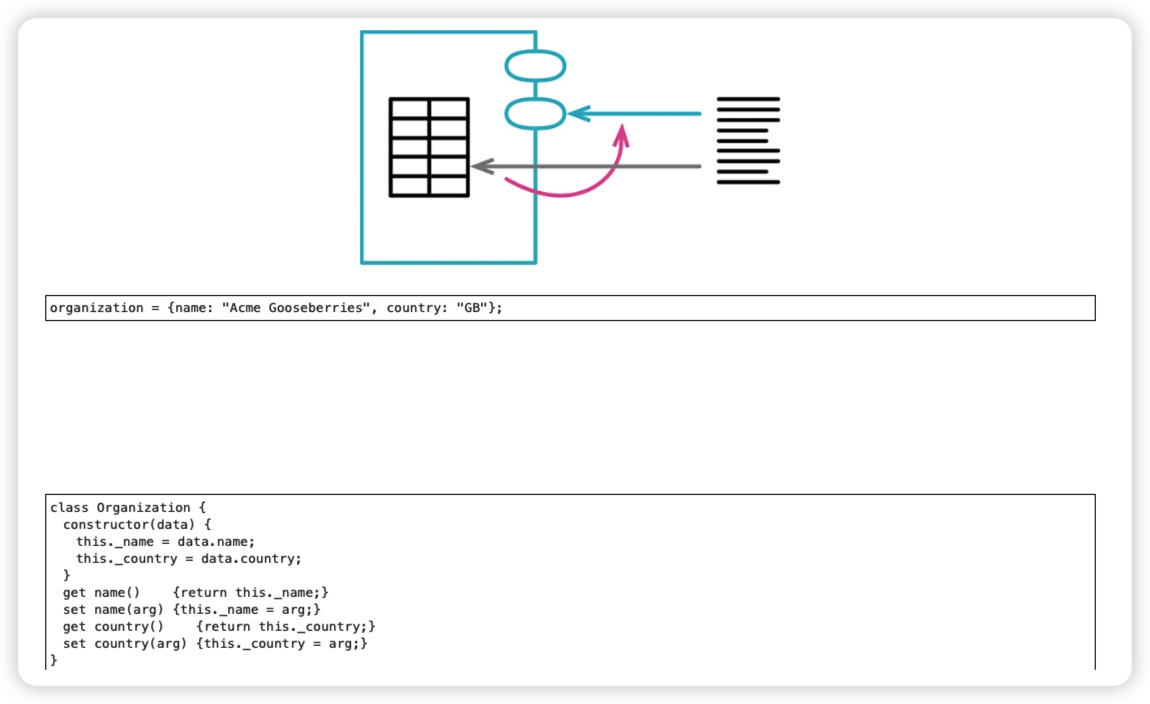
对象可以隐藏结构细节,帮助字段重命名,并且容易扩展以应对变化。
2. 封装变量(Encapsulate Variable)
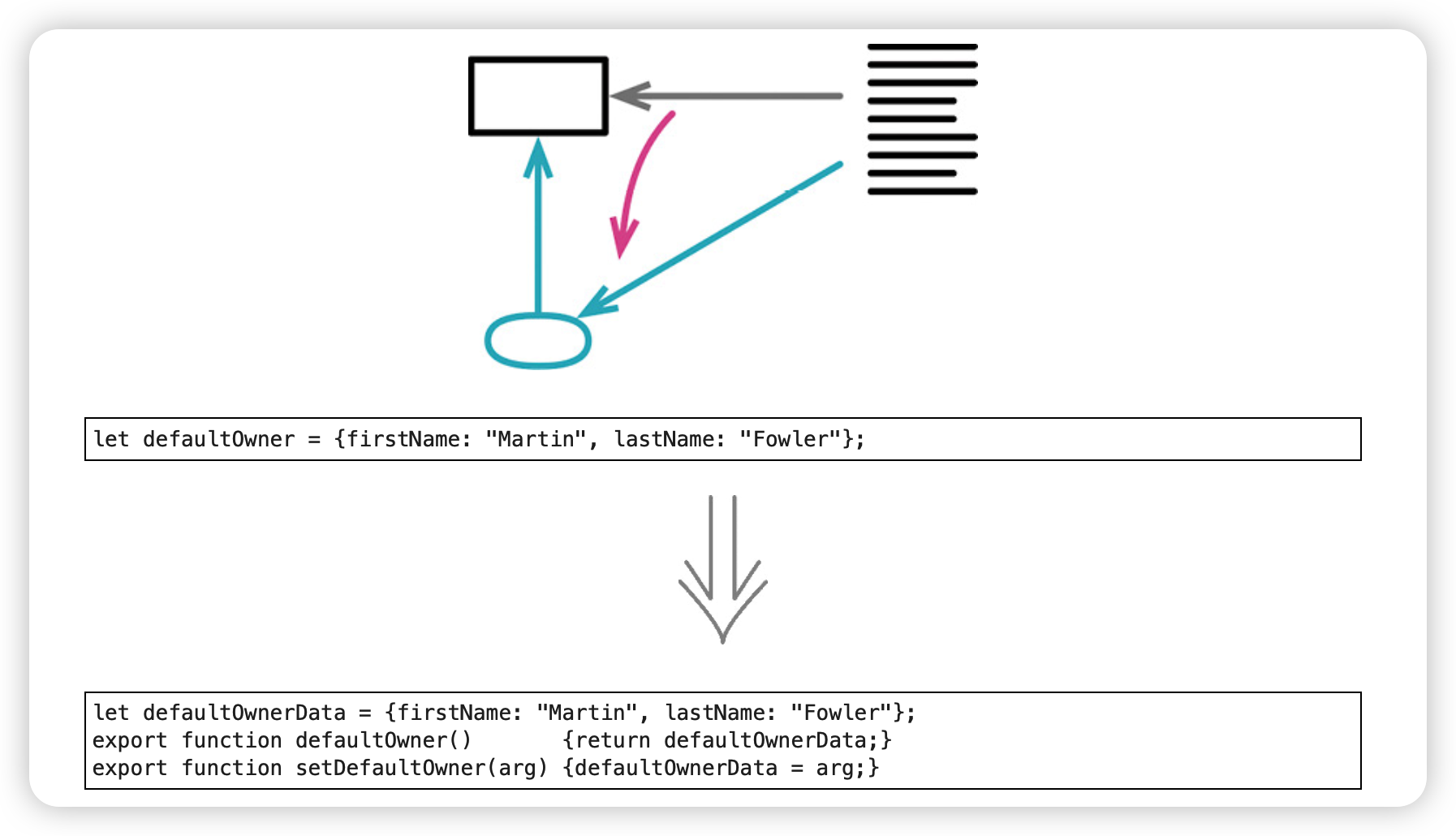
对所有可变数据,只要其作用域超出单个函数,我就会封装它,并且只允许通过函数访问。数据作用域越大,封装就越重要。
3. 封装集合(Encapsulate Collection)
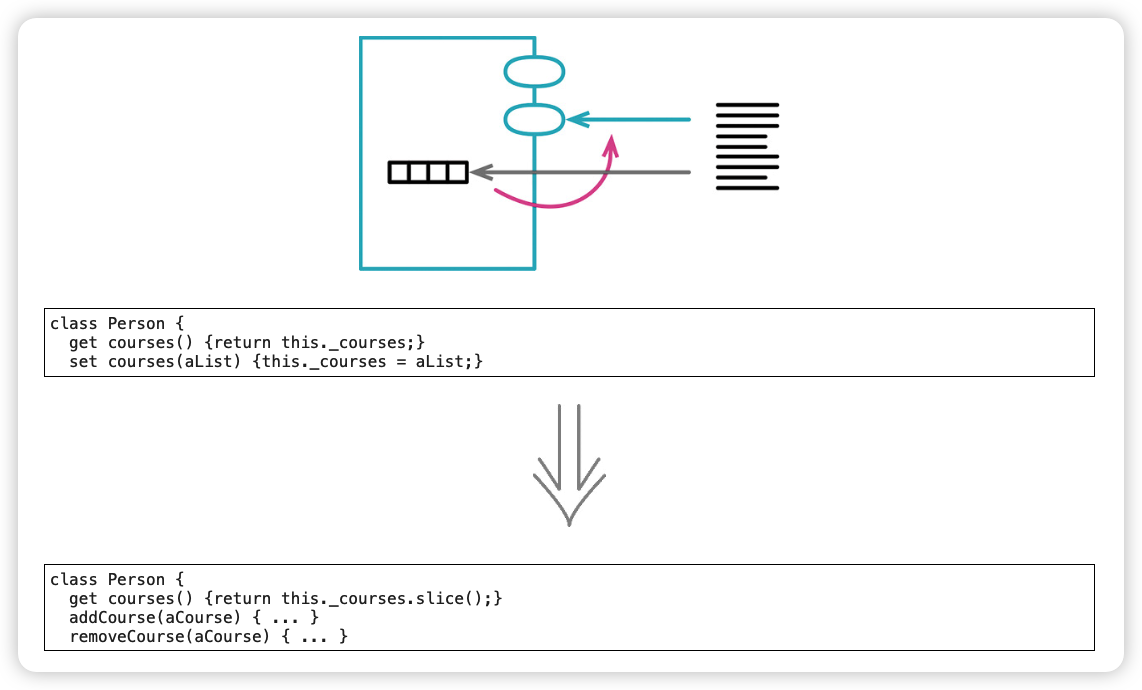
封装集合时,人们常犯的错误是:只封装了对集合变量的访问,却仍让获取函数返回集合本身。这样集合成员就能被直接修改,而封装它的类却完全不知情、也无法介入。
Practice:
在类上提供修改集合的方法——通常用 “add / remove” 方法来统一管理。
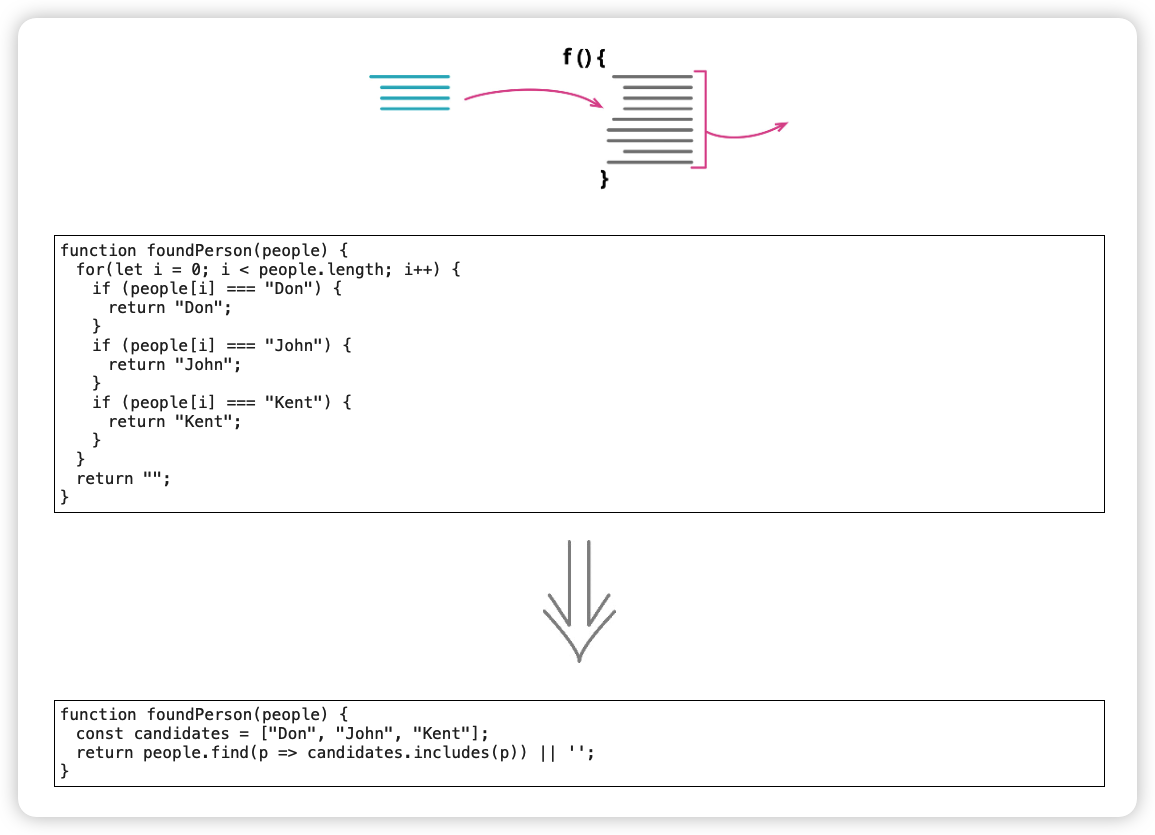
4. 替换算法(Substitute Algorithm)
3. 搬移特性(Move Features)
另一类同样重要的重构是在不同上下文之间搬移元素。
1. 搬移函数(Move Function)
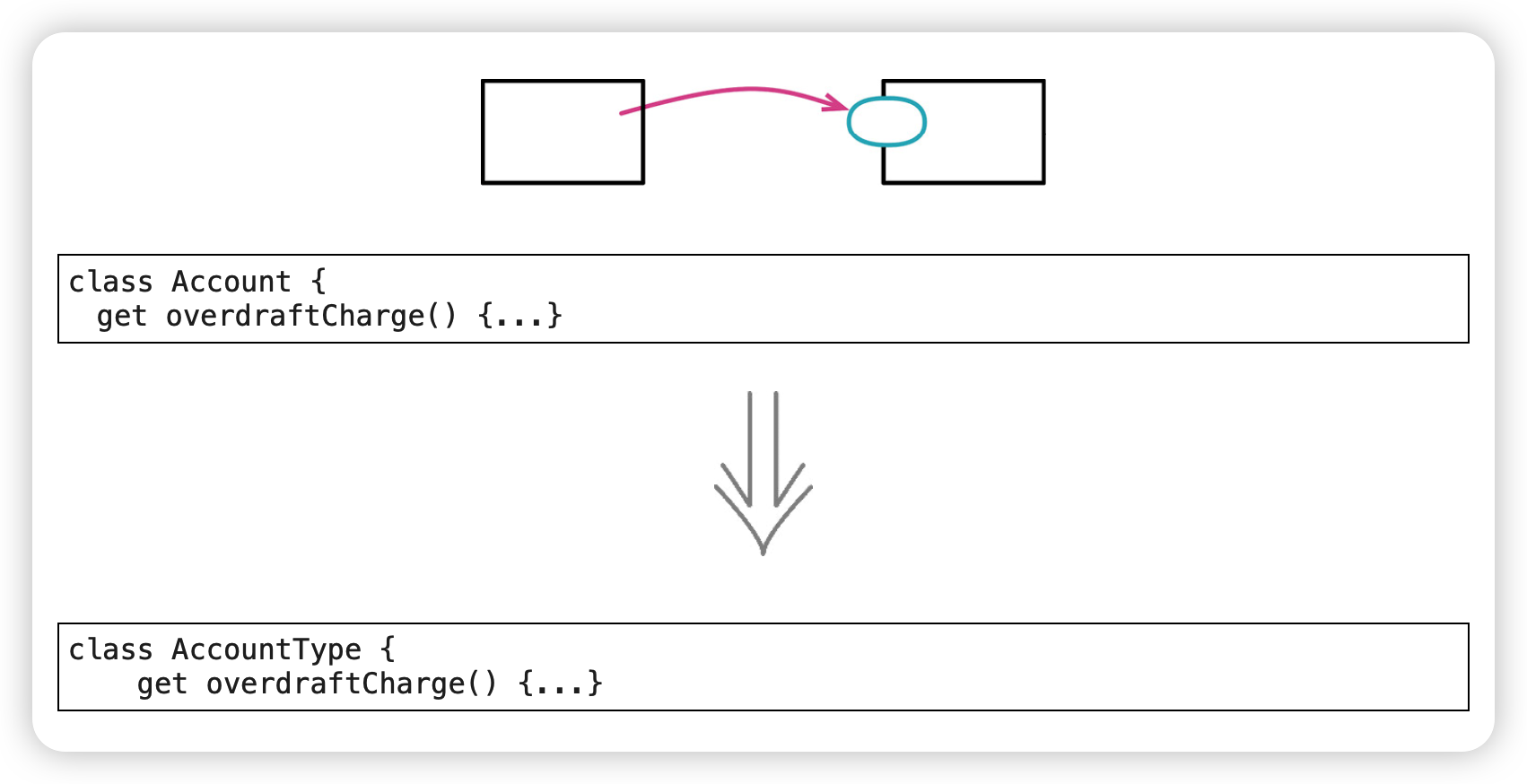
任何函数都需要具备上下文环境才能存活。
搬移函数最直接的一个动因是,它频繁引用其他上下文中的元素,而对自身上下文中的元素却关心甚少,将函数移动到联系更紧密的上下文那么系统别处就可以减少对当前模块的依赖,获得更好的封装效果。
整理代码时,发现需要频繁调用一个别处的函数;或者函数内部定义了一个帮助函数,而该帮助函数可能在别的地方也有用处,此时就可以将它搬移到某些更通用的地方。
是否需要搬移函数常常不易抉择,但决定越难做,通常说明"搬移这个函数与否"的重要性也越低。
范例:搬移内嵌函数至顶层
before:
计算两点之间距离的函数在别处也有调用
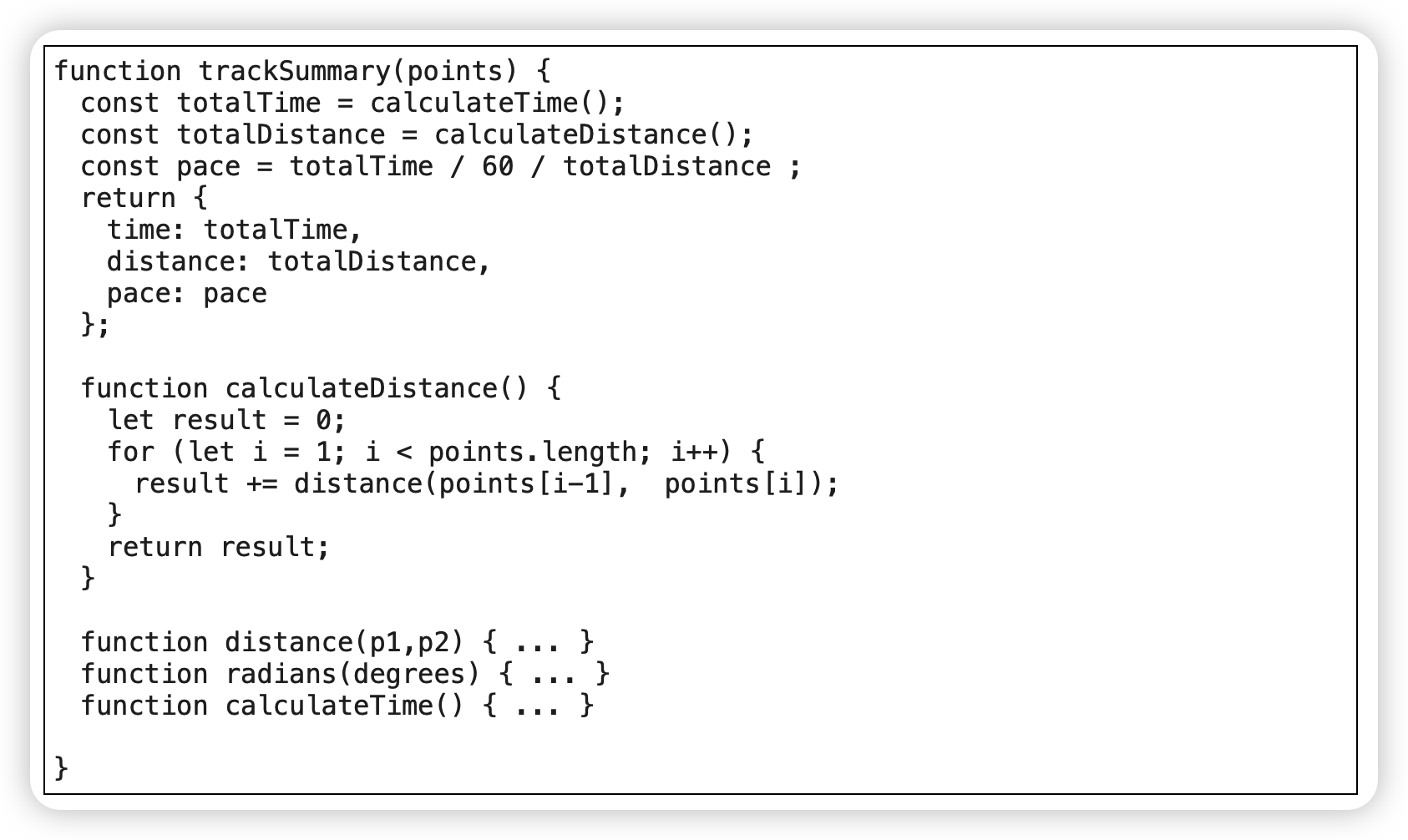
after:

2. 搬移语句到函数(Move Statements into Function)
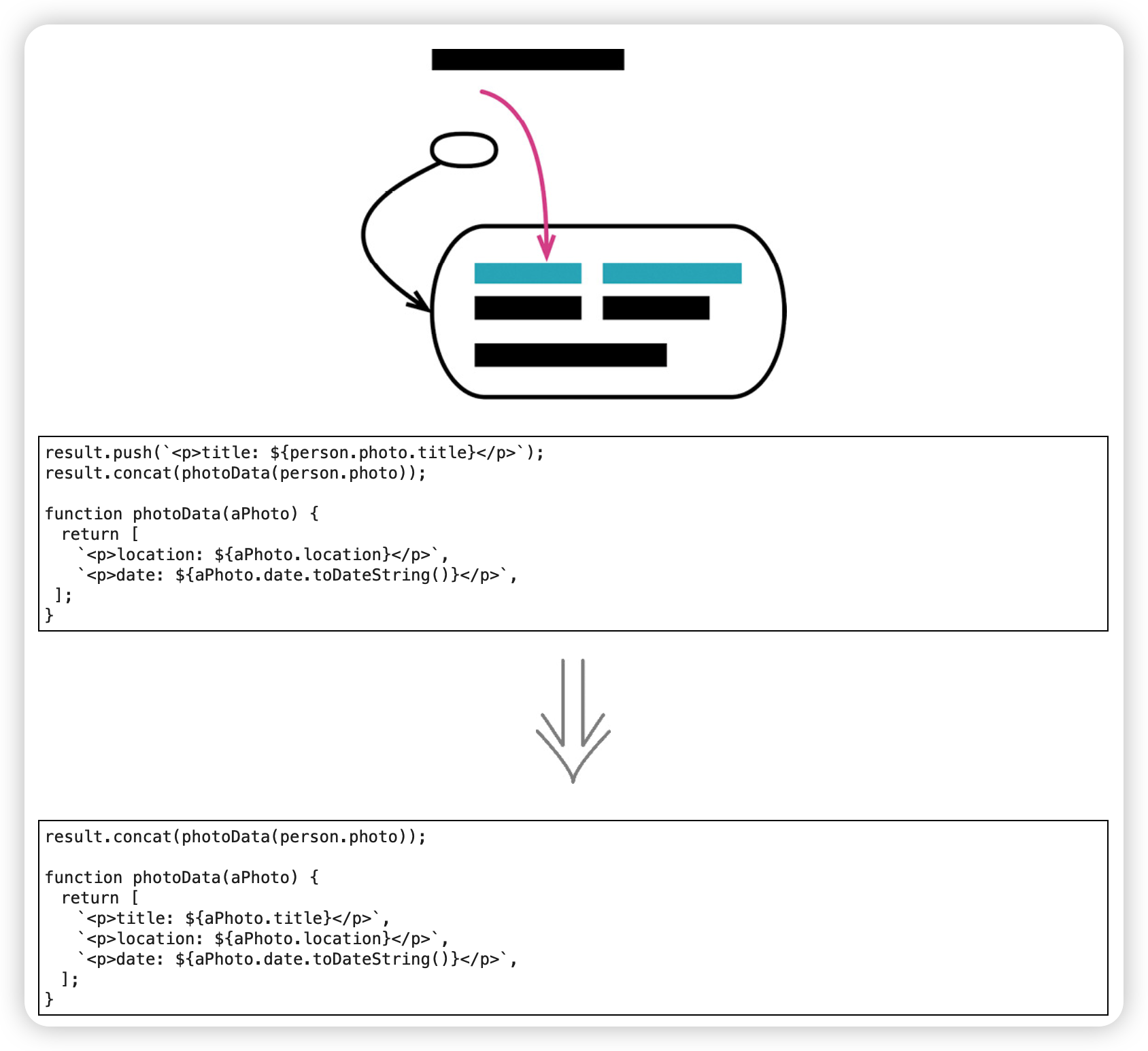
“消除重复”:如果发现调用某个函数时,总有一些相同的代码也需要每次执行,则考虑将此段代码合并到函数里头。
如果某些语句与一个函数放在一起更像一个整体,并且更有助于理解,则将语句搬移到函数里去。如果它们与函数不像一个整体,但仍应与函数一起执行,可以用提炼函数将语句和函数一并提炼出去。
五. 重新组织数据
1. 拆分变量(Split Variable)
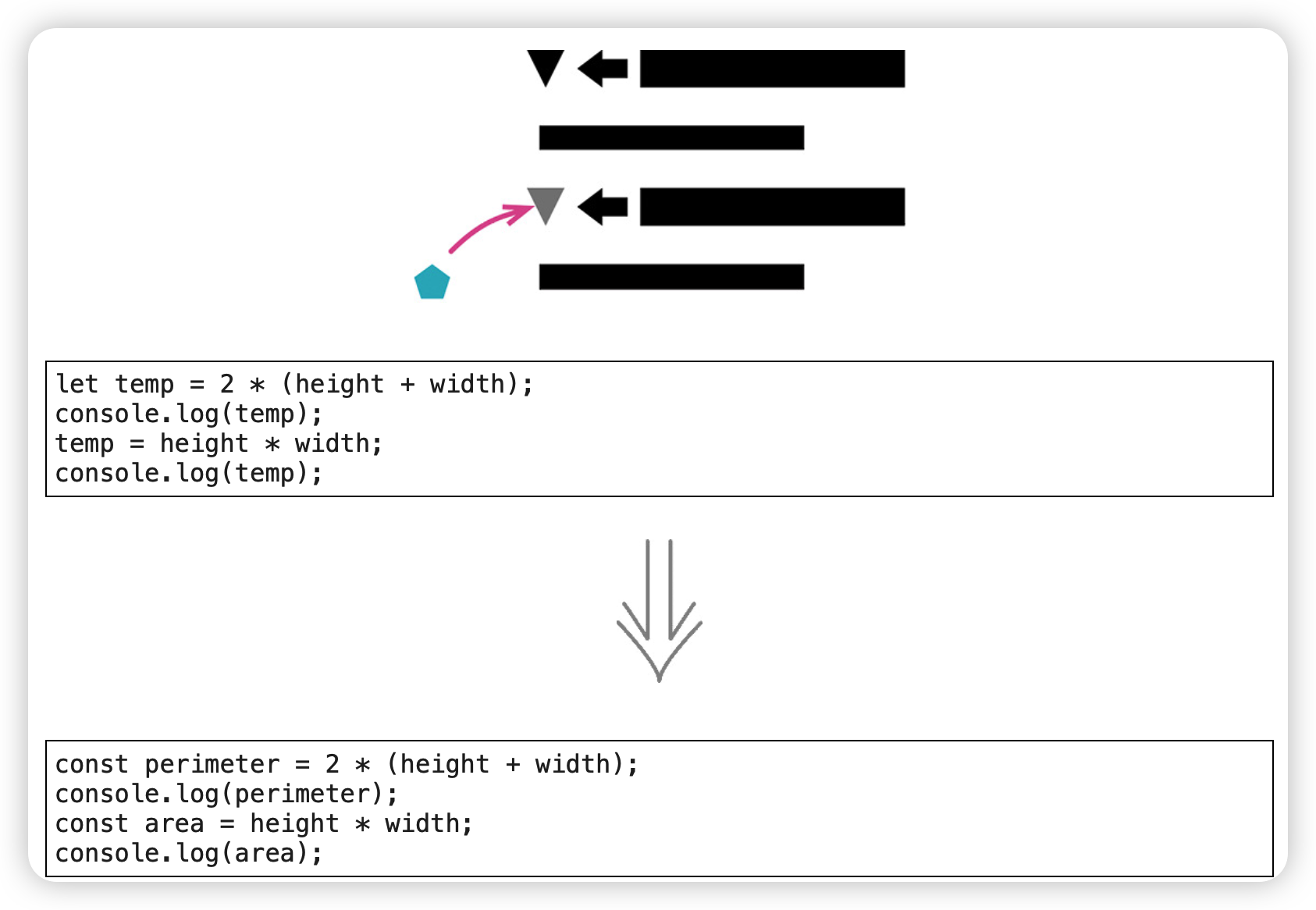
除"循环变量"和"结果收集变量"外,还有很多变量用于保存一段冗长代码的运算结果,以便稍后使用。这种**变量应该只被赋值一次。**如果它们被赋值超过一次,就意味它们在函数中承担了一个以上的责任。如果变量承担多个责任,它就应该被替换(分解)为多个变量,保持职责单一。
范例:对输入参数赋值
before:

after:

六. 简化条件逻辑
1. 分解条件表达式(Decompose Conditional)

程序之中,复杂的条件逻辑是最常导致复杂度上升的因素之一。
对于条件逻辑,将每个分支条件分解成新函数还可以带来更多好处:可以突出条件逻辑,更清楚地表明每个分支的作用,并且突出每个分支的原因。
注:实际上为提炼函数的一个应用场景。
2. 合并条件表达式(Consolidate Conditional Expression)

3. 以卫语句取代嵌套条件表达式(Replace Nested Conditional with Guard Clauses)
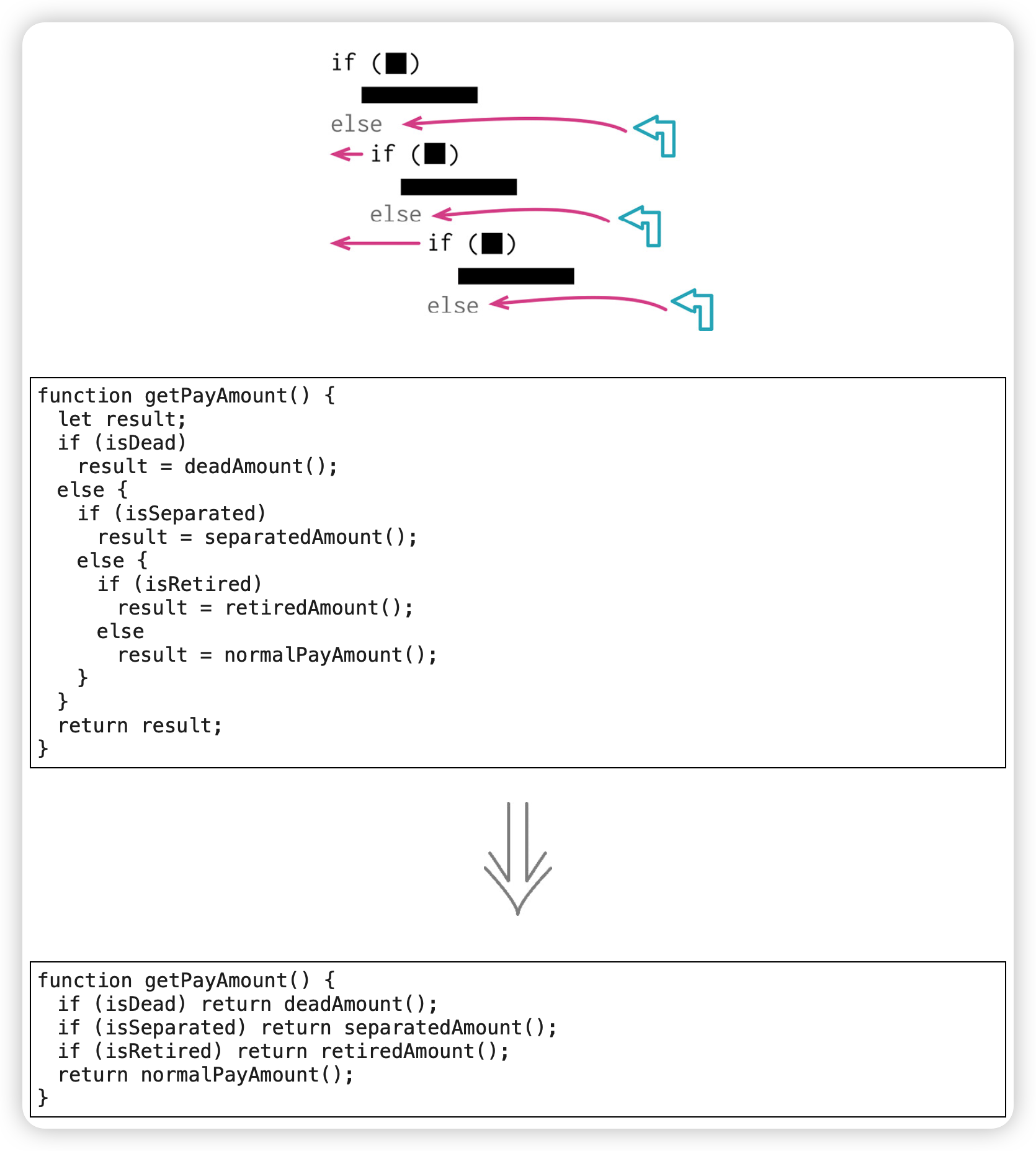
如果两条分支都是正常行为,就应该使用形如if...else...的条件表达式;如果某个条件极其罕见,就应该单独检查该条件,并在该条件为真时立刻从函数中返回。这样的单独检查常常被称为"卫语句"(guard clauses)。
如果使用if-then-else结构,则对if分支和else分支的重视是同等的;以卫语句取代嵌套条件表达式的精髓就是:给某一条分支以特别的重视。
“每个函数只能有一个入口和一个出口"的观念未必有用,保持代码清晰才是最关键的。
范例
before
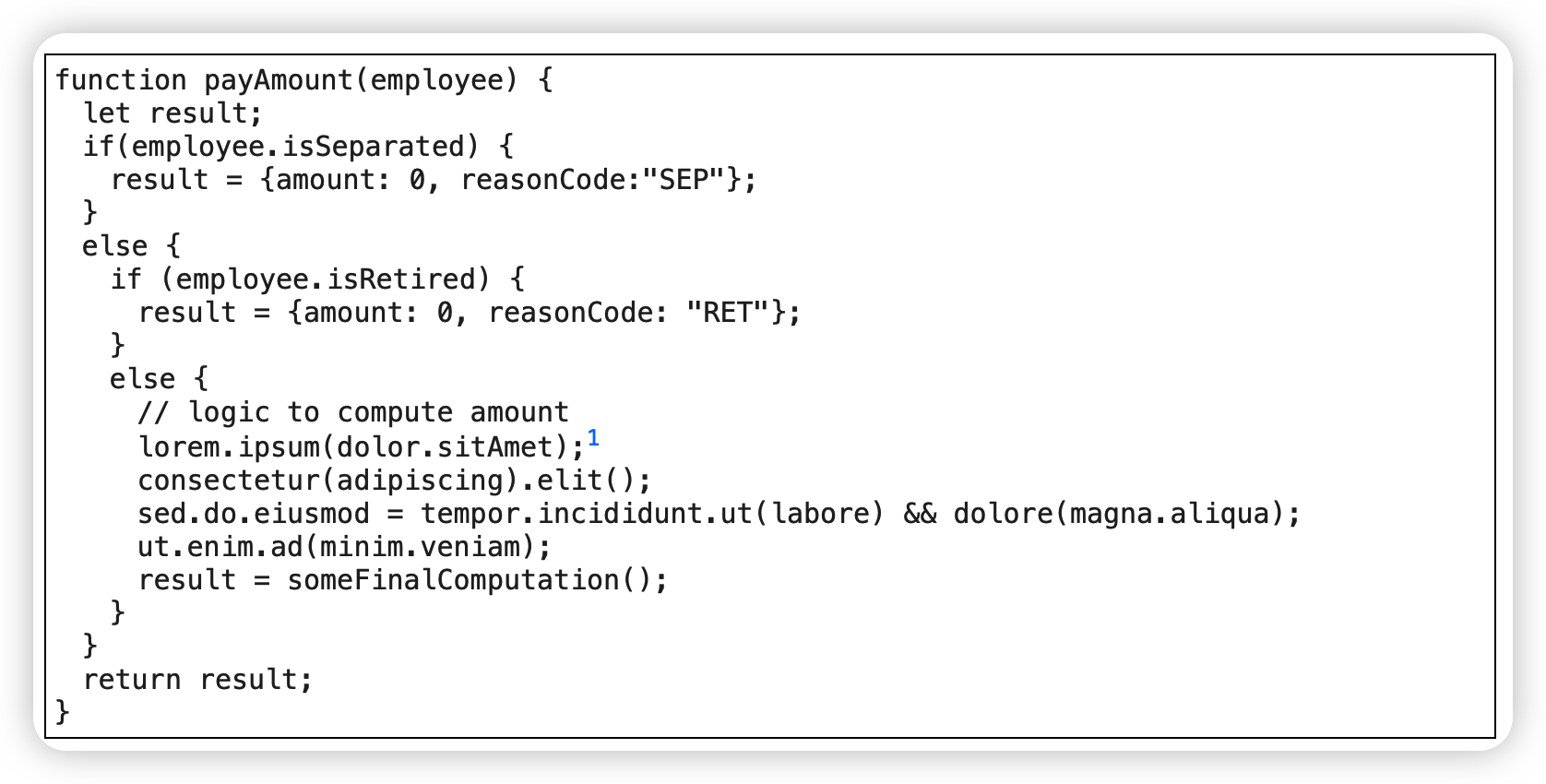
after
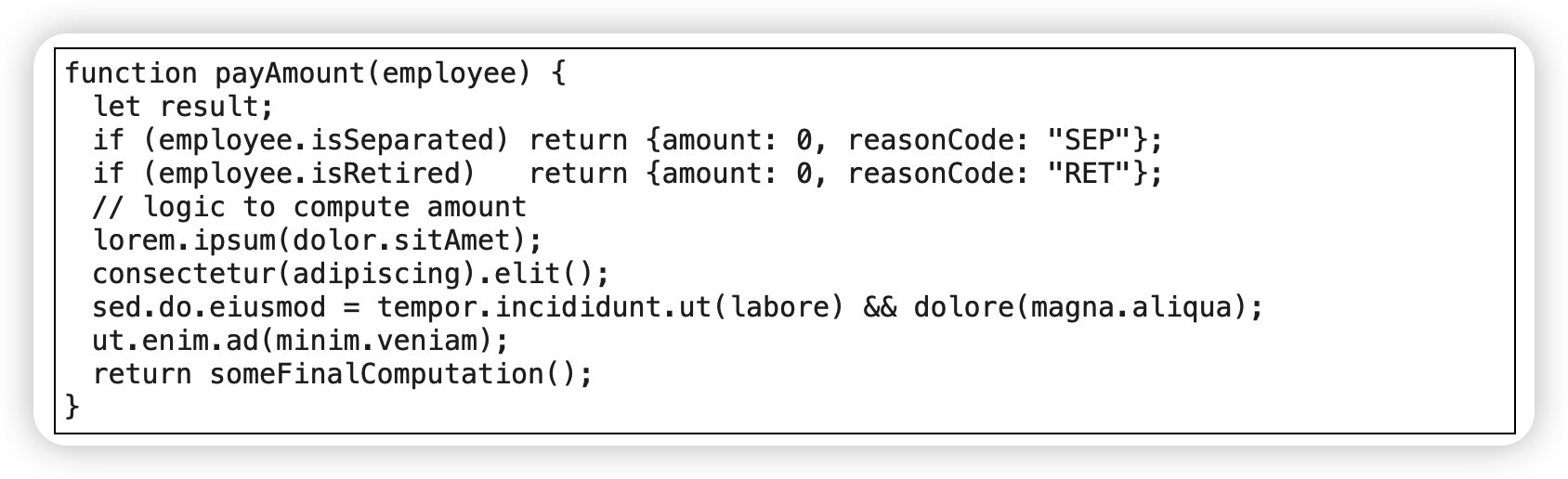
范例:将条件反转
初始

反转
合并条件表达式
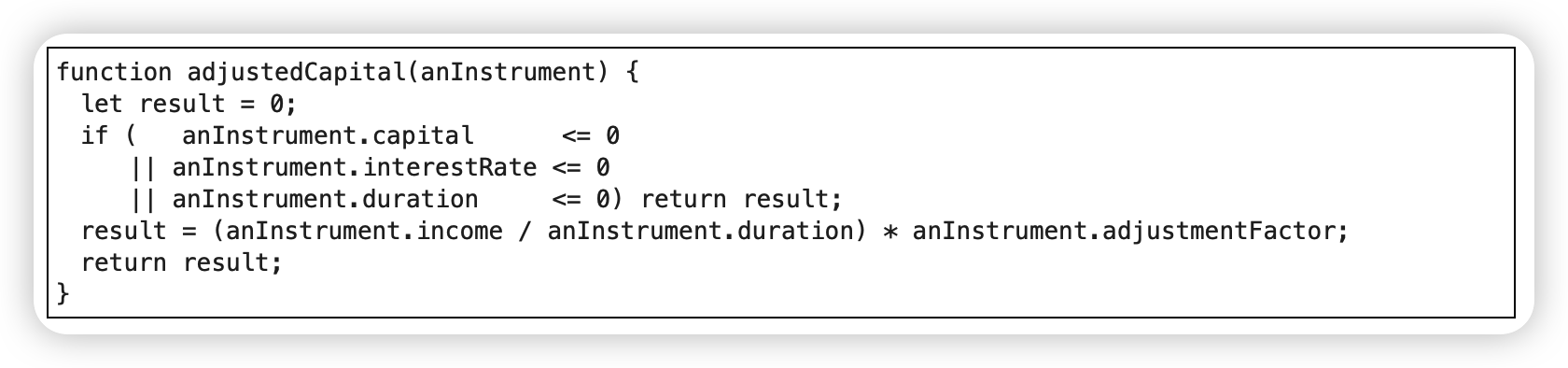
删除可变变量

4. 以多态取代条件表达式(Replace Conditional with Polymorphism)
七. 重构API
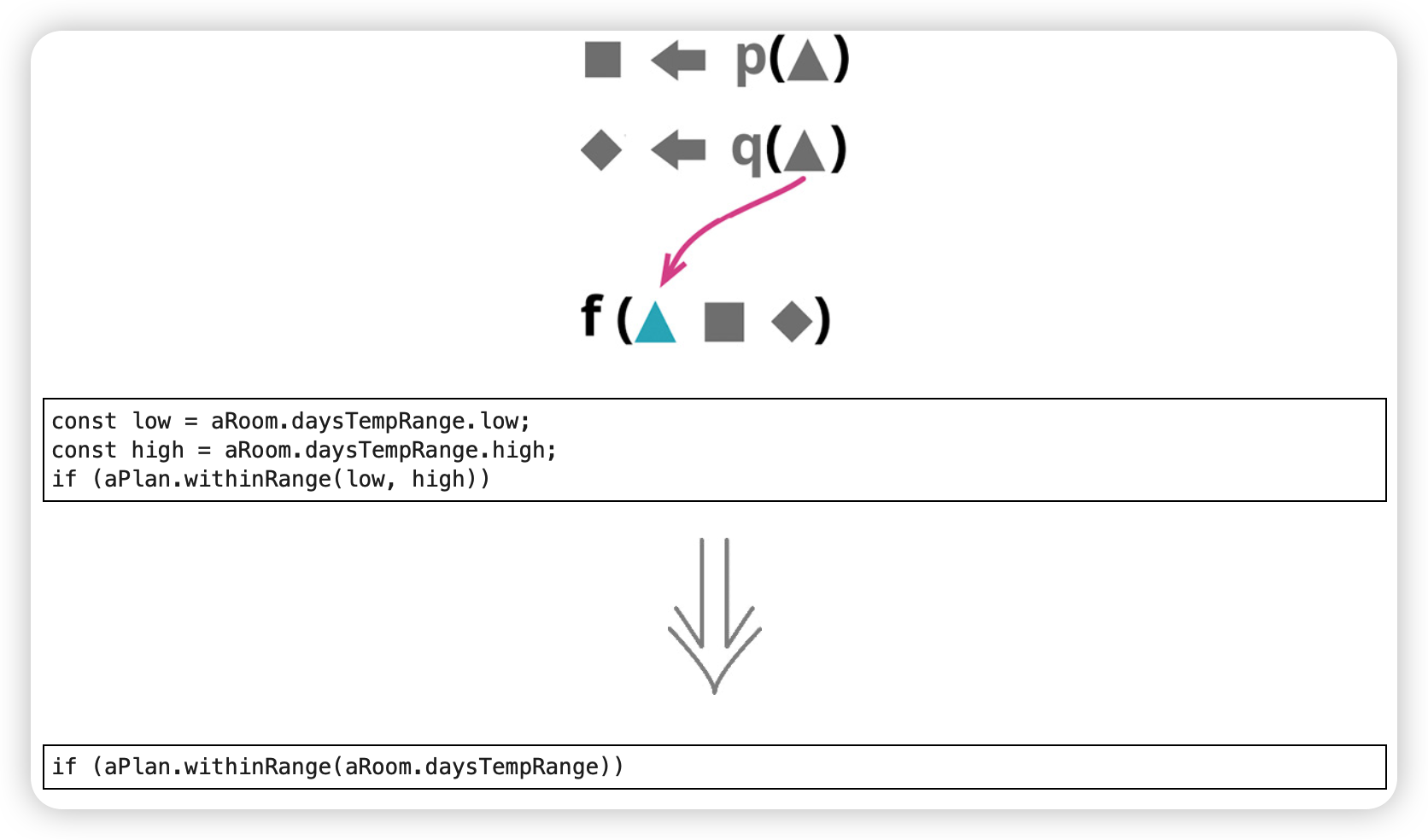
以查询取代参数(Replace Parameter with Query)
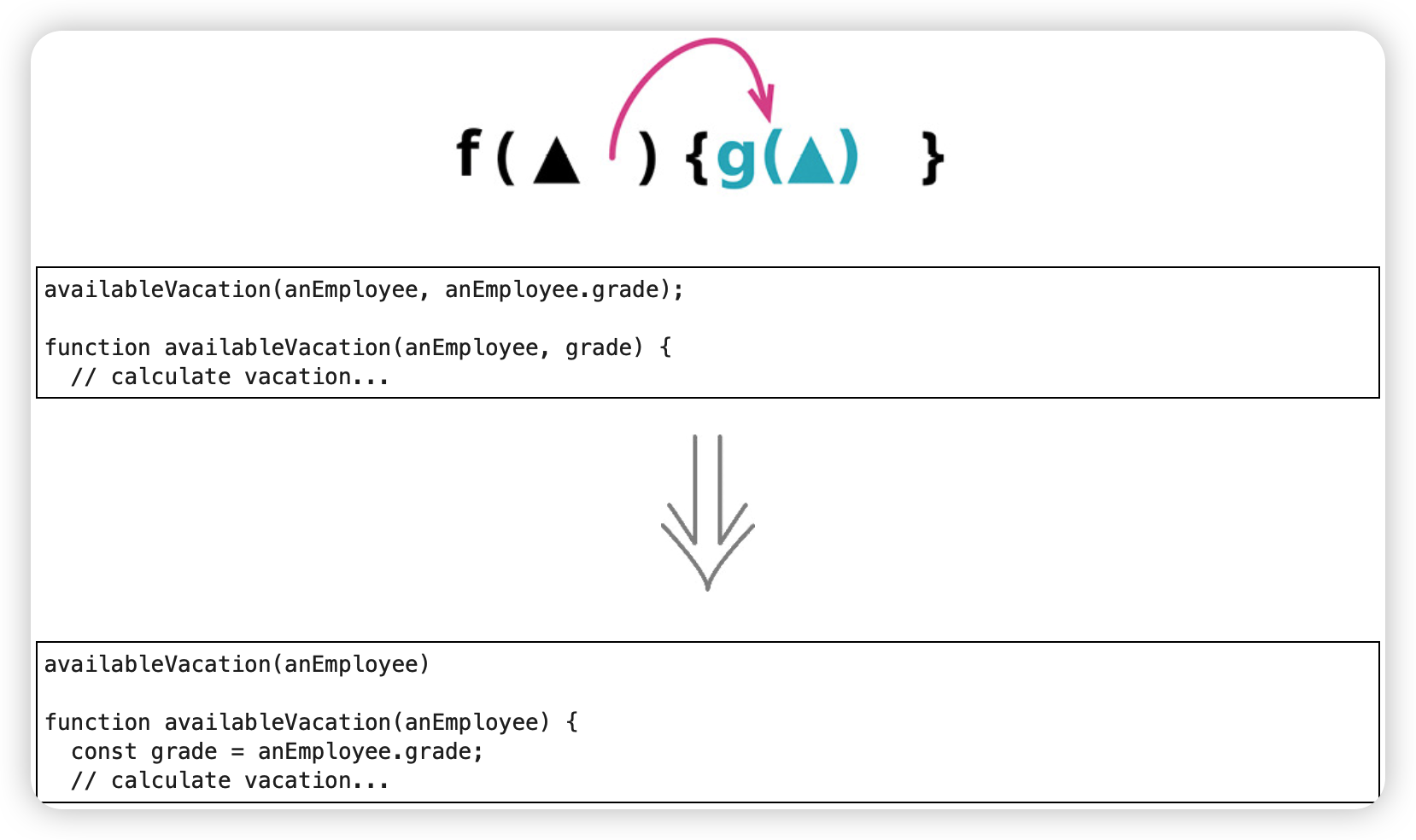
函数的参数列表应该总结该函数的可变性,标示出函数可能体现出行为差异的主要方式。和任何代码中的语句一样,参数列表应该尽量避免重复,并且参数列表越短就越容易理解。
使用场景:调用函数时传入了一个值,而这个值由函数自己来获得也是同样容易
什么是"同样容易”:函数可以承担这份原本由调用方所承担的"获得正确的参数值"的责任。
什么时候不适用:移除参数可能会给函数体增加不必要的依赖关系。
以参数取代查询(Replace Query with Parameter)
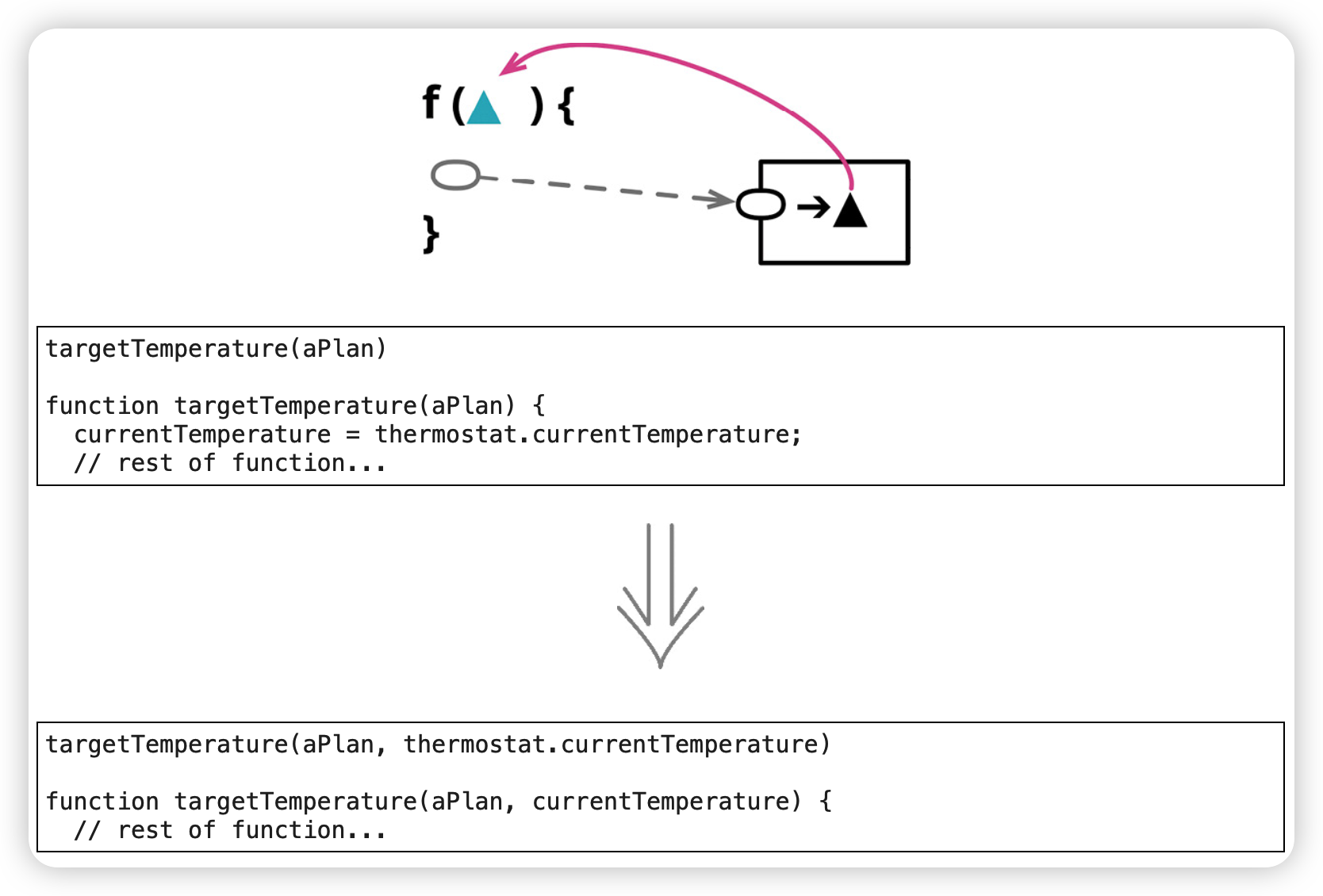
好处:改变依赖关系,去掉令人不快的引用。
注意:要考虑责任分配问题,会增加函数调用者的复杂度,而设计接口时又需要考虑易用性。
八. 处理继承关系
以委托取代超类(Replace Superclass with Delegate)
继承:子类继承父类的特征和行为 (车-交通工具)
组合:通过对现有对象进行拼装即组合产生新的具有更复杂的功能 (车-轮胎)
以组合取代继承。
一个经典的误用继承的例子:
让栈(stack)继承列表(list)。这个想法的出发点是想复用列表类的数据存储和操作能力。虽说复用是一件好事,但这个继承关系有问题:列表类的所有操作都会出现在栈类的接口上,然而其中大部分操作对一个栈来说并不适用。更好的做法应该是把列表作为栈的字段,把必要的操作委派给列表就行了。
Java
public class Stack<E> extends Vector<E> {
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
}
Stack真正需要的只有四个方法,push/pop/size/isEmpty, Stack只用到了 Vector的两个方法 isEmpty 和 size,而 push 和 pop 是 Stack 自有的实现, Vector 有大量的方法, 不适用于stack。
所以,如果父类的一些函数对子类并不适用,就说明我不应该通过继承来获得超类的功能。
同时也要避免走弯路:完全避免使用继承,如果符合继承关系的语义条件(超类的所有方法都适用于子类,子类的所有实例都是超类的实例),那么继承是一种简洁又高效的复用机制。
建议:首先(尽量)使用继承,如果发现继承有问题,再使用以委托取代超类。
范例
背景:
给一个古城里存放上古卷轴(scroll)的图书馆做了咨询。他们给卷轴的信息编制了一份目录(catalog),每份卷轴都有一个ID号,并记录了卷轴的标题(title)和一系列标签(tag),这些古老的卷轴需要日常清扫,因此代表卷轴的Scroll类继承了代表目录项的CatalogItem类,并扩展出与"需要清扫"相关的数据。


这就是一个常见的建模错误。真实存在的卷轴和只存在于纸面上的目录项,是完全不同的两种东西。比如说,关于"如何治疗灰鳞病"的卷轴可能有好几卷,但在目录上却只记录一个条目。这样的建模错误很多时候可以置之不理。像"标题"和"标签"这样的数据,可以认为就是目录中数据的副本。如果这些数据从不发生改变,可以接受这样的表现形式。但如果需要更新其中某处数据,就必须非常小心,确保同一个目录项对应的所有数据副本都被正确地更新。
就算没有数据更新的问题,把目录类作为卷轴类的父类,依然会让后来的开发者感到迷惑。
首先在Scroll类中创建一个属性,令其指向一个新建的CatalogItem实例。

然后对于子类中用到所有属于超类的函数,我要逐一为它们创建转发函数。

详细笔记
第1章 重构,第一个示例
本质上说,重构就是在代码写好之后改进它的设计。
如果你要给程序添加一个特性,但发现代码因缺乏良好的结构而不易于进行更改,那就先重构那个程序,使其比较容易添加该特性,然后再添加该特性。
是需求的变化使重构变得必要。
重构前,先检查自己是否有一套可靠的测试集。这些测试必须有自我检验能力。
每次想将一块代码抽取成一个函数时,遵循一个标准流程:最大程度减少犯错的可能。——提炼函数
重构技术就是以微小的步伐修改程序。如果你犯下错误,很容易便可发现它。
营地法则:保证离开时的代码库一定比你来时更加健康。完美的境界很难达到,但应该时时都勤加拂拭。
以实例展开如何重构:包括提炼函数、内联变量、搬移函数和以多态取代条件表达式等,
几个重要的阶段:将原函数分解成一组嵌套的函数、应用拆分阶段分离计算逻辑与输出格式化逻辑,以及为计算器引入多态性来处理计算逻辑。每一步都给代码添加了更多的结构,以便更好地表达代码的意图。
好代码的检验标准就是人们是否能轻而易举地修改它。
总结:
开展高效有序的重构,关键的心得是:小的步子可以更快前进,请保持代码永远处于可工作状态,小步修改累积起来也能大大改善系统的设计。
第2章 重构的原则
为何重构
它不是一颗"银弹",却可以算是一把"银钳子",可以帮你始终良好地控制自己的代码。重构是一个工具
重构改进软件的设计
代码结构的流失有累积效应。经常性的重构有助于代码维持自己该有的形态。消除重复代码,以确定所有事物和行为在代码中只表述一次,这正是优秀设计的根本。
重构使软件更容易理解
在重构上花一点点时间,就可以让代码更好地表达自己的意图——更清晰地说出我想要做的。
重构帮助找到bug
Kent Beck经常形容自己的一句话:“我不是一个特别好的程序员,我只是一个有着一些特别好的习惯的还不错的程序员。”
重构提高编程速度
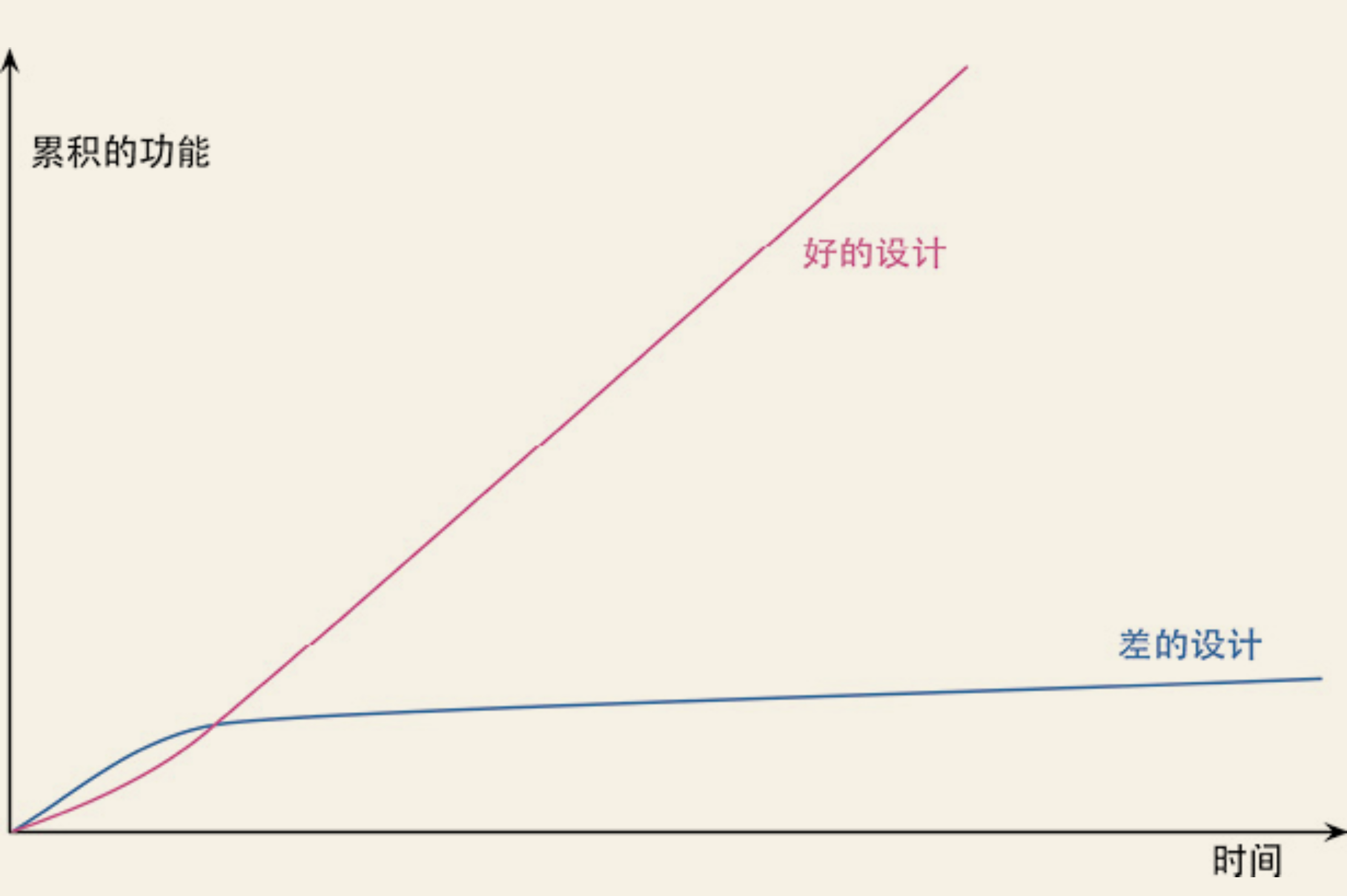
需要添加新功能时,内部质量良好的软件让我可以很容易找到在哪里修改、如何修改。良好的模块划分使我只需要理解代码库的一小部分,就可以做出修改。如果代码很清晰,引入bug的可能性就会变小。
“设计耐久性假说”:通过投入精力改善内部设计,我们增加了软件的耐久性,从而可以更长时间地保持开发的快速。
何时重构
预备性重构:让添加新功能更容易
重构的最佳时机就在添加新功能之前。
如果把某些更新数据的逻辑与查询逻辑分开,会更容易避免造成错误的逻辑纠缠。用重构改善这些情况,在同样场合再次出现同样bug的概率也会降低。
帮助理解的重构:使代码更易懂
捡垃圾式重构
有计划的重构和见机行事的重构
预备性重构、帮助理解的重构、捡垃圾式重构——都是见机行事的
长期重构
如果想替换掉一个正在使用的库,可以先如果想替换掉一个正在使用的库,可以先引入一层新的抽象,使其兼容新旧两个库的接口。一旦调用方已经完全改为使用这层抽象,替换下面的库就会容易得多。
复审代码时重构
与原作者肩并肩坐在一起,一边浏览代码一边重构,体验是最佳的。这种工作方式很自然地导向结对编程:在编程的过程中持续不断地进行代码复审。
重构的挑战
延缓新功能开发
重构的唯一目的就是让我们开发更快,用更少的工作量创造更大的价值。
有时会看到一个(大规模的)重构很有必要进行,而马上要添加的功能非常小,这时应先把新功能加上,然后再做这次大规模重构。
重构不足的情况远多于重构过度的情况。换句话说,绝大多数人应该尝试多做重构。
重构的意义不在于把代码库打磨得闪闪发光,而是纯粹经济角度出发的考量。我们之所以重构,因为它能让我们更快——添加功能更快,修复bug更快。
代码所有权
旧的接口标记为"不推荐使用"(deprecated)。
分支
持续集成(Continuous Integration,CI),也叫"基于主干开发"(Trunk-Based Development)。
重构、架构和YAGNI
重构对架构最大的影响在于,通过重构,我们能得到一个设计良好的代码库,使其能够优雅地应对不断变化的需求。“在编码之前先完成架构"这种做法最大的问题在于,它假设了软件的需求可以预先充分理解。
重构与软件开发过程
既牢固可靠又能快速响应变化的需求。
自动化重构
不仅能处理文本,还能处理语法树,这是IDE相比于文本编辑器更先进的地方。重构工具不仅需要理解和修改语法树,还要知道如何把修改后的代码写回编辑器视图。如果我给一个变量改名,工具会提醒我修改使用了旧名字的注释。能借助语法树来分析和重构程序代码,这是IDE与普通文本编辑器相比具有的一大优势。
第3章 代码的坏味道
神秘命名(Mysterious Name)
命名是编程中最难的两件事之一[mf-2h]。正因为如此,改名可能是最常用的重构手法,包括改变函数声明(用于给函数改名)、变量改名、字段改名。
重复代码(Duplicated Code)
过长函数(Long Function)
积极地分解函数.
原则:每当感觉需要以注释来说明点什么的时候,我们就把需要说明的东西写进一个独立函数中,并以其用途(而非实现手法)命名。关键不在于函数的长度,而在于函数"做什么"和"如何做"之间的语义距离。
如何确定该提炼哪一段代码呢?一个很好的技巧是:寻找注释。它们通常能指出代码用途和实现手法之间的语义距离。
条件表达式和循环常常也是提炼的信号。你可以使用分解条件表达式处理条件表达式。
对于庞大的switch语句,其中的每个分支都应该通过提炼函数变成独立的函数调用。如果有多个switch语句基于同一个条件进行分支选择,就应该使用以多态取代条件表达式。
应该将循环和循环内的代码提炼到一个独立的函数中。如果你发现提炼出的循环很难命名,可能是因为其中做了几件不同的事。如果是这种情况,请勇敢地使用拆分循环将其拆分成各自独立的任务。
过长参数列表(Long Parameter List)
如果可以向某个参数发起查询而获得另一个参数的值,那么就可以使用以查询取代参数去掉这第二个参数。
如果你发现自己正在从现有的数据结构中抽出很多数据项,就可以考虑使用保持对象完整手法,直接传入原来的数据结构。如果有几项参数总是同时出现,可以用引入参数对象将其合并成一个对象。
如果某个参数被用作区分函数行为的标记(flag),可以使用移除标记参数。
使用类可以有效地缩短参数列表。如果多个函数有同样的几个参数,引入一个类就尤为有意义。你可以使用函数组合成类,将这些共同的参数变成这个类的字段。
全局数据(Global Data)
封装变量。有少量的全局数据或许无妨,但数量越多,处理的难度就会指数上升。
可变数据(Mutable Data)
可以用封装变量来确保所有数据更新操作都通过很少几个函数来进行,使其更容易监控和演进。
如果一个变量在不同时候被用于存储不同的东西,可以使用拆分变量将其拆分为各自不同用途的变量,从而避免危险的更新操作。使用移动语句和提炼函数尽量把逻辑从处理更新操作的代码中搬移出来,将没有副作用的代码与执行数据更新操作的代码分开。设计API时,可以使用将查询函数和修改函数分离。
尽早使用移除设值函数,缩小变量作用域。
发散式变化(Divergent Change)
如果某个模块经常因为不同的原因在不同的方向上发生变化,发散式变化就出现了。
提炼拆分。
霰弹式修改(Shotgun Surgery)
如果每遇到某种变化,你都必须在许多不同的类内做出许多小修改,你所面临的坏味道就是霰弹式修改。
搬移函数和搬移字段把所有需要修改的代码放进同一个模块里。如果有很多函数都在操作相似的数据,可以使用函数组合成类。如果有些函数的功能是转化或者充实数据结构,可以使用函数组合成变换。如果一些函数的输出可以组合后提供给一段专门使用这些计算结果的逻辑,这种时候常常用得上拆分阶段。
一个常用的策略就是使用与内联(inline)相关的重构——如内联函数(1或是内联类——把本不该分散的逻辑拽回一处。完成内联之后,你可能会闻到过长函数或者过大的类的味道,再用与提炼相关的重构手法将其拆解成更合理的小块。
依恋情结(Feature Envy)
模块化,就是力求将代码分出区域,最大化区域内部的交互、最小化跨区域的交互。
一个函数跟另一个模块中的函数或者数据交流格外频繁,远胜于在自己所处模块内部的交流,这就是依恋情结的典型情况。
数据泥团(Data Clumps)
总是绑在一起出现的数据真应该拥有属于它们自己的对象。
基本类型偏执(Primitive Obsession)
把钱当作普通数字来计算的情况、计算物理量时无视单位(如把英寸与毫米相加)的情况以及大量类似if (a < upper && a > lower)这样的代码。
运用以对象取代基本类型。
重复的switch (Repeated Switches)
多态。
循环语句(Loops)
?管道操作(如filter和map)
冗赘的元素(Lazy Element)
随着重构的进行越变越小,类最后只剩了一个函数。及时删除这个类,使用内联函数或是内联类。
夸夸其谈通用性(Speculative Generality)
用不上的装置只会挡你的路,所以,把它搬开吧。
临时字段(Temporary Field)
其内部某个字段仅为某种特定情况而设。
过长的消息链(Message Chains)
先观察消息链最终得到的对象是用来干什么的,看看能否以提炼函数把使用该对象的代码提炼到一个独立的函数中,再运用搬移函数把这个函数推入消息链。
中间人(Middle Man)
某个类的接口有一半的函数都委托给其他类,这样就是过度运用。这时应该使用移除中间人。
内幕交易(Insider Trading)
模块之间大量交换数据,因为这会增加模块间的耦合。
在实际情况里,一定的数据交换不可避免,但我们必须尽量减少这种情况,并把这种交换都放到明面上来。
过大的类(Large Class)
异曲同工的类(Alternative Classes with Different Interfaces)
纯数据类(Data Class)
纯数据类:它们拥有一些字段,以及用于访问(读写)这些字段的函数,除此之外一无长物。
被拒绝的遗赠(Refused Bequest)
子类应该继承超类的函数和数据。
不愿意支持超类的接口,就不要虚情假意地糊弄继承体系,应该运用以委托取代子类或者以委托取代超类彻底划清界限。
注释(Comments)
如果你需要注释来解释一块代码做了什么,试试提炼函数;如果函数已经提炼出来,但还是需要注释来解释其行为,试试用改变函数声明为它改名;如果你需要注释说明某些系统的需求规格,试试引入断言。
第4章 构筑测试体系
自测试代码的价值
时间统计:编写代码的时间仅占所有时间中很少的一部分。有些时间用来决定下一步干什么,有些时间花在设计上,但是,花费在调试上的时间是最多的。
一套测试就是一个强大的bug侦测器,能够大大缩减查找bug所需的时间。
撰写测试代码的最好时机是在开始动手编码之前,把注意力集中于接口而非实现。
测试实例
总是确保测试不该通过时真的会失败:在代码中暂时引入一个错误。
探测边界条件
输入:空集合、0、空字符串... 预期输出:?
考虑可能出错的边界条件,把测试火力集中在那儿。
不要因为测试无法捕捉所有的bug就不写测试,因为测试的确可以捕捉到大多数bug。
第5章 介绍重构名录
本章主要作用是承上启下,略。
第6章 第一组重构
提炼函数(Extract Function)
动机
将意图与实现分开:如果你需要花时间浏览一段代码才能弄清它到底在干什么,那么就应该将其提炼到一个函数中,并根据它所做的事为其命名。因为大多数时候根本不需要关心函数如何达成其用途(这是函数体内干的事)
好名字:在一个大函数中,一段代码放着一句注释,提炼成函数,注释往往提示一个好名字。
做法
创造一个新函数:以"做什么"而非"怎么做"来命名。
无局部变量,直接提炼成函数;
有局部变量但只读,作为参数传递给目标函数
局部变量被赋值:只在提炼函数中被使用则可直接声明在提炼函数中;在提炼函数外也被使用则可作为提炼函数的返回值;多个变量被修改可考虑返回一个对象或者使用其他重构手法(以查询取代临时变量、拆分变量)
内联函数(Inline Function)
动机
间接性可能带来帮助,但非必要的间接性总是让人不舒服。
某些函数其内容和名称清晰易读
一群函数的组织不甚合理,先内联到一个大函数,再提炼。
做法
确定函数不具多态性
找到所有调用点执行替换(重点在于始终小步前进)
提炼变量(Extract Variable)
动机
提供了合适的上下文:帮助我们将表达式分解为比较容易管理的形式,也便于理解一部分代码是干什么的。
内联变量(Inline Variable)
动机
有时候,变量名字并不比表达式本身更具表现力。还有些时候,变量可能会妨碍重构附近的代码。
改变函数声明(Change Function Declaration)
动机
一个好名字能让人一眼看出函数的用途;
函数的参数列表阐述了函数如何与外部世界共处,修改参数列表不仅能增加函数的应用范围,还能改变连接一个模块所需的条件,从而去除不必要的耦合。
封装变量(Encapsulate Variable)
动机
对于所有可变的数据,只要它的作用域超出单个函数,我就会将其封装起来,只允许通过函数访问。数据的作用域越大,封装就越重要。
变量改名(Rename Variable)
动机
解释一段程序在干什么,对于作用域超出一次函数调用的字段,则需要更用心命名。
引入参数对象(Introduce Parameter Object)
动机
将数据组织成结构,使数据项之间的关系更清晰;
缩短参数列表;
代码一致性:所有使用该数据结构的函数都可以通过相同的名字来访问其中元素。
改变代码的概念图景,将这些数据结构提升为新的抽象概念
函数组合成类(Combine Functions into Class)
动机
如果发现一组函数形影不离地操作同一块数据(通常是将这块数据作为参数传递给函数),是时候组建一个类了。类能明确地给这些函数提供一个共用的环境,在对象内部调用这些函数可以少传许多参数,从而简化函数调用。
函数组合成变换(Combine Functions into Transform)
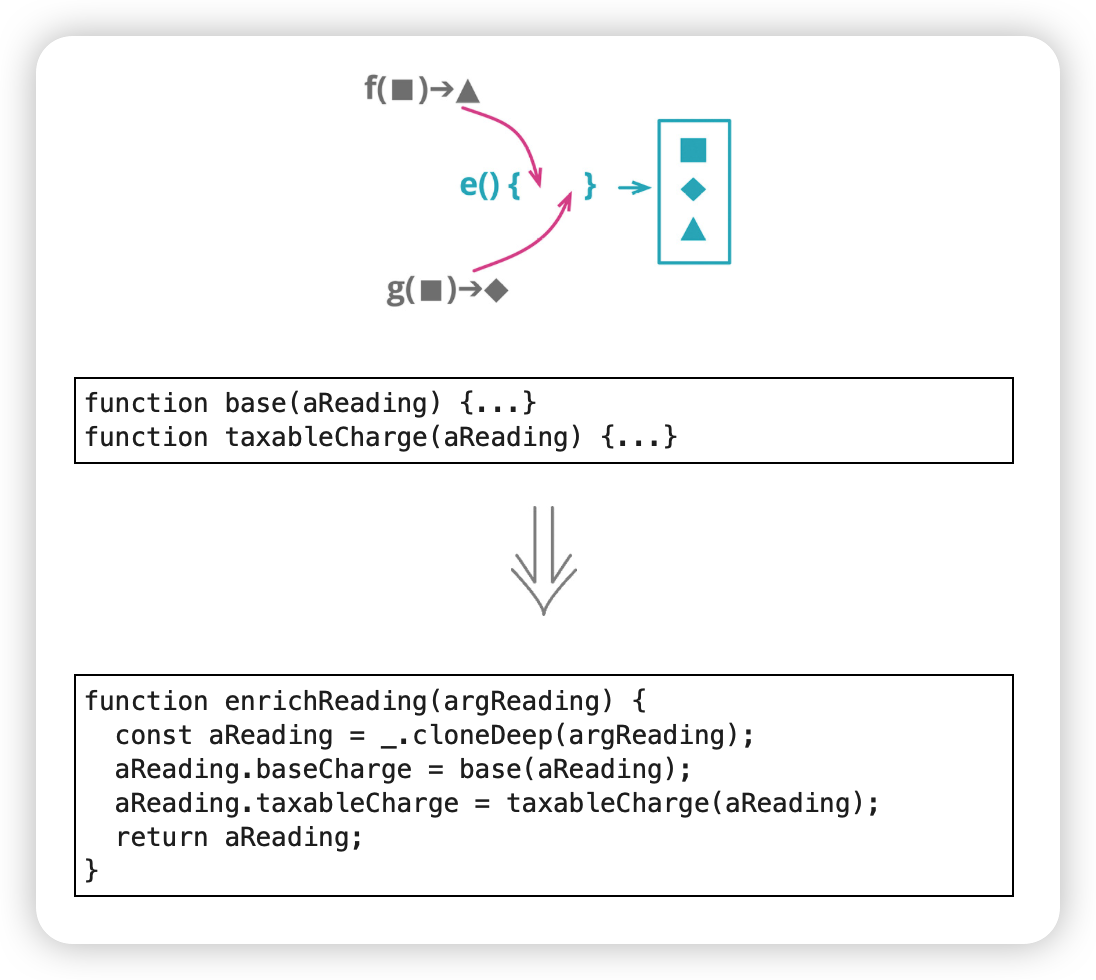
动机
在软件中,经常需要把数据"喂"给一个程序,让它再计算出各种派生信息。这些派生数值可能会在几个不同地方用到,因此这些计算逻辑也常会在用到派生数据的地方重复。把所有计算派生数据的逻辑收拢到一处,这样始终可以在固定的地方找到和更新这些逻辑,避免到处重复。
函数组合成变换与函数组合成类区别:
如果代码中会对源数据做更新,那么使用类要好得多;如果使用变换,派生数据会被存储在新生成的记录中,一旦源数据被修改,我就会遭遇数据不一致。
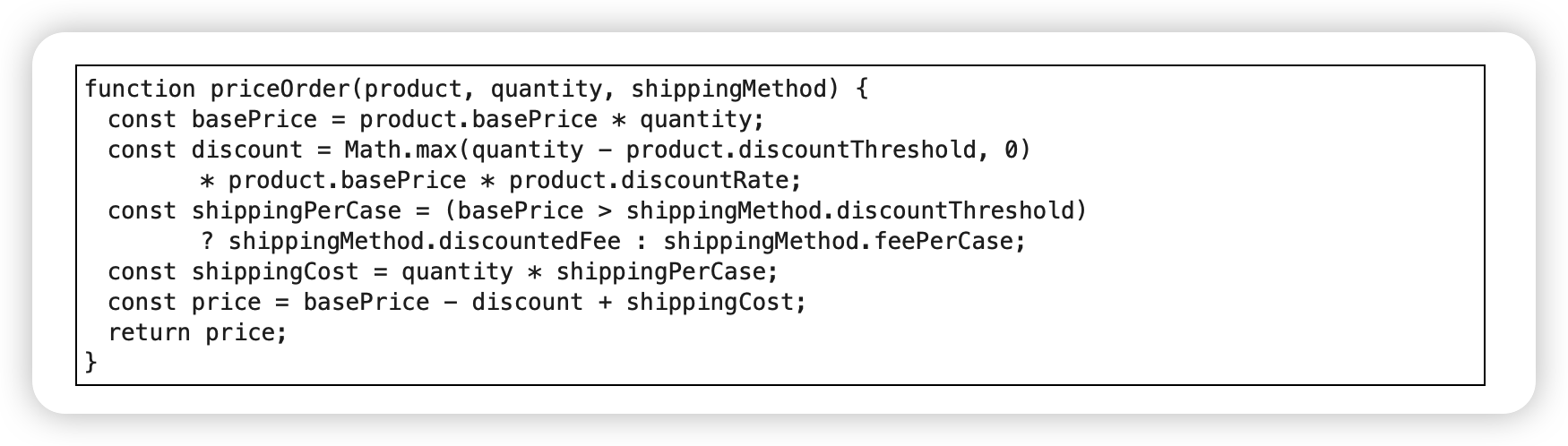
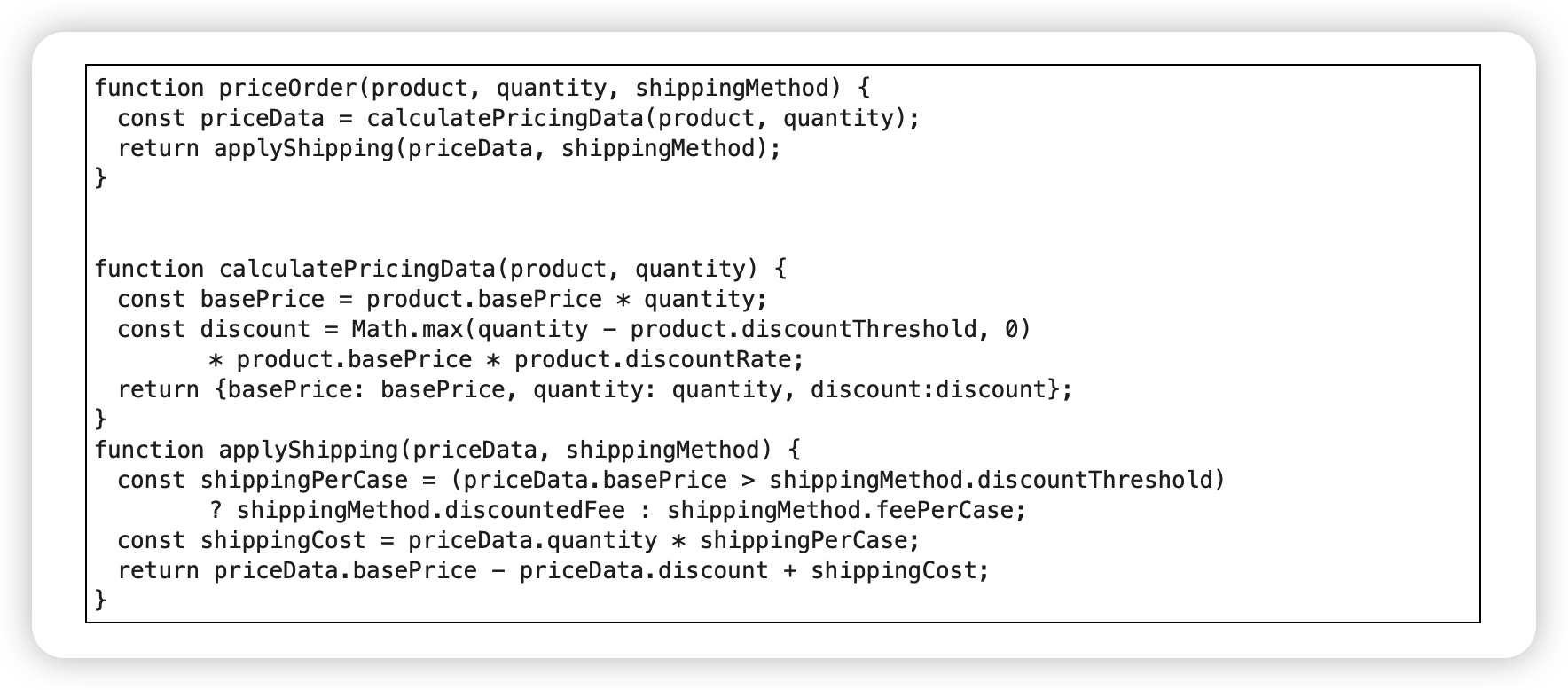
拆分阶段(Split Phase)
动机
一段代码在同时处理两件不同的事,可以考虑把它拆分成各自独立的模块,因为这样到了需要修改的时候,可以单独处理每个主题。
例子
重构前:
重构后:
提炼函数、引入中转数据结构:
第七章 封装
封装记录(Encapsulate Record)
动机
对象可以隐藏结构的细节,有助于字段的改名,方便拓展以应对变化。
封装集合(Encapsulate Collection)
动机
封装集合时人们常常犯一个错误:只对集合变量的访问进行了封装,但依然让取值函数返回集合本身。这使得集合的成员变量可以直接被修改,而封装它的类则全然不知,无法介入。
做法:
在类上提供一些修改集合的方法——通常是"添加"和"移除"方法。
以对象取代基本类型(Replace Primitive with Object)
以查询取代临时变量(Replace Temp with Query)
提炼类(Extract Class)
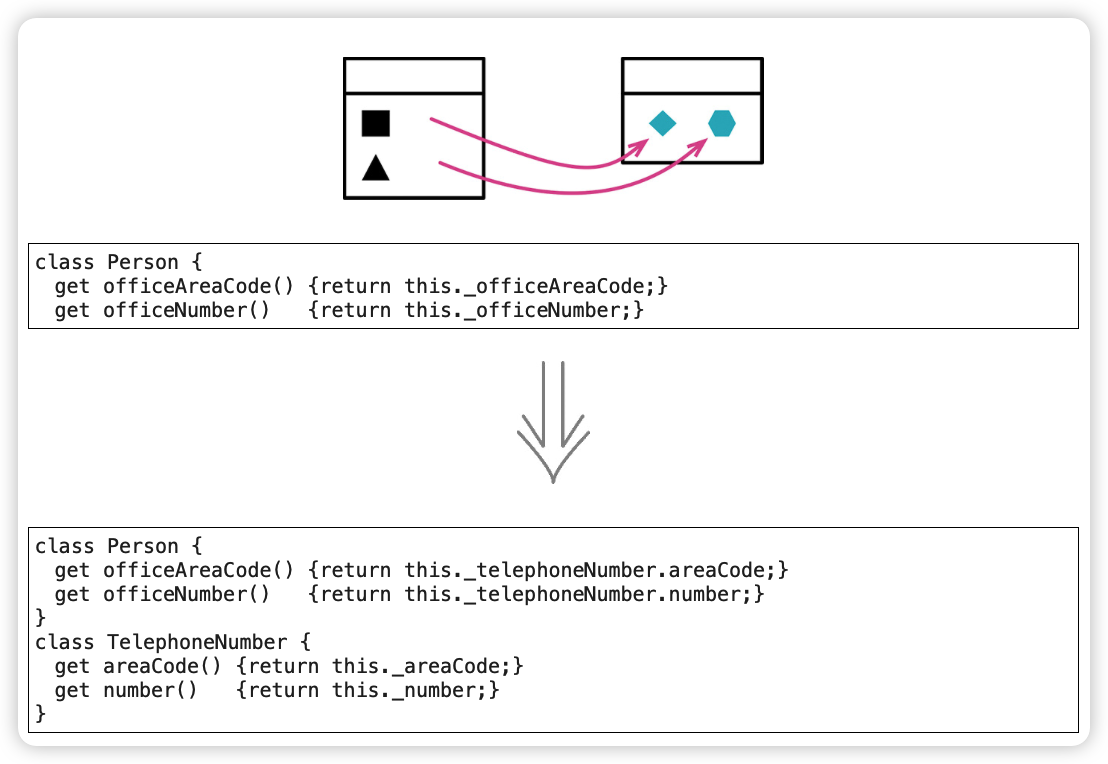
动机
如果某些数据和某些函数总是一起出现,某些数据经常同时变化甚至彼此相依,这就表示你应该将它们分离出去。
如果你发现子类化只影响类的部分特性,或如果你发现某些特性需要以一种方式来子类化,某些特性则需要以另一种方式子类化,这就意味着你需要分解原来的类。
内联类(Inline Class)
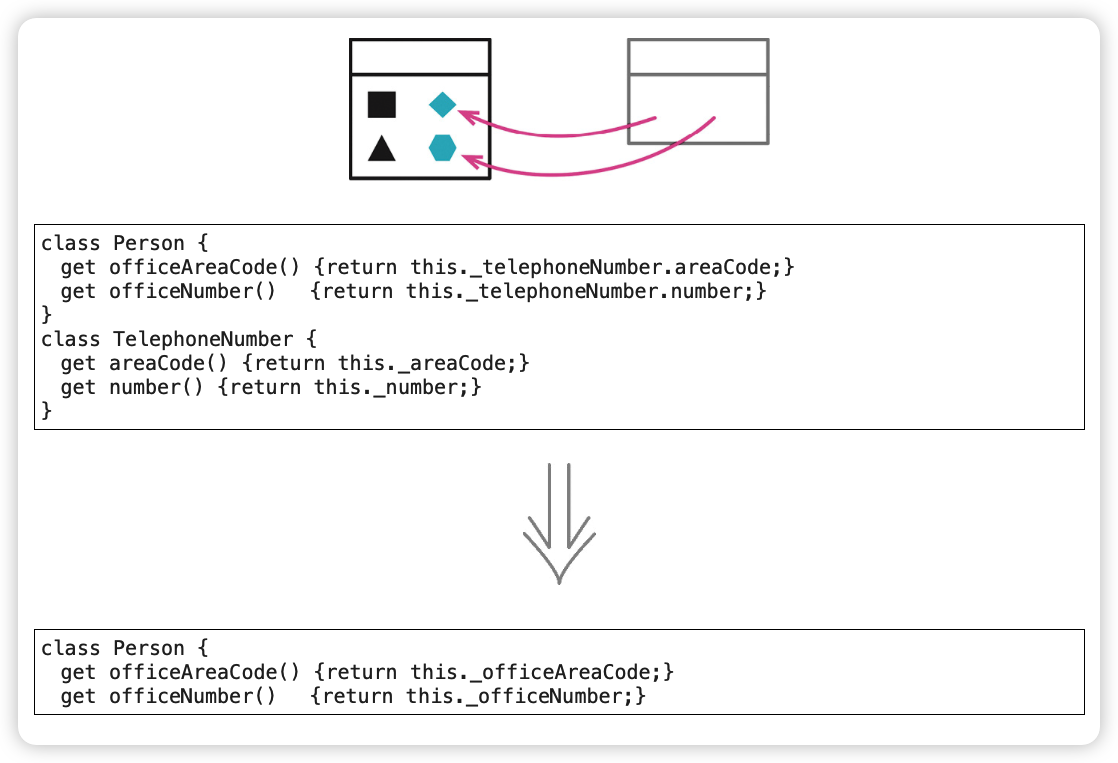
隐藏委托关系(Hide Delegate)
移除中间人(Remove Middle Man)
“合适的隐藏程度”。
替换算法(Substitute Algorithm)
第8章 搬移特性
另一种类型的重构也很重要,那就是在不同的上下文之间搬移元素。
搬移函数(Move Function)
任何函数都需要具备上下文环境才能存活。
搬移函数最直接的一个动因是,它频繁引用其他上下文中的元素,而对自身上下文中的元素却关心甚少,将函数移动到联系更紧密的上下文那么系统别处就可以减少对当前模块的依赖,获得更好的封装效果。
整理代码时,发现需要频繁调用一个别处的函数;或者函数内部定义了一个帮助函数,而该帮助函数可能在别的地方也有用处,此时就可以将它搬移到某些更通用的地方。
是否需要搬移函数常常不易抉择,但决定越难做,通常说明"搬移这个函数与否"的重要性也越低。
范例:搬移内嵌函数至顶层
before:
after:
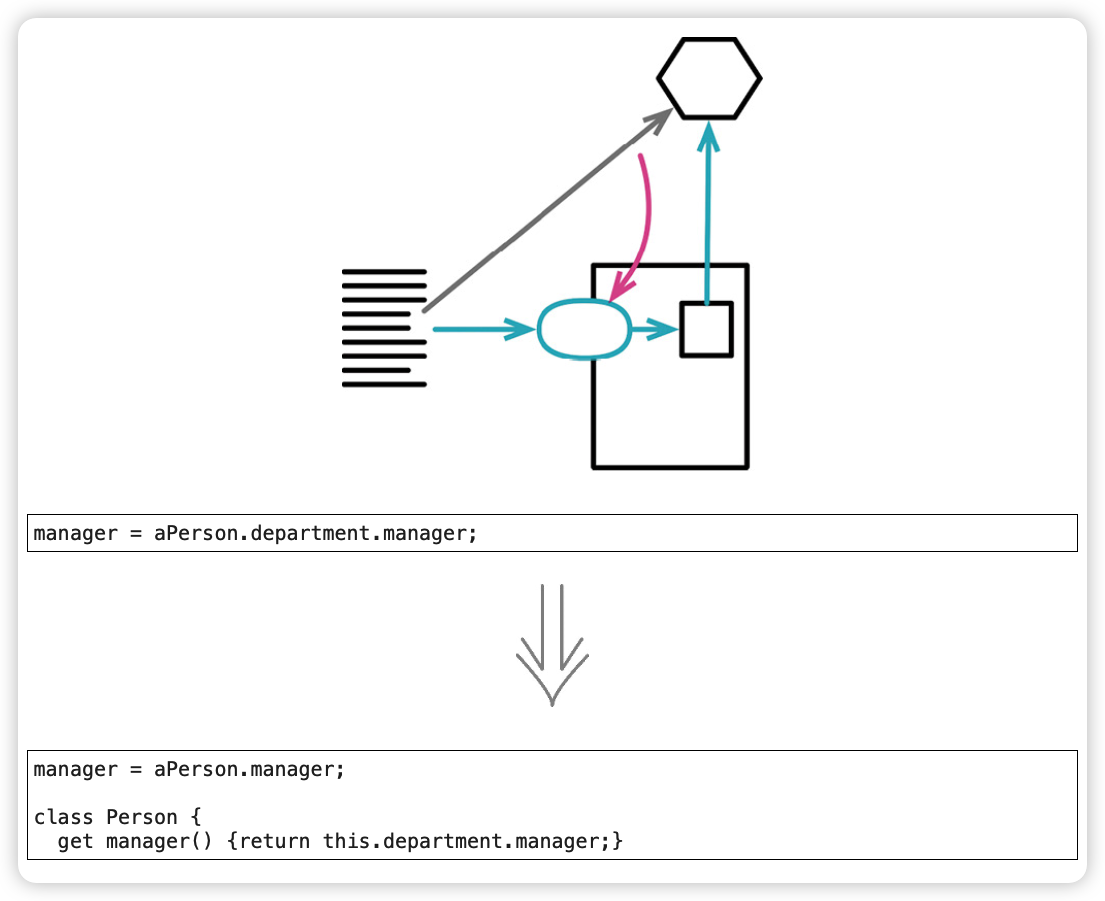
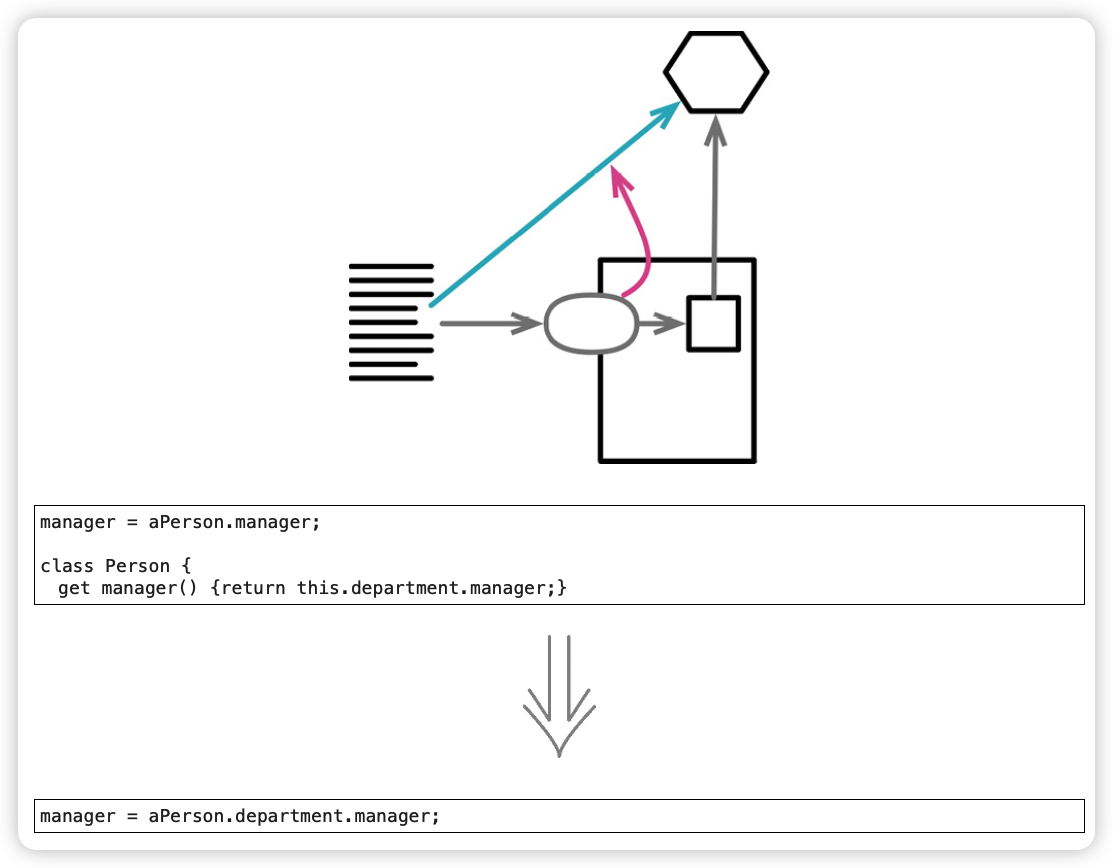
范例:在类之间搬移函数
before:
after:
搬移字段(Move Field)
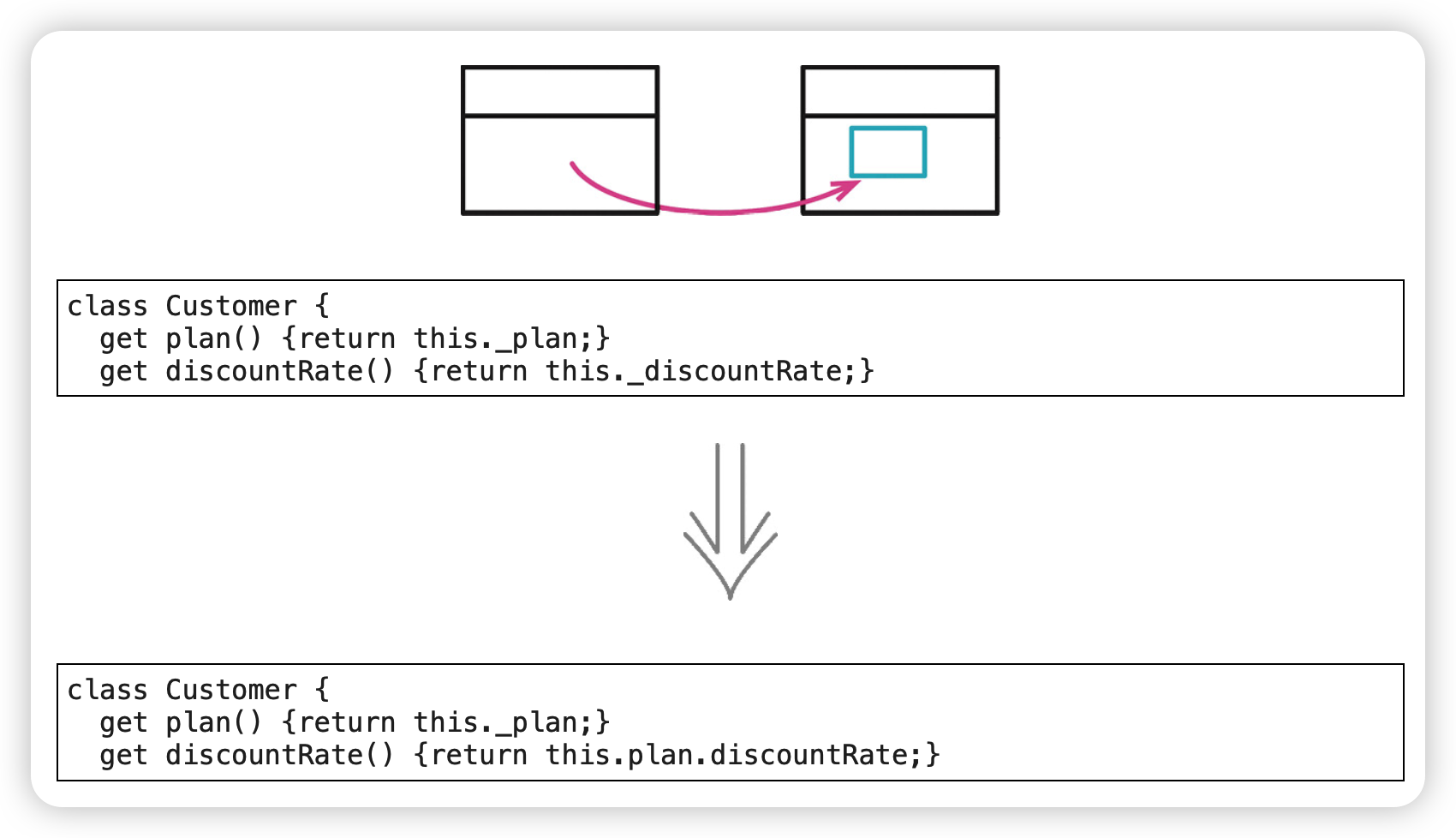
范例
before:
after:


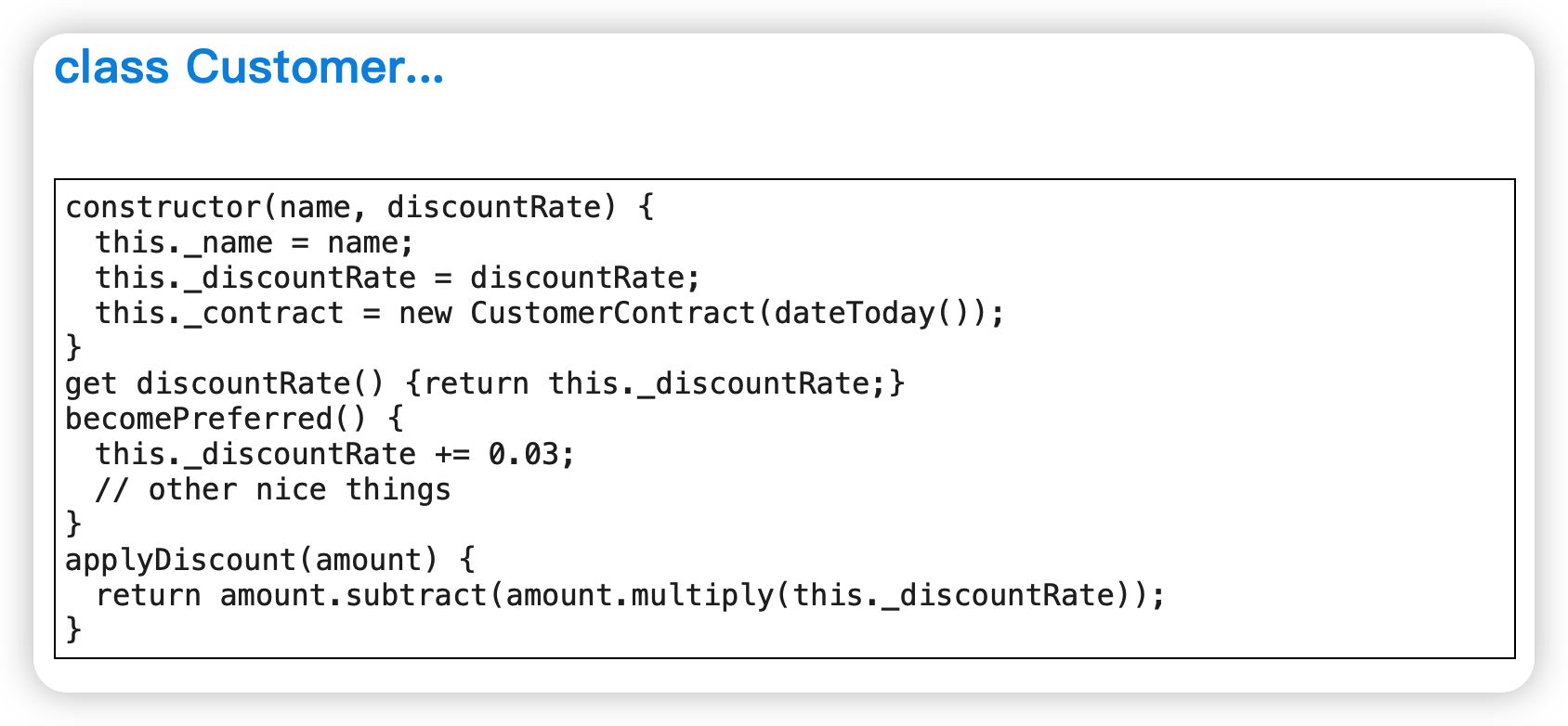
范例:搬移字段到共享对象
before:

after:


搬移语句到函数(Move Statements into Function)
“消除重复”:如果发现调用某个函数时,总有一些相同的代码也需要每次执行,则考虑将此段代码合并到函数里头。
如果某些语句与一个函数放在一起更像一个整体,并且更有助于理解,则将语句搬移到函数里去。如果它们与函数不像一个整体,但仍应与函数一起执行,可以用提炼函数将语句和函数一并提炼出去。
范例
before:
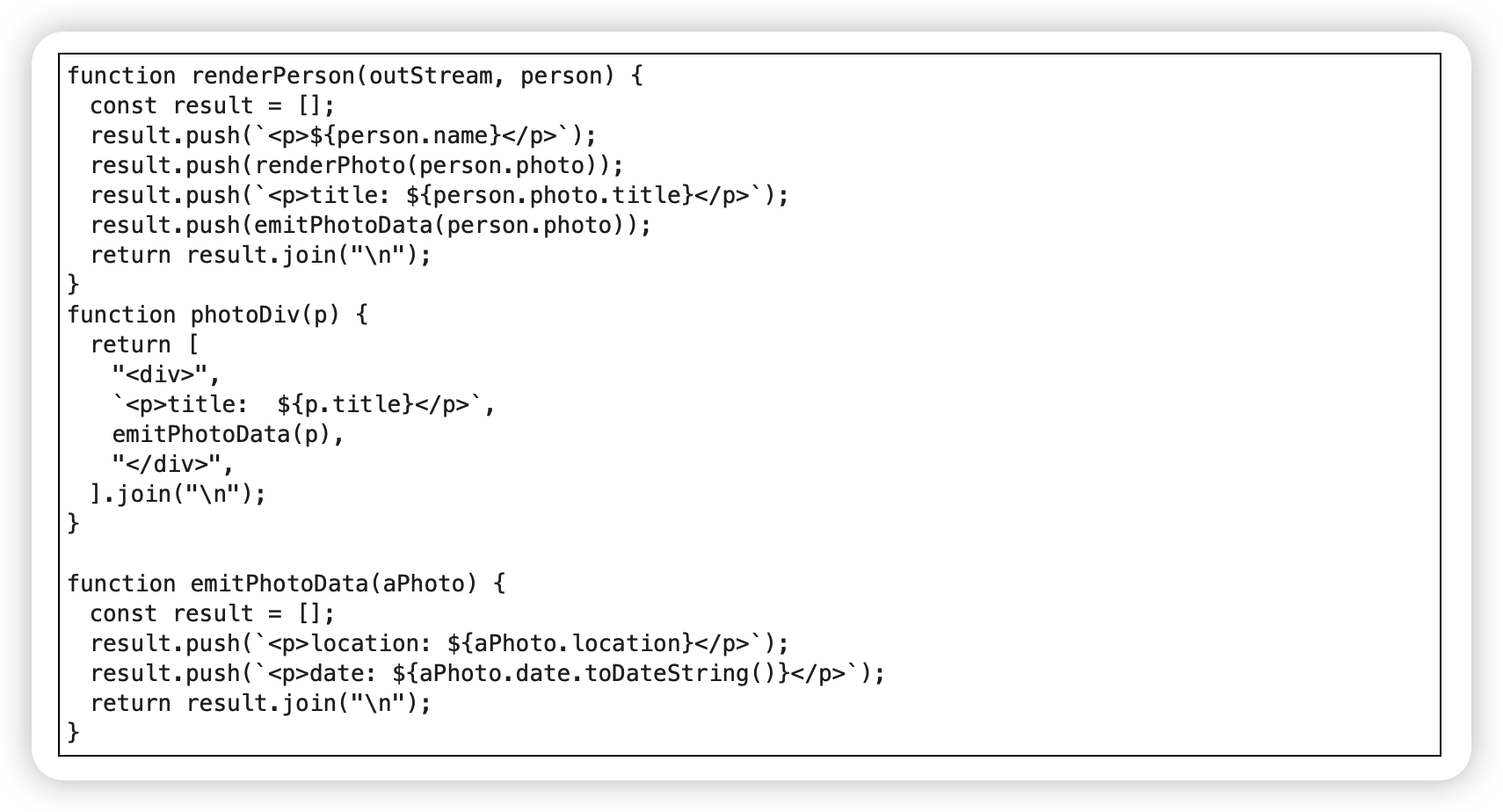
after:
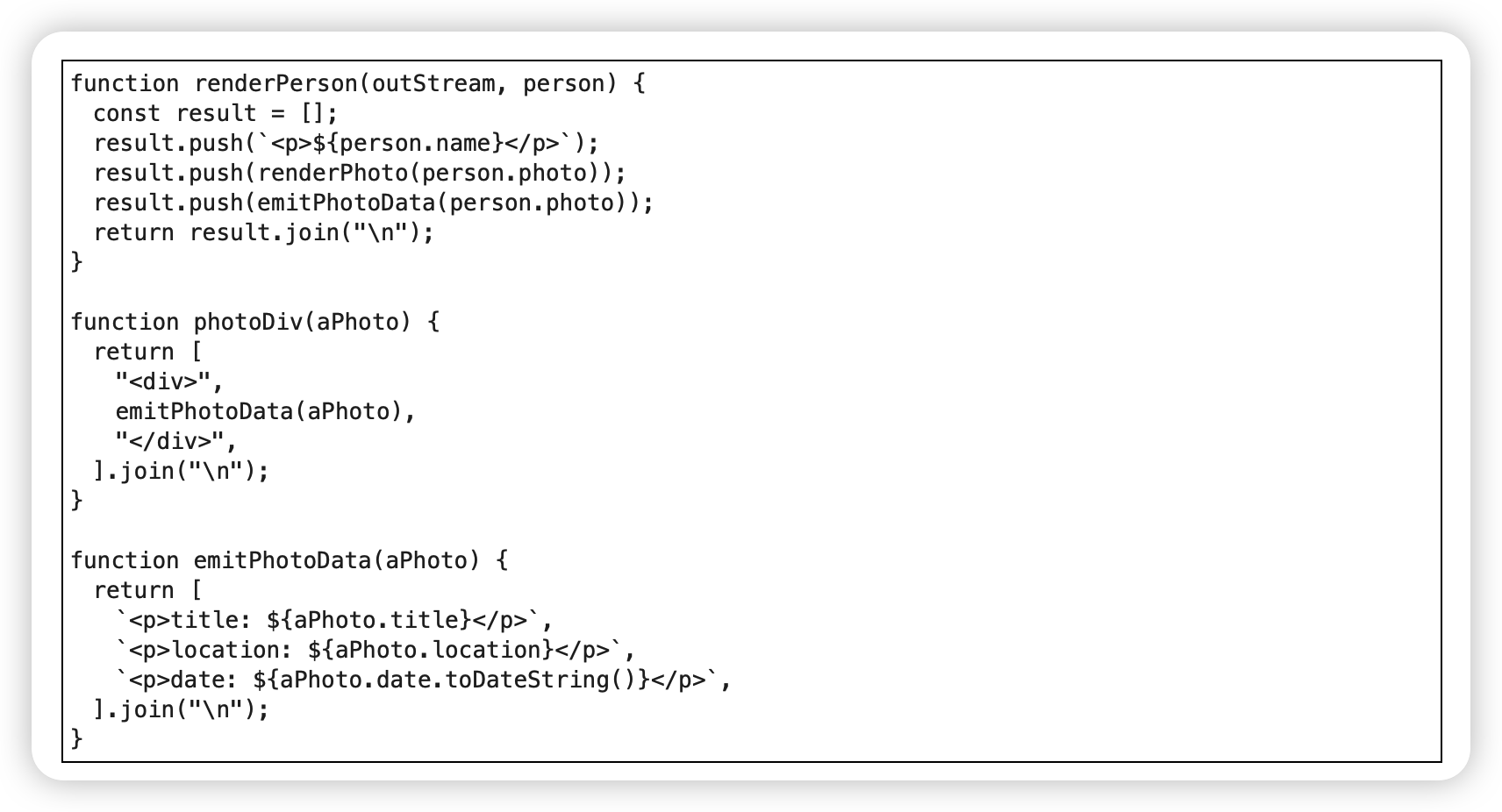
搬移语句到调用者(Move Statements to Callers)
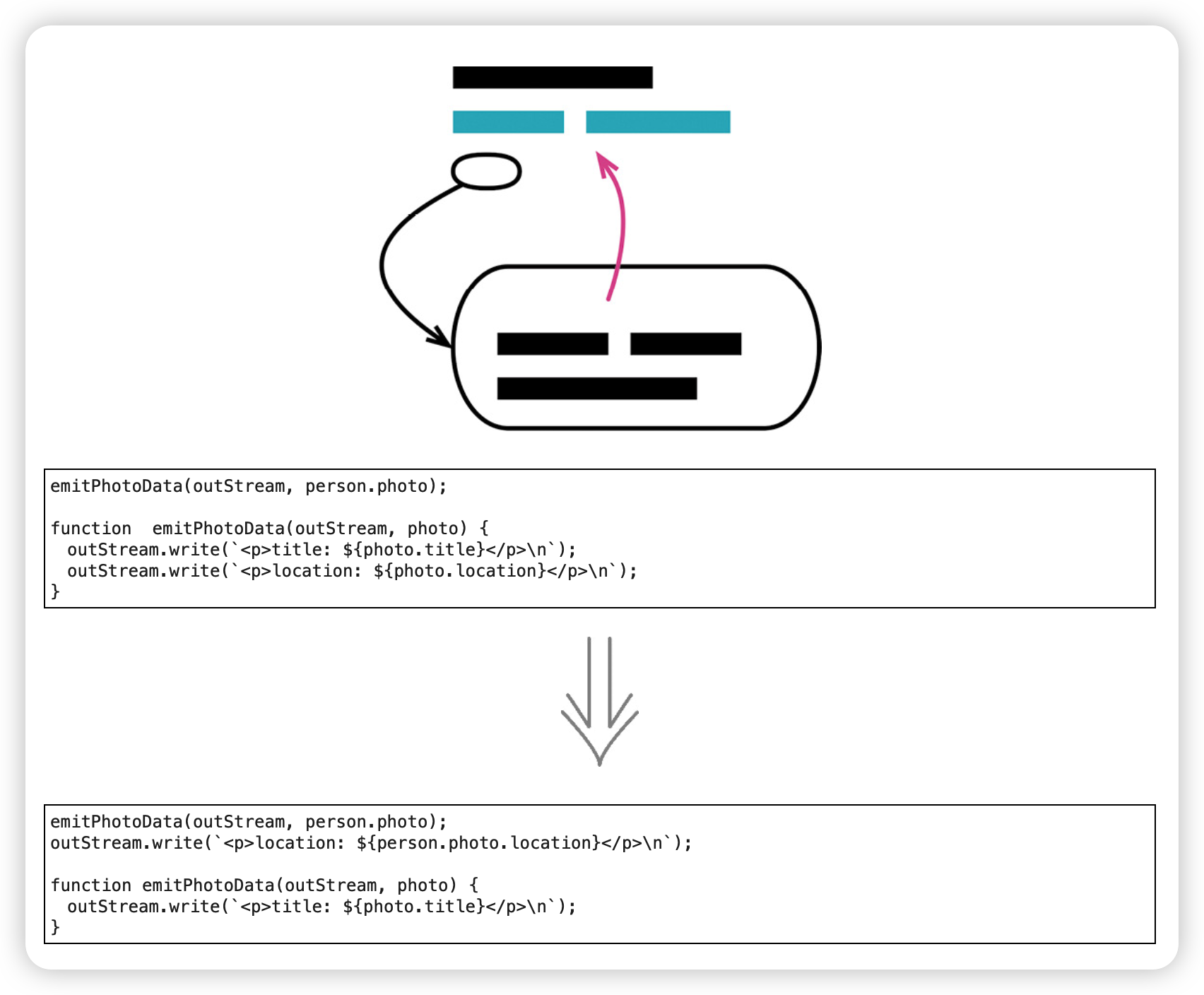
随着系统能力发生演进,原先设定的抽象边界总会悄无声息地发生偏移。对于函数来说,这样的边界偏移意味着曾经视为一个整体、一个单元的行为,如今可能已经分化出两个甚至是多个不同的关注点。
范例
before:
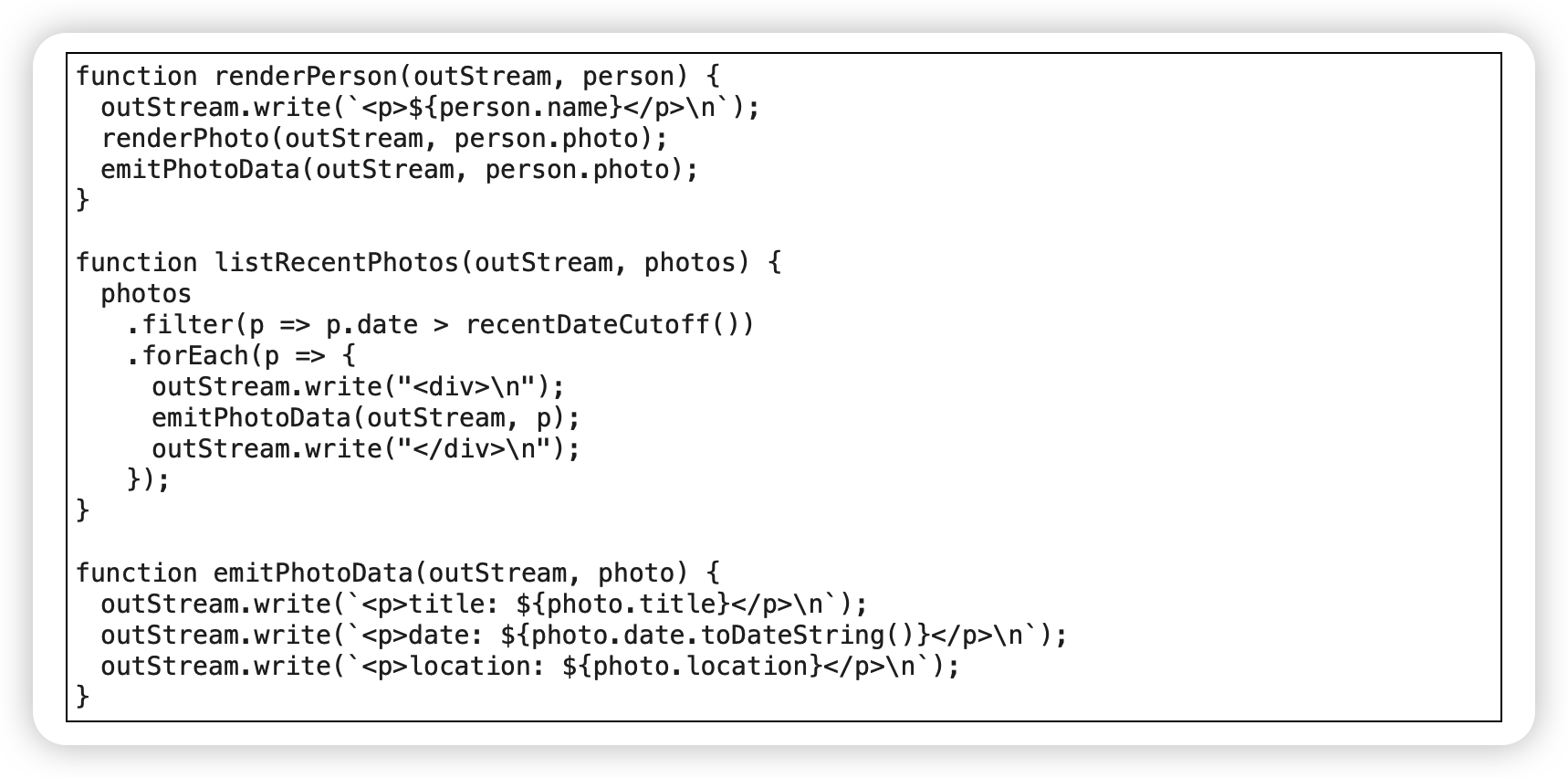
after:
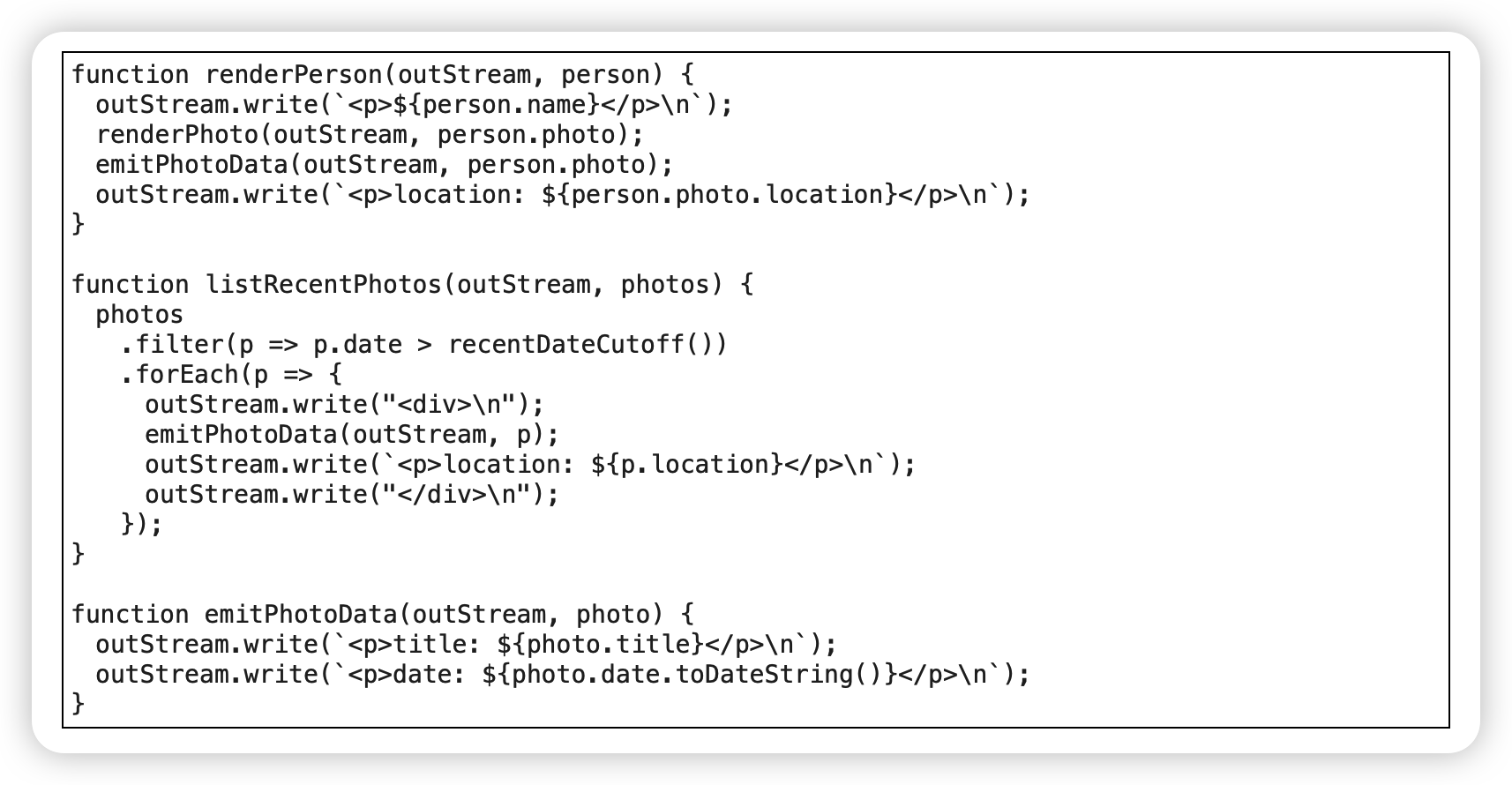
以函数调用取代内联代码(Replace Inline Code with Function Call)
移动语句(Slide Statements)
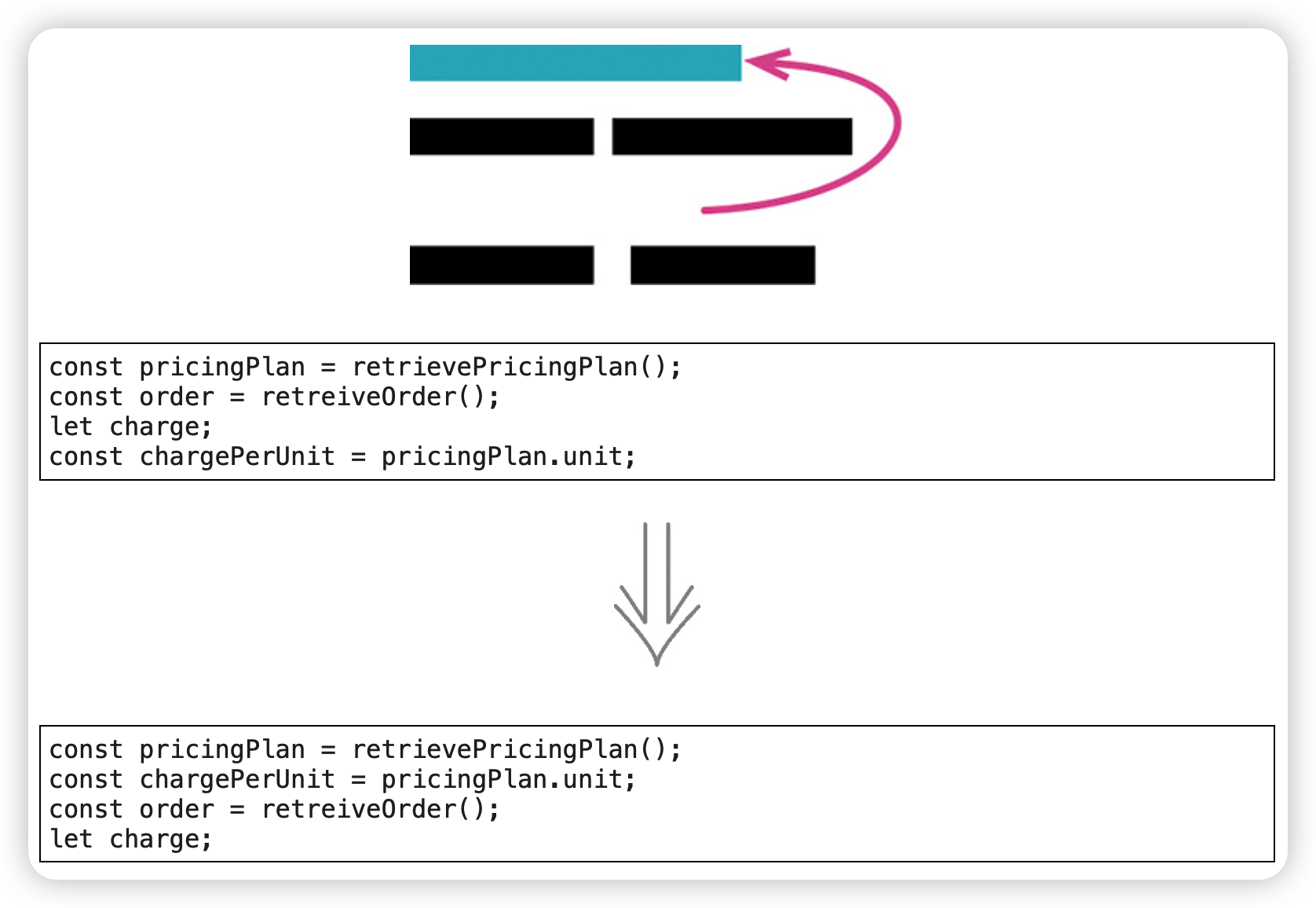
让存在关联的东西一起出现,可以使代码更容易理解。
命令查询分离原则(Command-Query Separation,CQS原则):
**查询:**方法返回结果,但不改变任何系统状态(无副作用)。
**命令:**方法没有结果,但会改变系统状态。
优点如下
查询类型的方法,对于调用者来讲不用在顾虑各个查询方法的调用顺序和次数(忽略性能的因素)。
命令类型的方法,从语义上来讲更准确。
范例
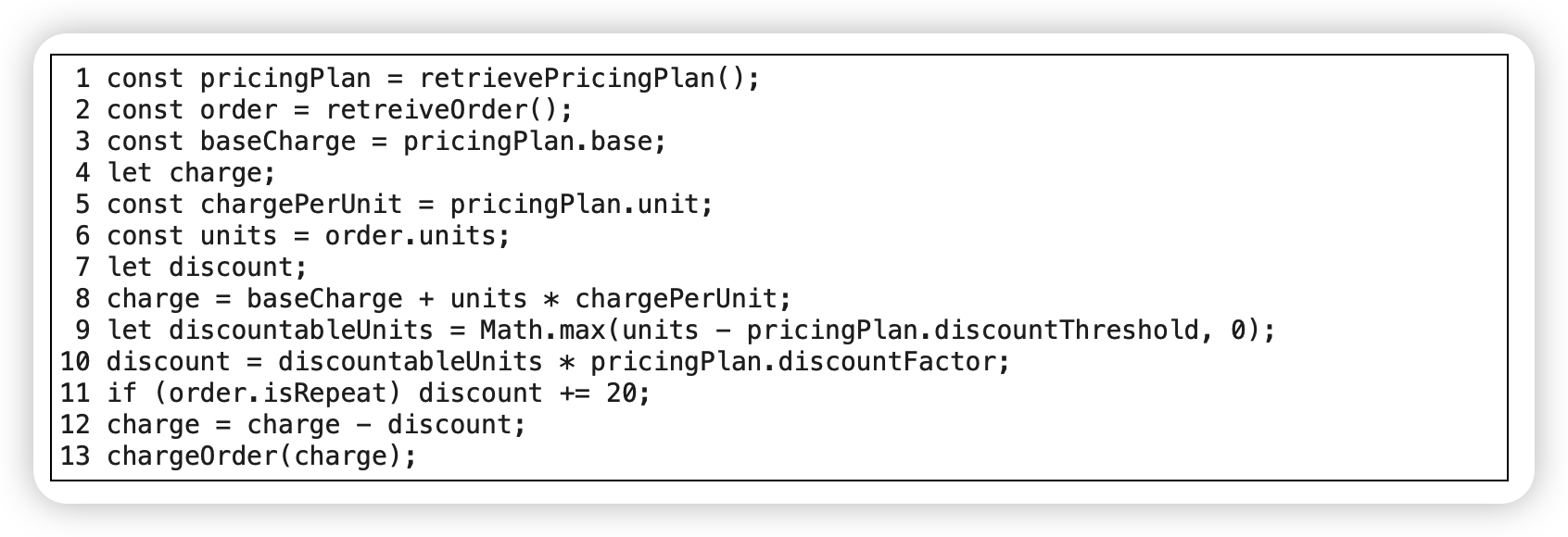
思考:哪些语句可以移动?
范例:包含条件逻辑的移动
before:

after:

拆分循环(Split Loop)
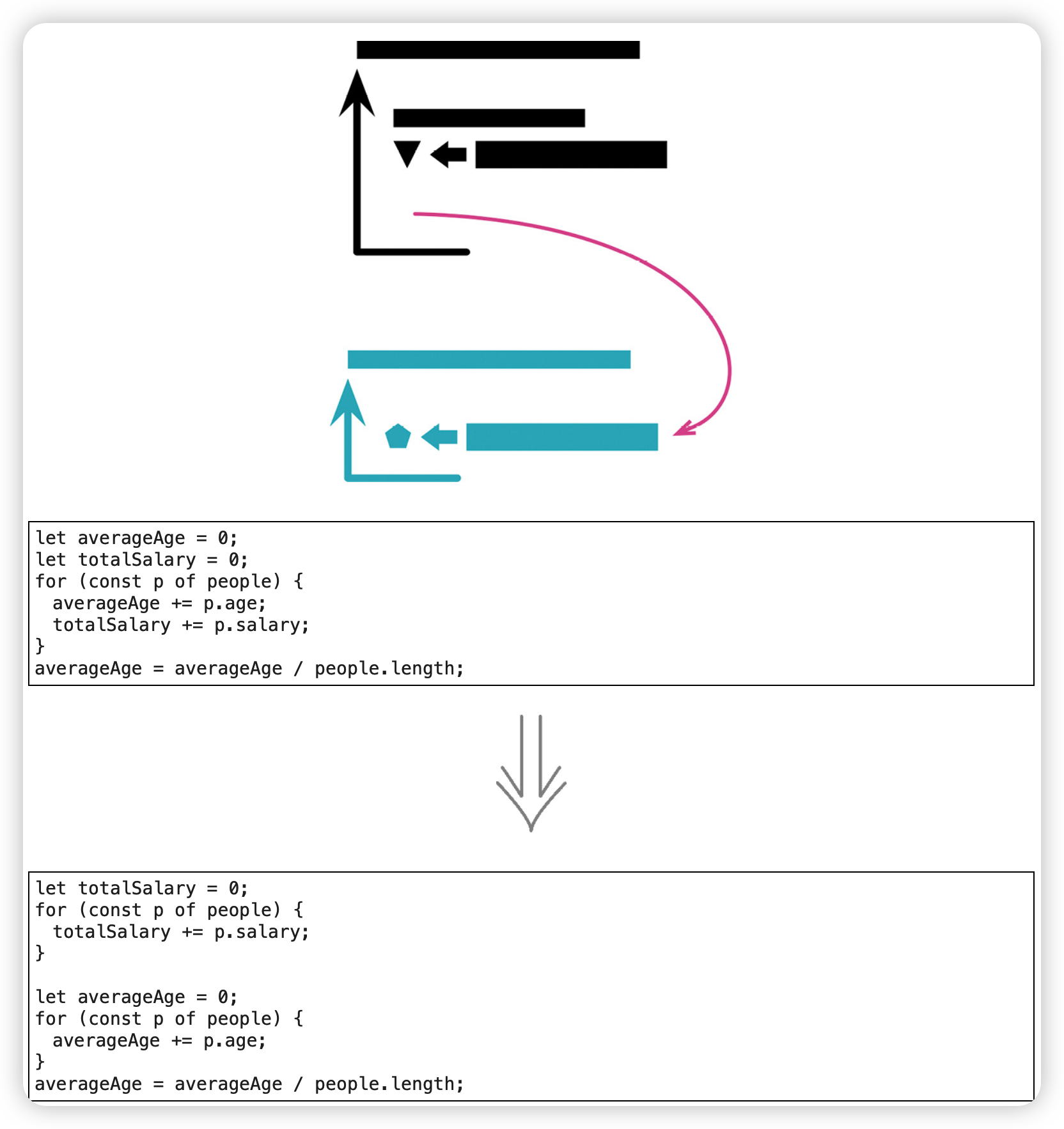
范例
before:
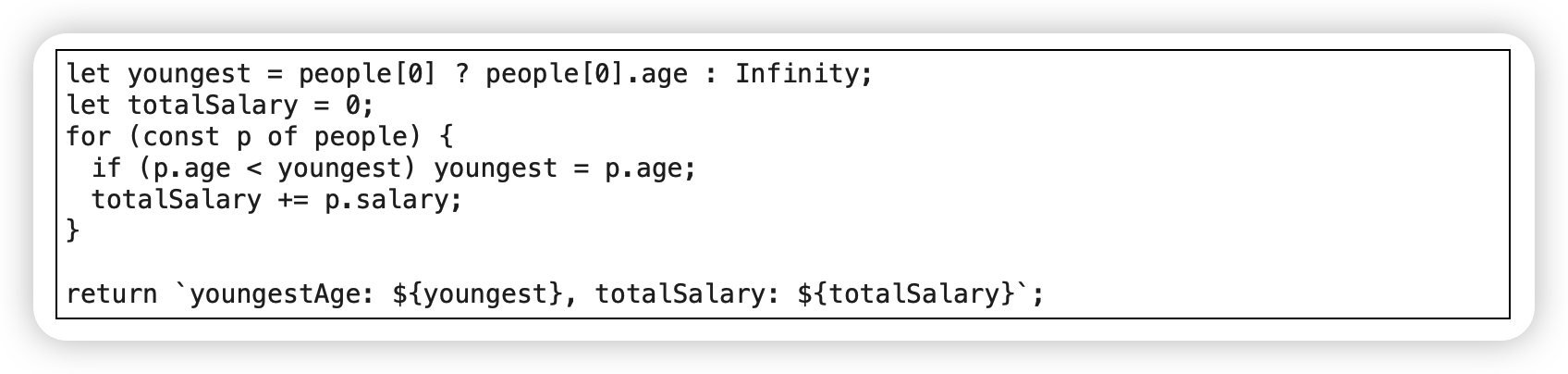
after:

以管道取代循环(Replace Loop with Pipeline)
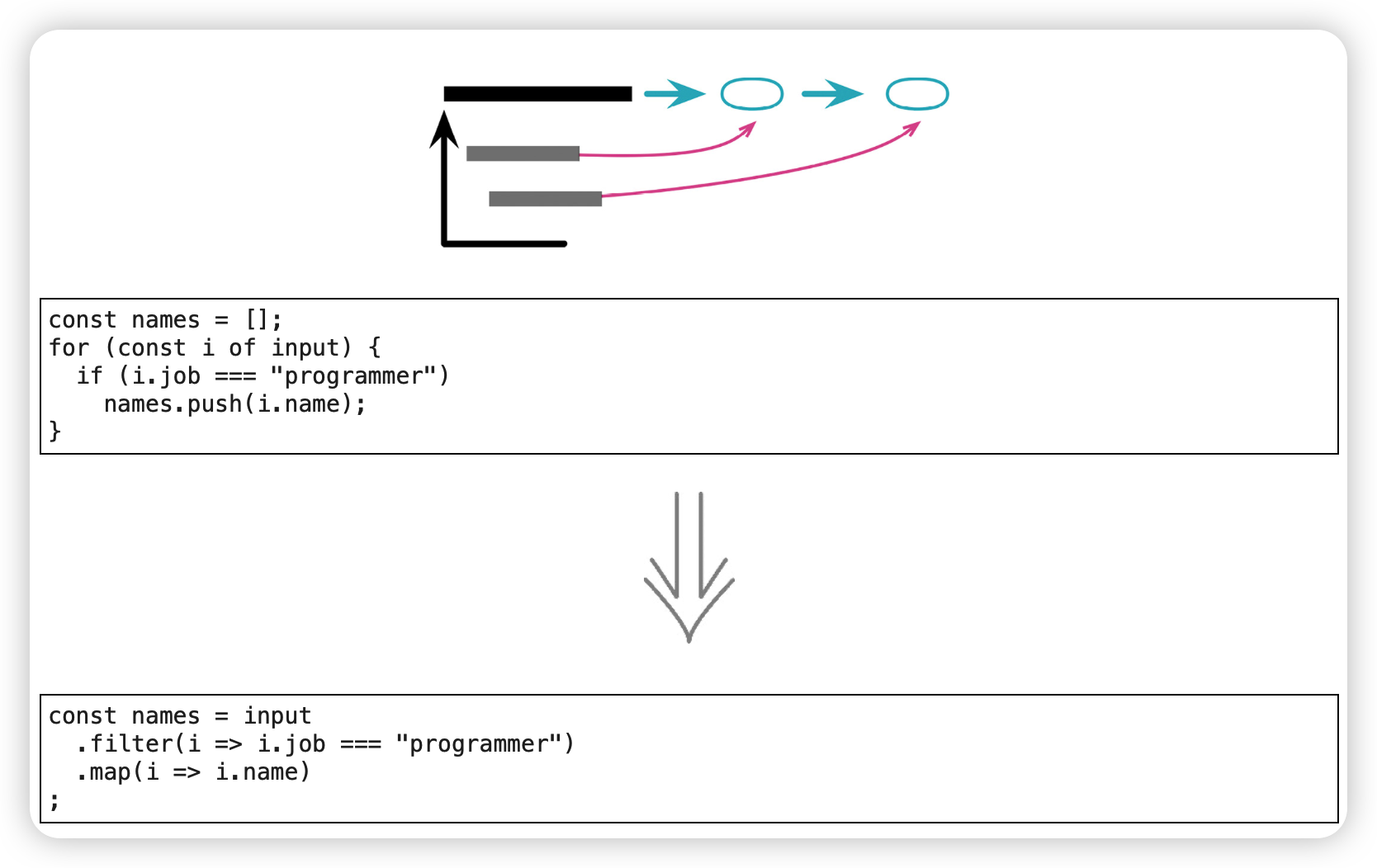
map运算是指用一个函数作用于输入集合的每一个元素上,将集合变换成另外一个集合的过程;filter运算是指用一个函数从输入集合中筛选出符合条件的元素子集的过程。运算得到的集合可以供管道的后续流程使用。
范例
before:

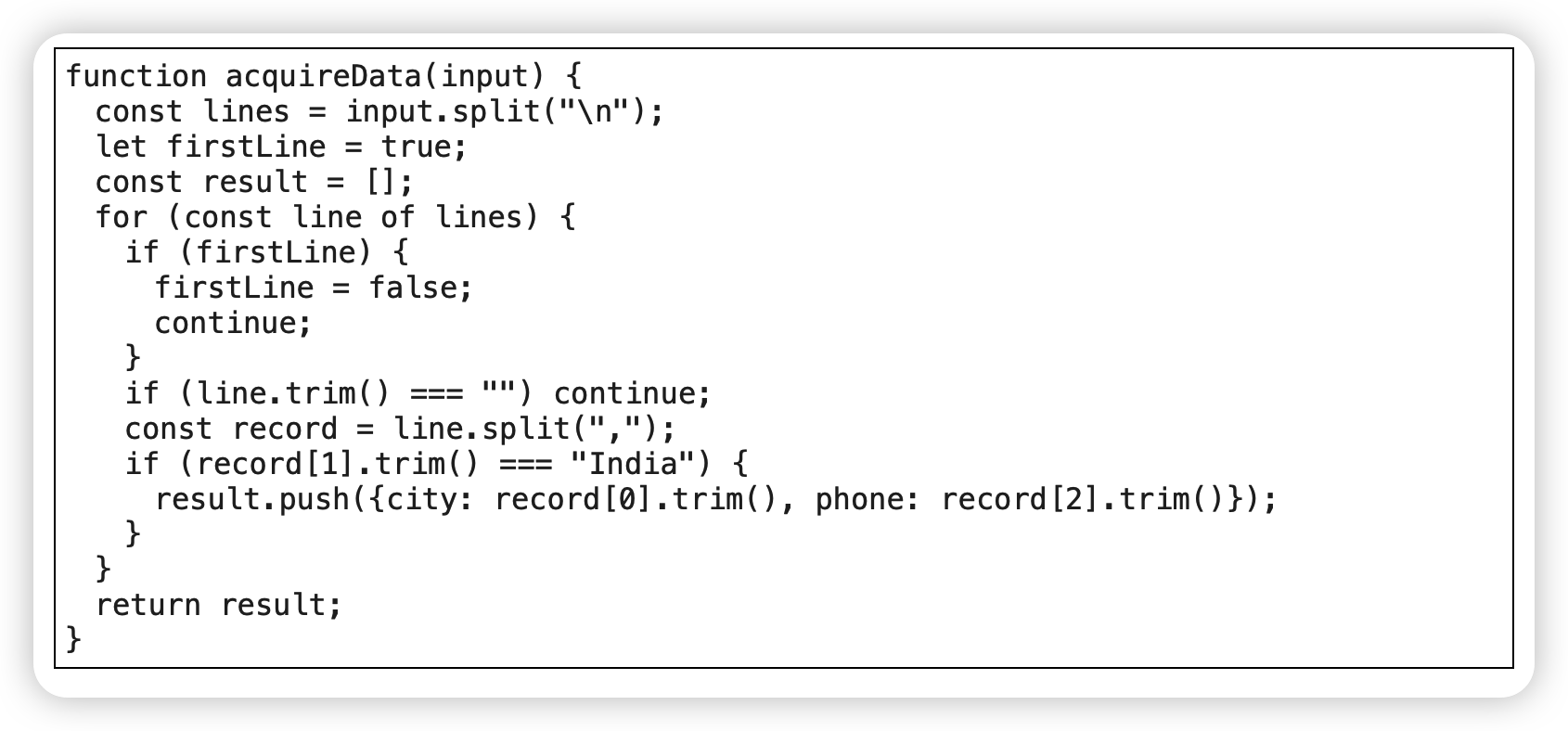
after:

移除死代码(Remove Dead Code)
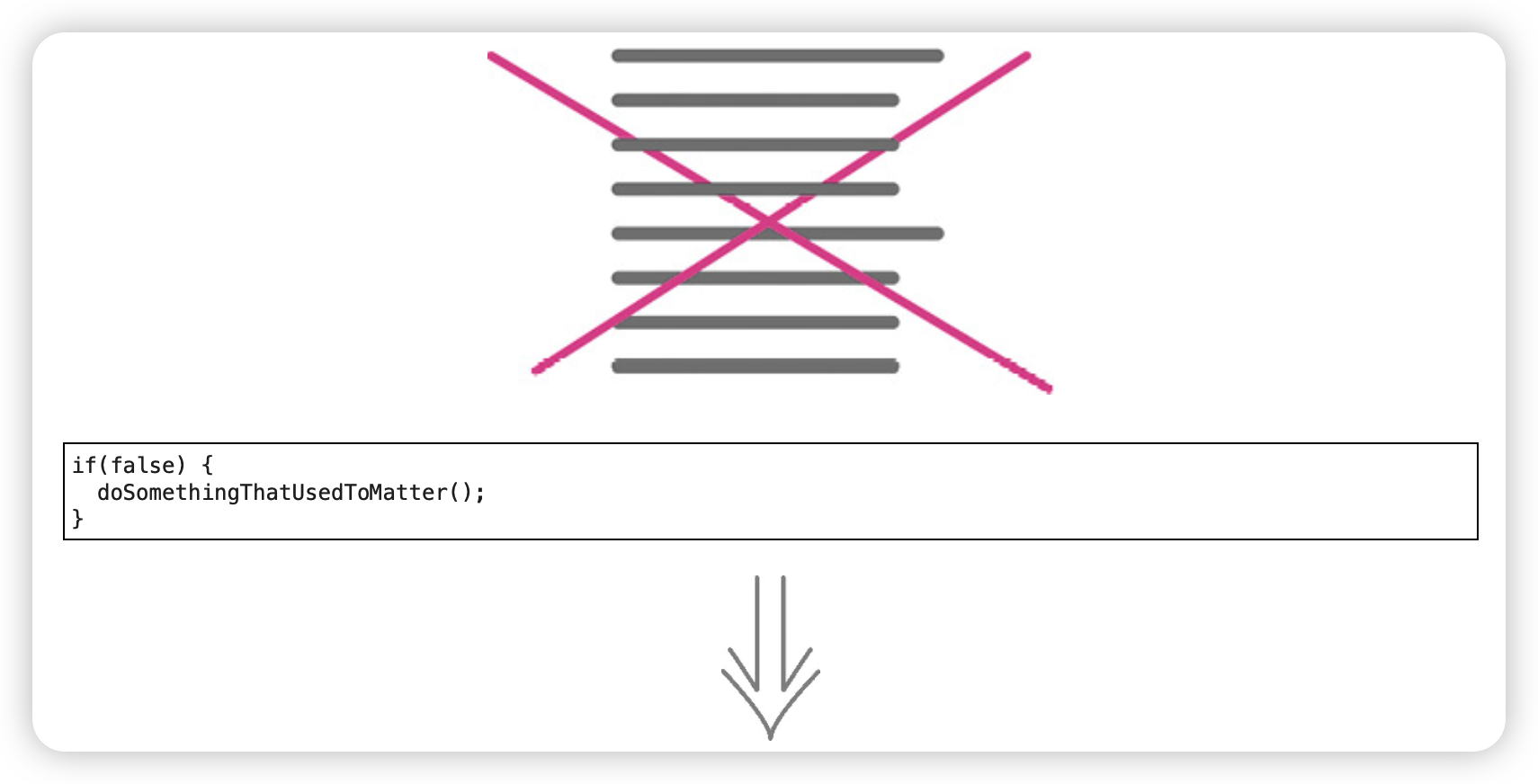
第9章 重新组织数据
拆分变量(Split Variable)
除"循环变量"和"结果收集变量"外,还有很多变量用于保存一段冗长代码的运算结果,以便稍后使用。这种**变量应该只被赋值一次。**如果它们被赋值超过一次,就意味它们在函数中承担了一个以上的责任。如果变量承担多个责任,它就应该被替换(分解)为多个变量,保持职责单一。
范例:对输入参数赋值
before:
after:
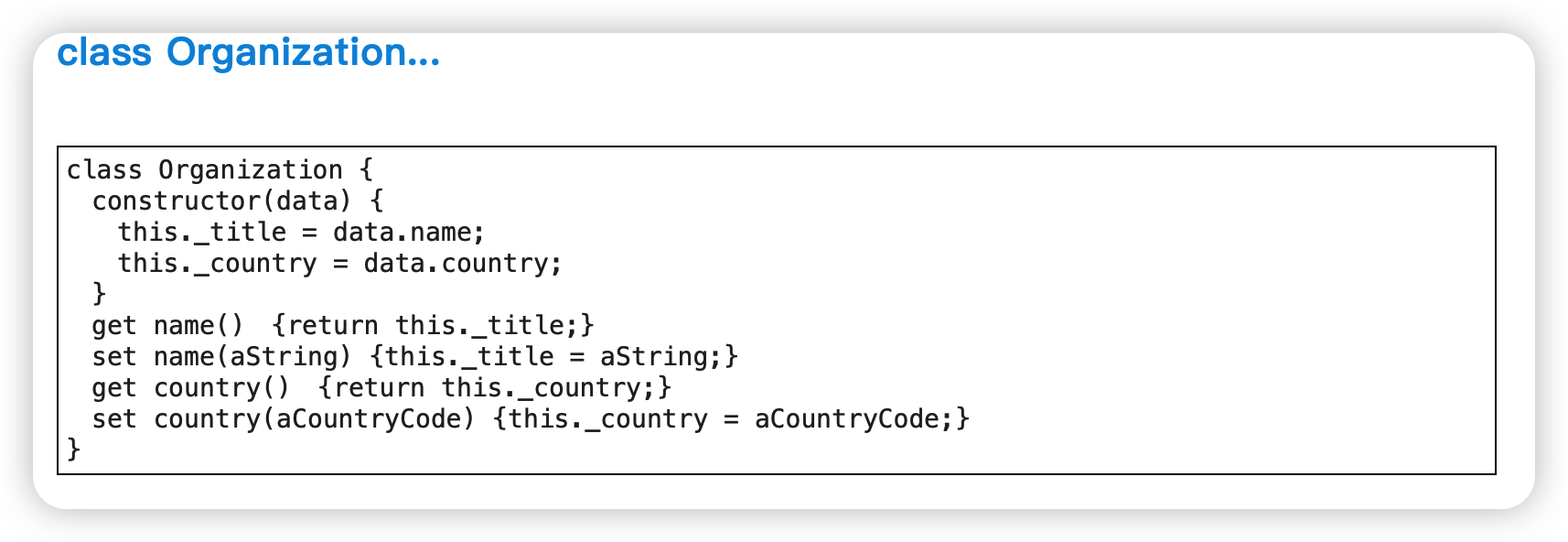
字段改名(Rename Field)
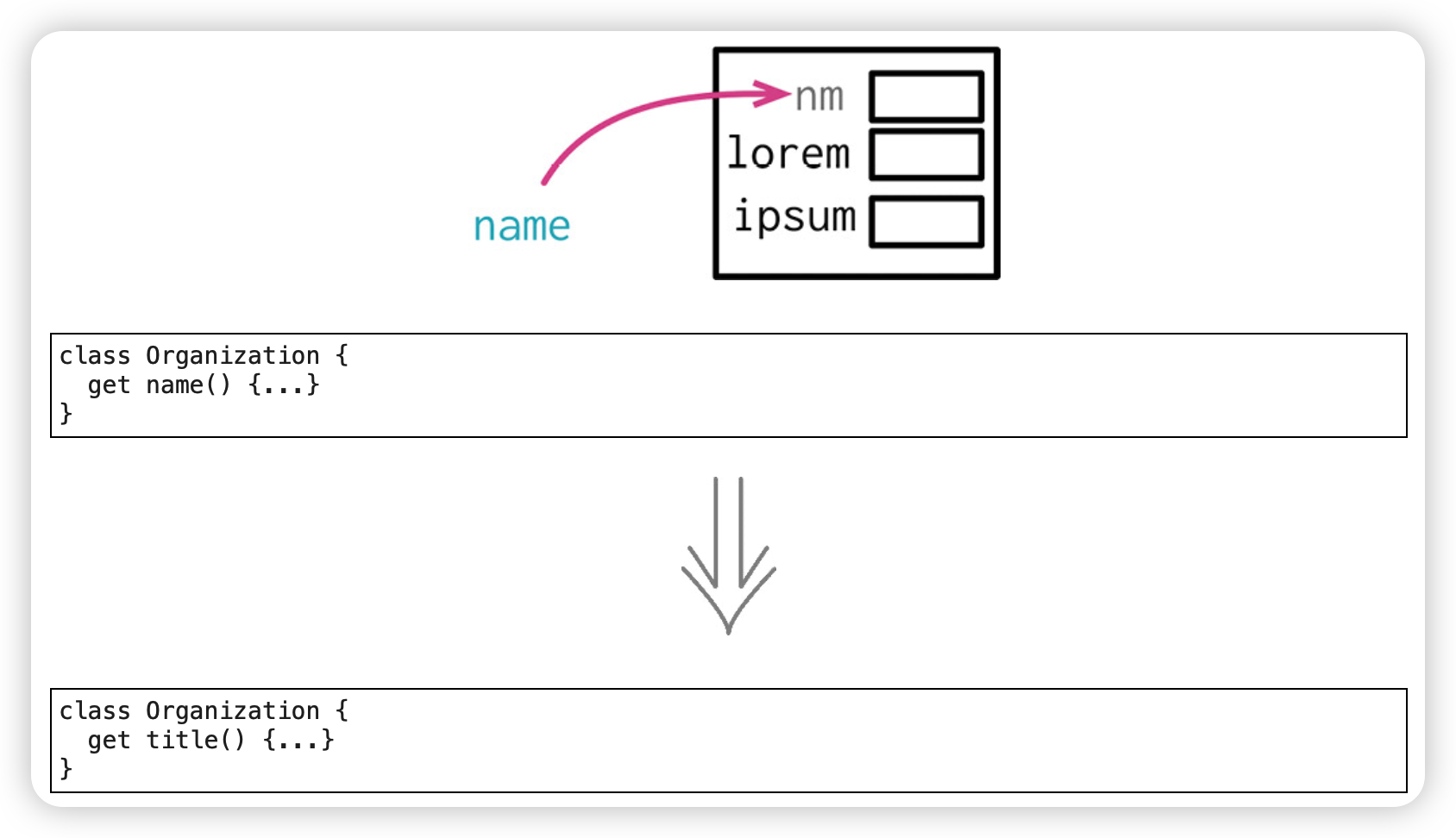
范例:给字段改名
before:
after:

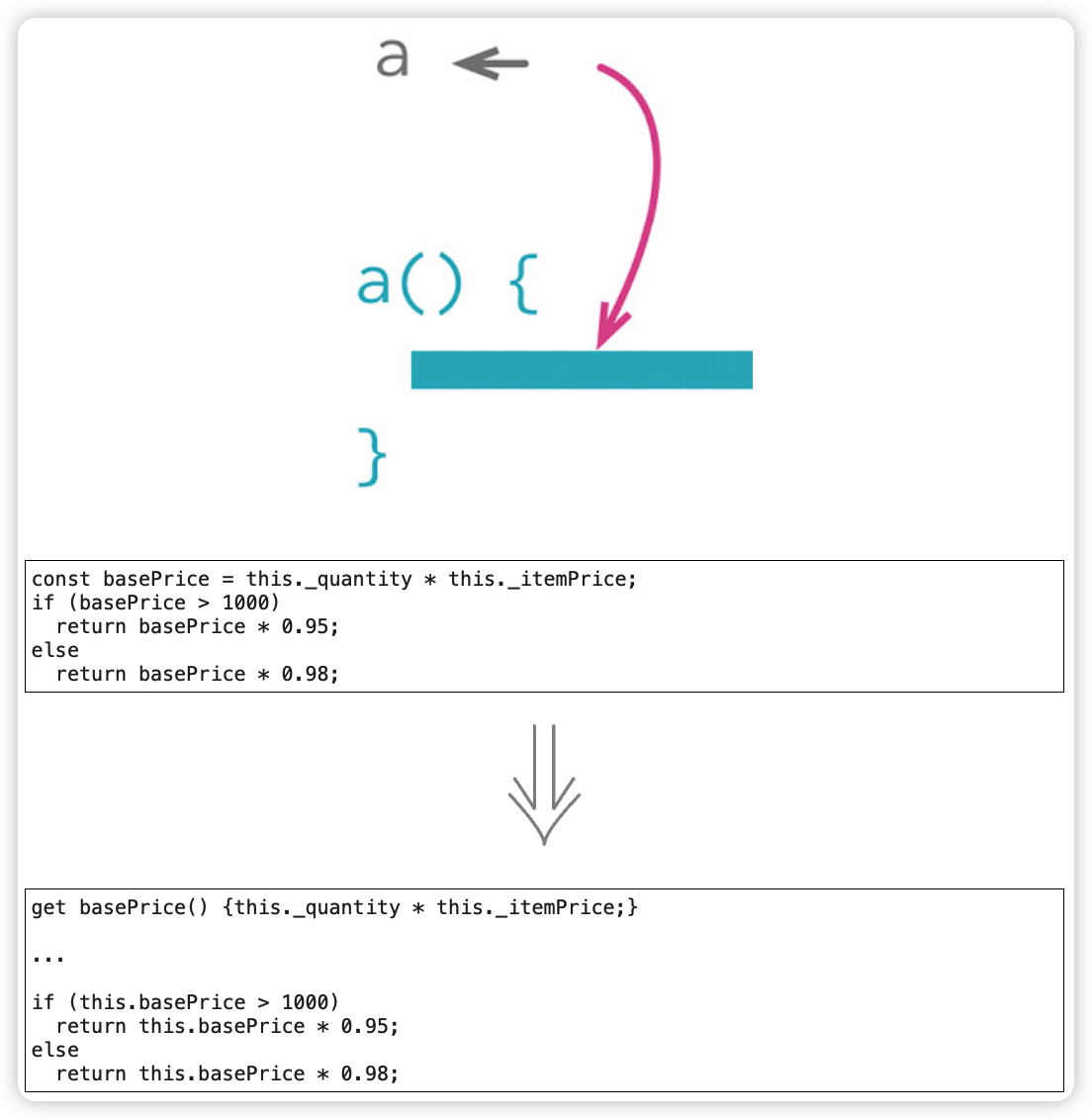
以查询取代派生变量(Replace Derived Variable with Query)
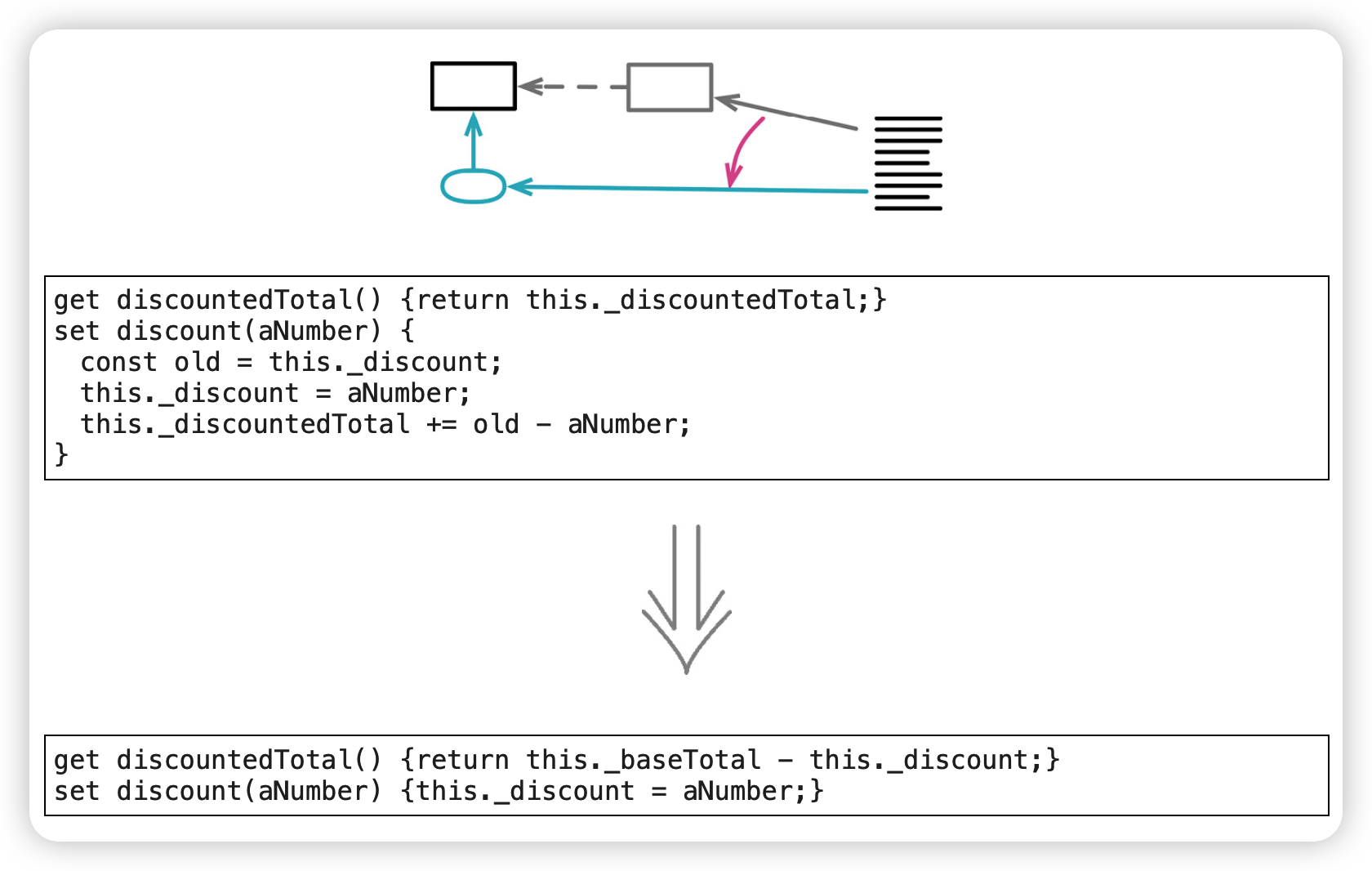
范例
即时计算,不必每次更新。
before:

after:


范例:不止一个数据来源
before:

after:

引入断言:
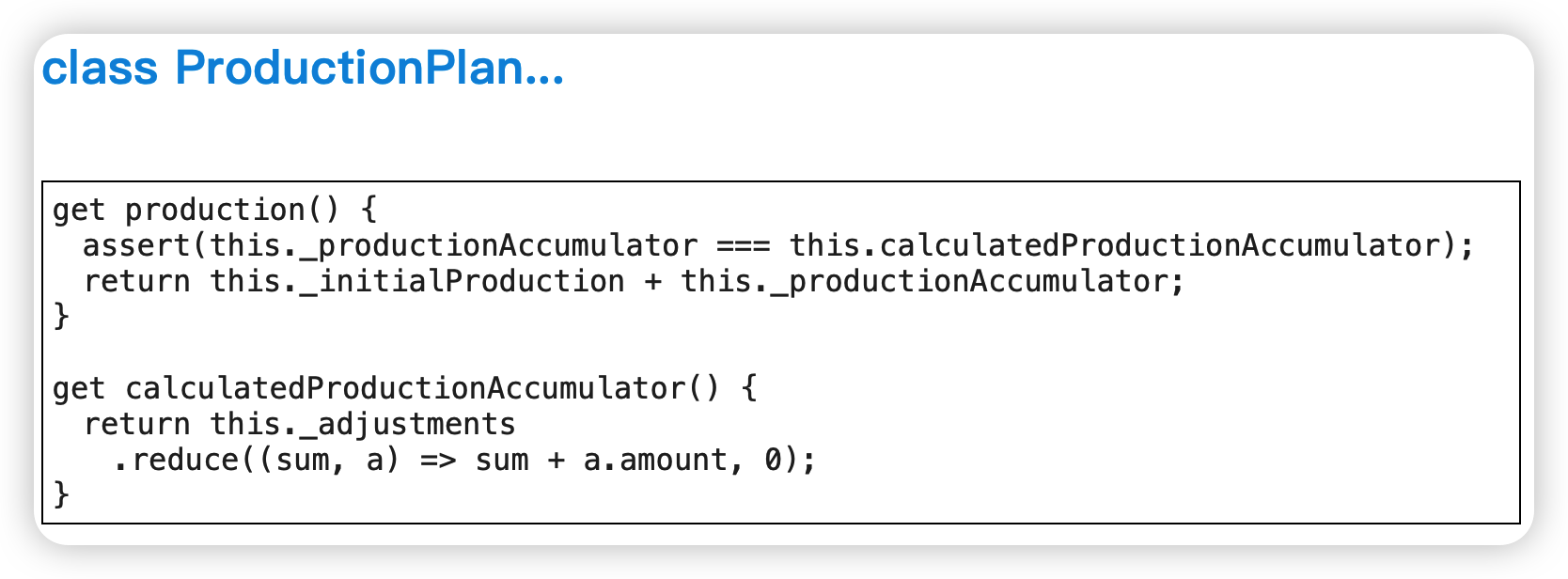
将引用对象改为值对象(Change Reference to Value)
不需要共享一个对象。
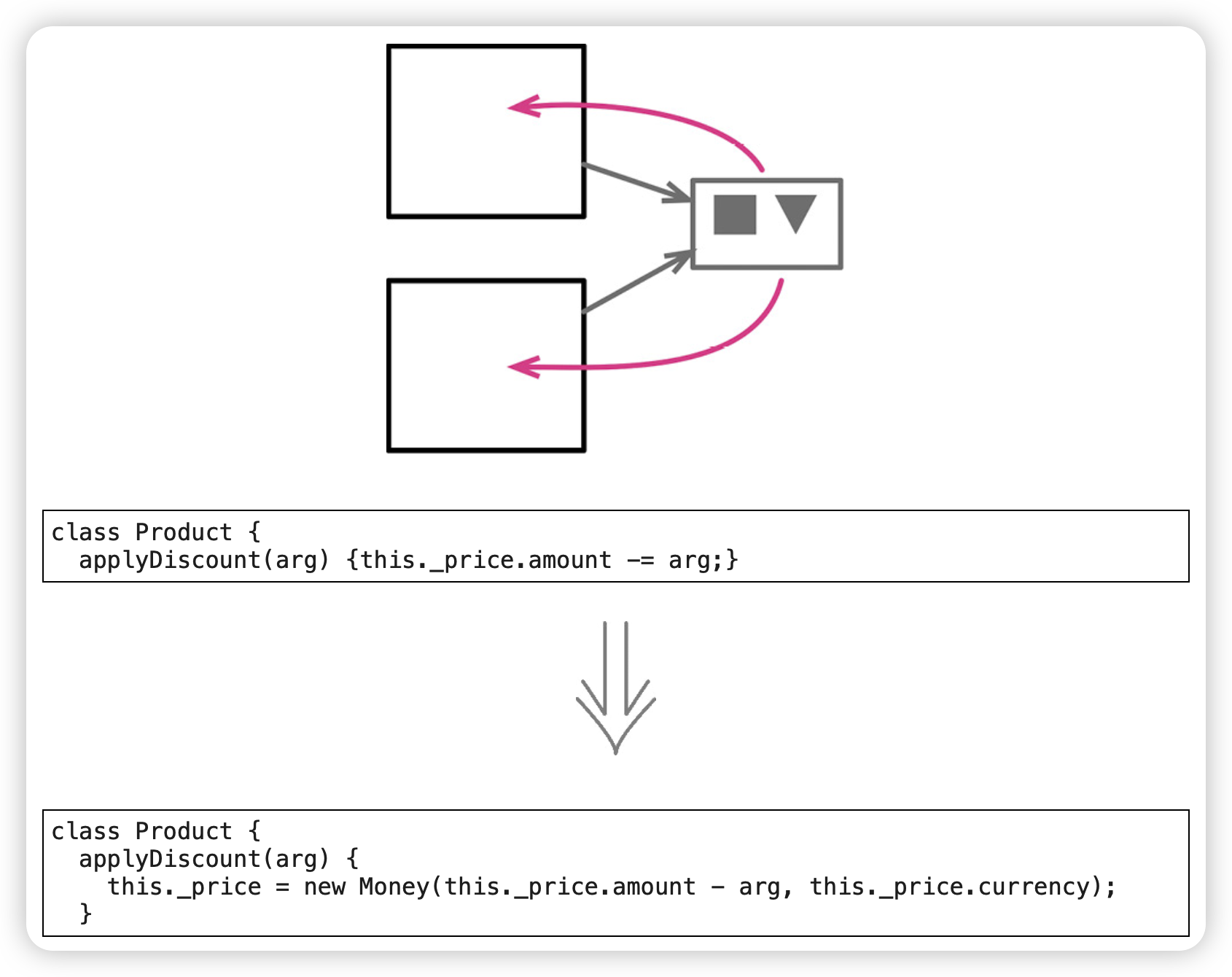
范例
before:

after:

将值对象改为引用对象(Change Value to Reference)
共享一个对象。
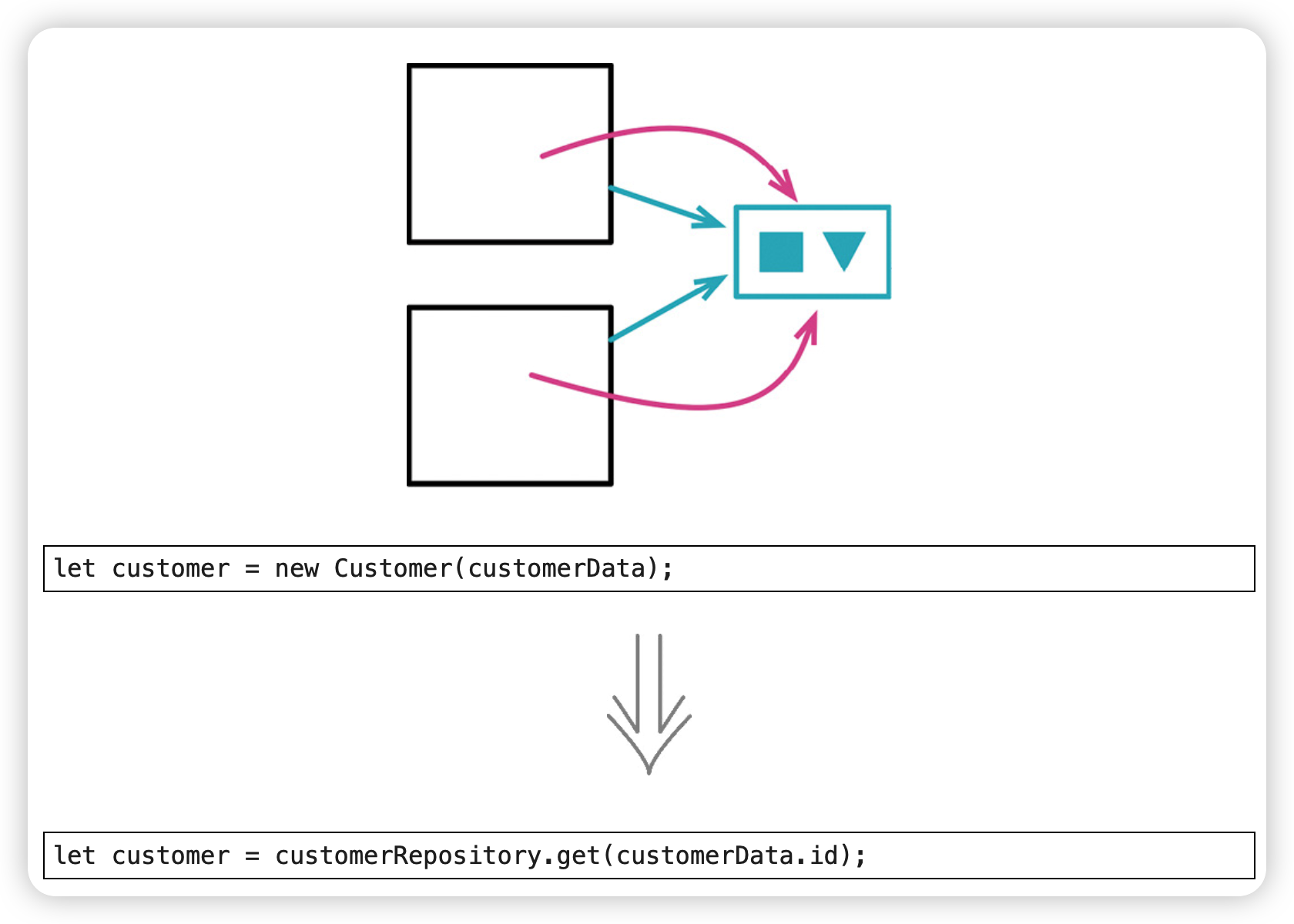
范例
before:

after:


存在的问题:构造函数与一个全局的仓库对象耦合。
改进的办法:将仓库对象作为参数传递给构造函数。
第10章 简化条件逻辑
分解条件表达式(Decompose Conditional)
程序之中,复杂的条件逻辑是最常导致复杂度上升的因素之一。
对于条件逻辑,将每个分支条件分解成新函数还可以带来更多好处:可以突出条件逻辑,更清楚地表明每个分支的作用,并且突出每个分支的原因。
注:实际上为提炼函数的一个应用场景。
范例
before:

after:
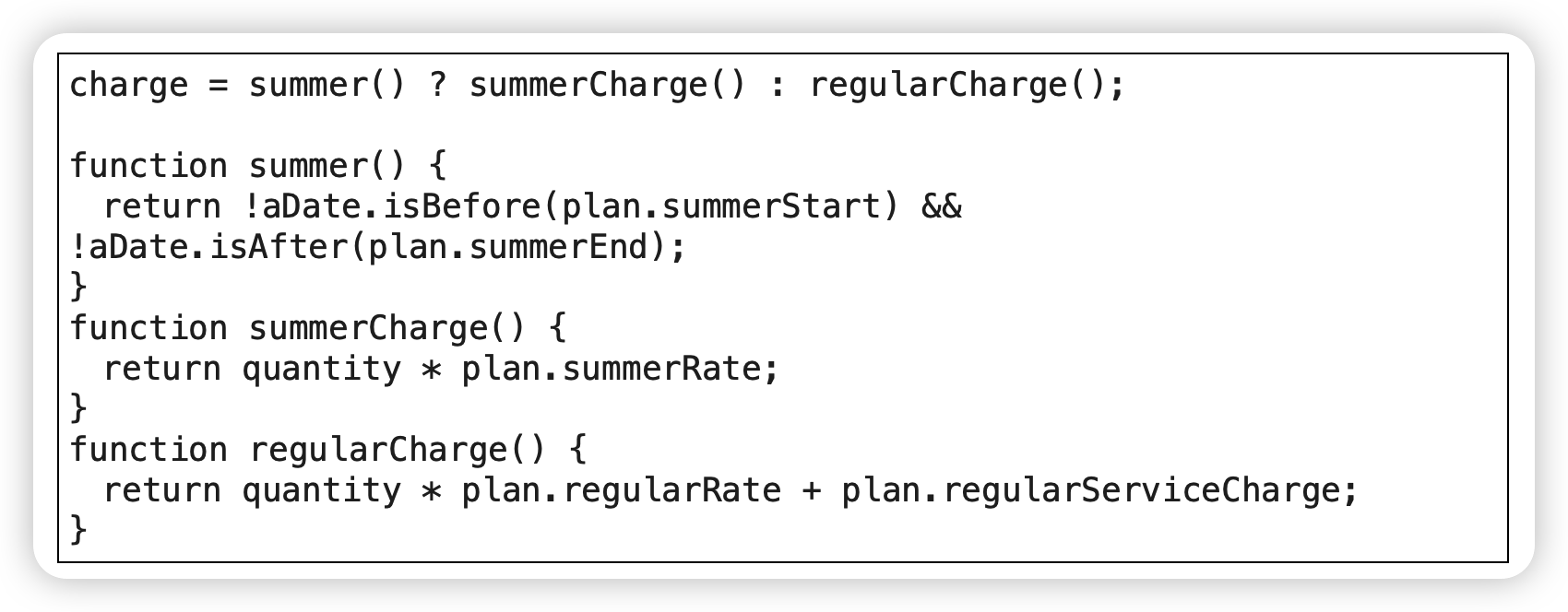
合并条件表达式(Consolidate Conditional Expression)
以卫语句取代嵌套条件表达式(Replace Nested Conditional with Guard Clauses)
如果两条分支都是正常行为,就应该使用形如if...else...的条件表达式;如果某个条件极其罕见,就应该单独检查该条件,并在该条件为真时立刻从函数中返回。这样的单独检查常常被称为"卫语句”(guard clauses)。
如果使用if-then-else结构,则对if分支和else分支的重视是同等的;以卫语句取代嵌套条件表达式的精髓就是:给某一条分支以特别的重视。
“每个函数只能有一个入口和一个出口"的观念未必有用,保持代码清晰才是最关键的。
范例
before
after
范例:将条件反转
初始
反转
合并条件表达式
删除可变变量
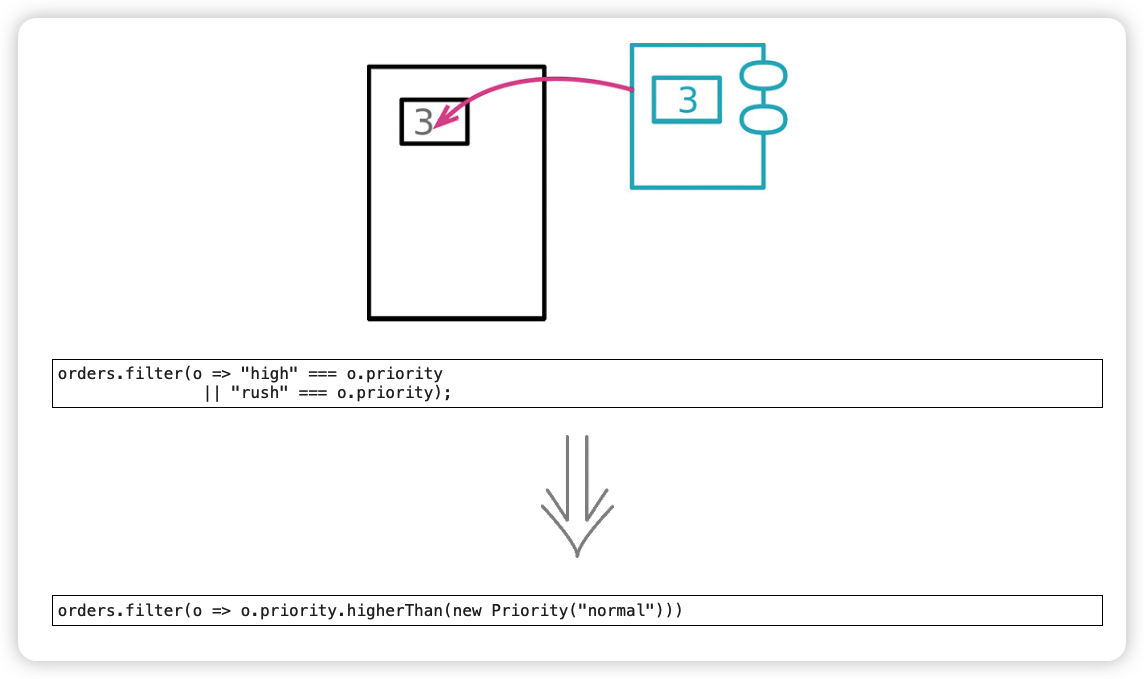
以多态取代条件表达式(Replace Conditional with Polymorphism)
引入特例(Introduce Special Case)
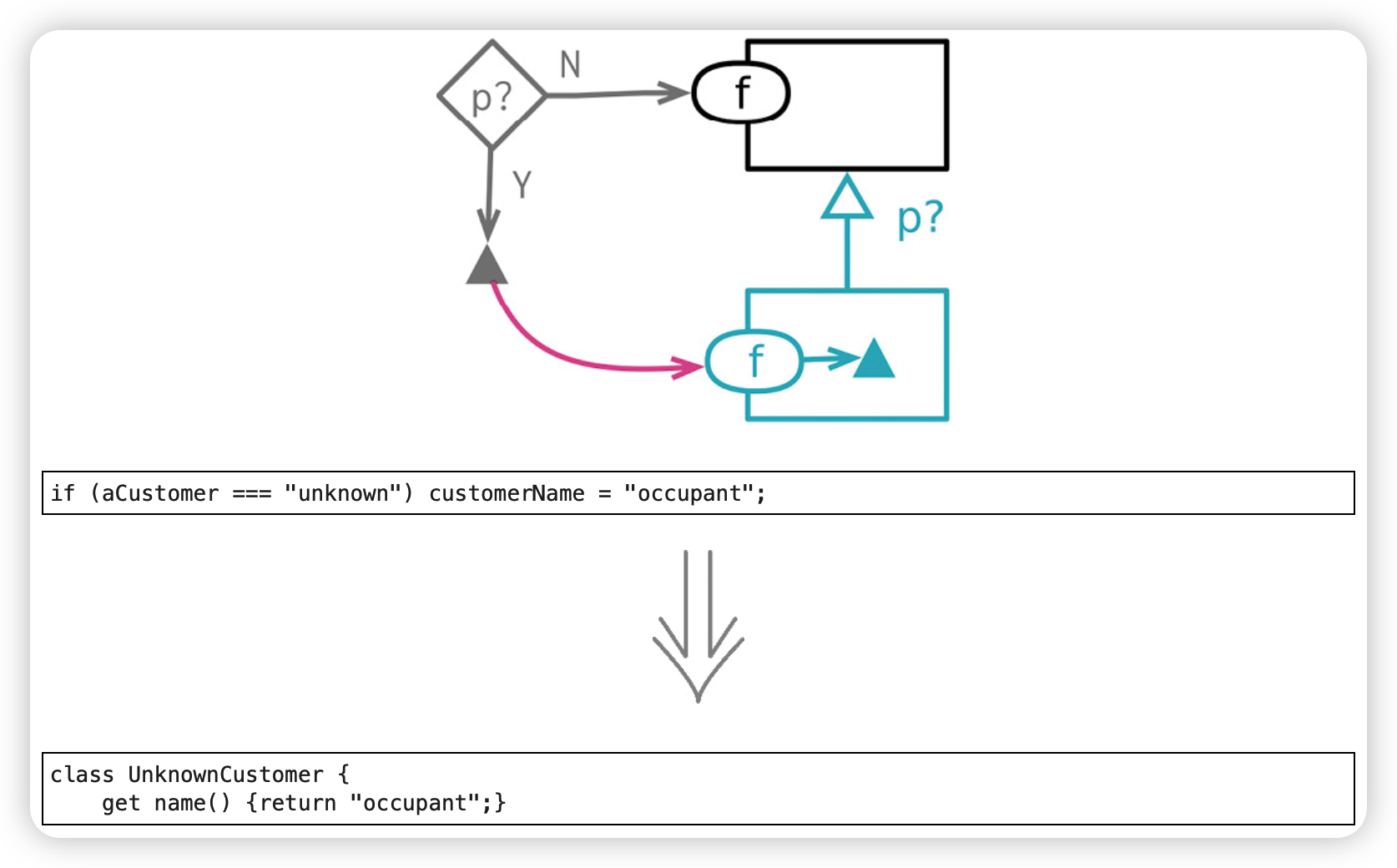
“特例”(Special Case)模式:创建一个特例元素,用以表达对这种特例的共用行为的处理,从而用一个函数调用取代大部分特例检查逻辑。
引入断言(Introduce Assertion)
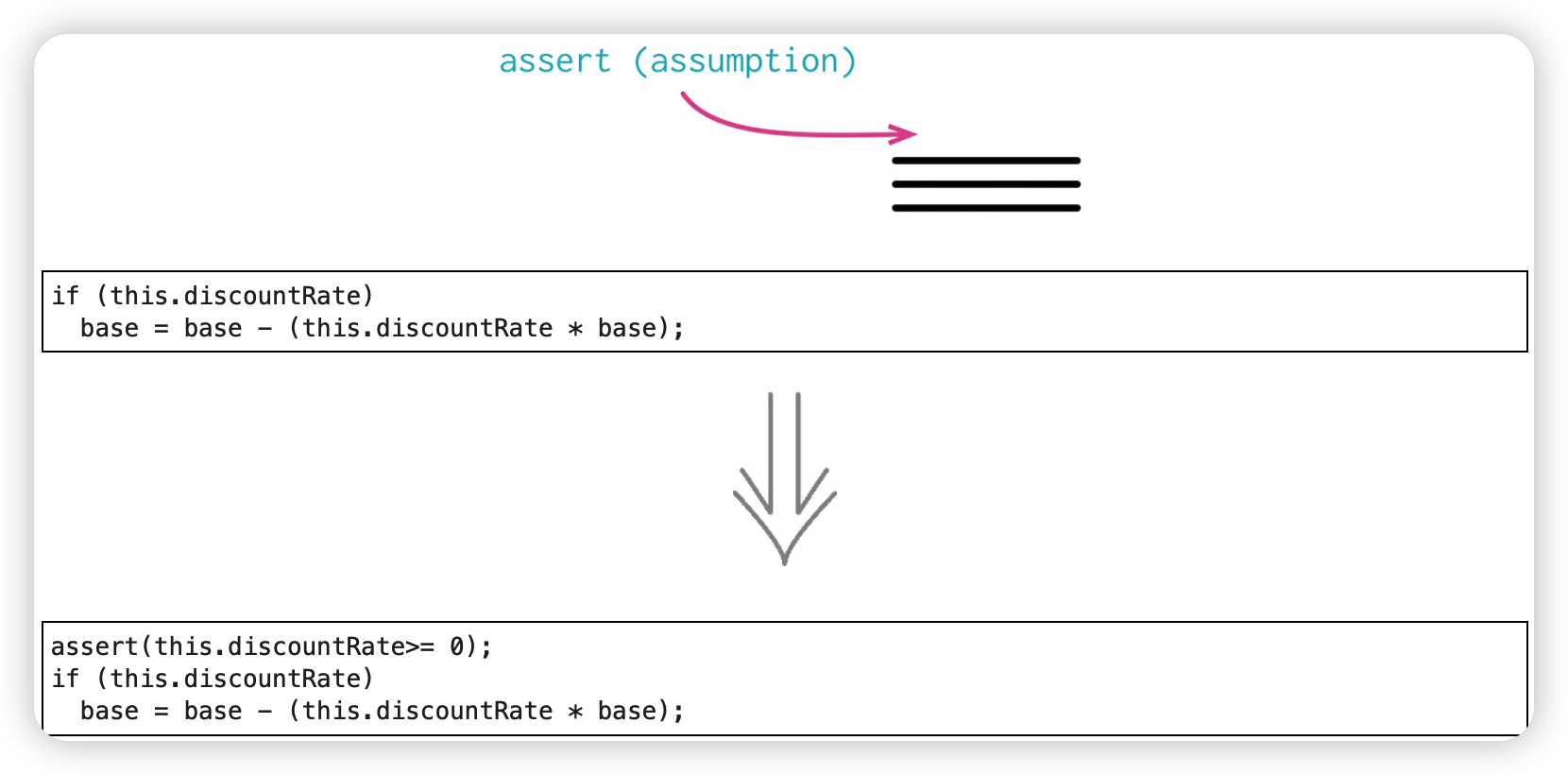
第11章 重构API
将查询函数和修改函数分离(Separate Query from Modifier)
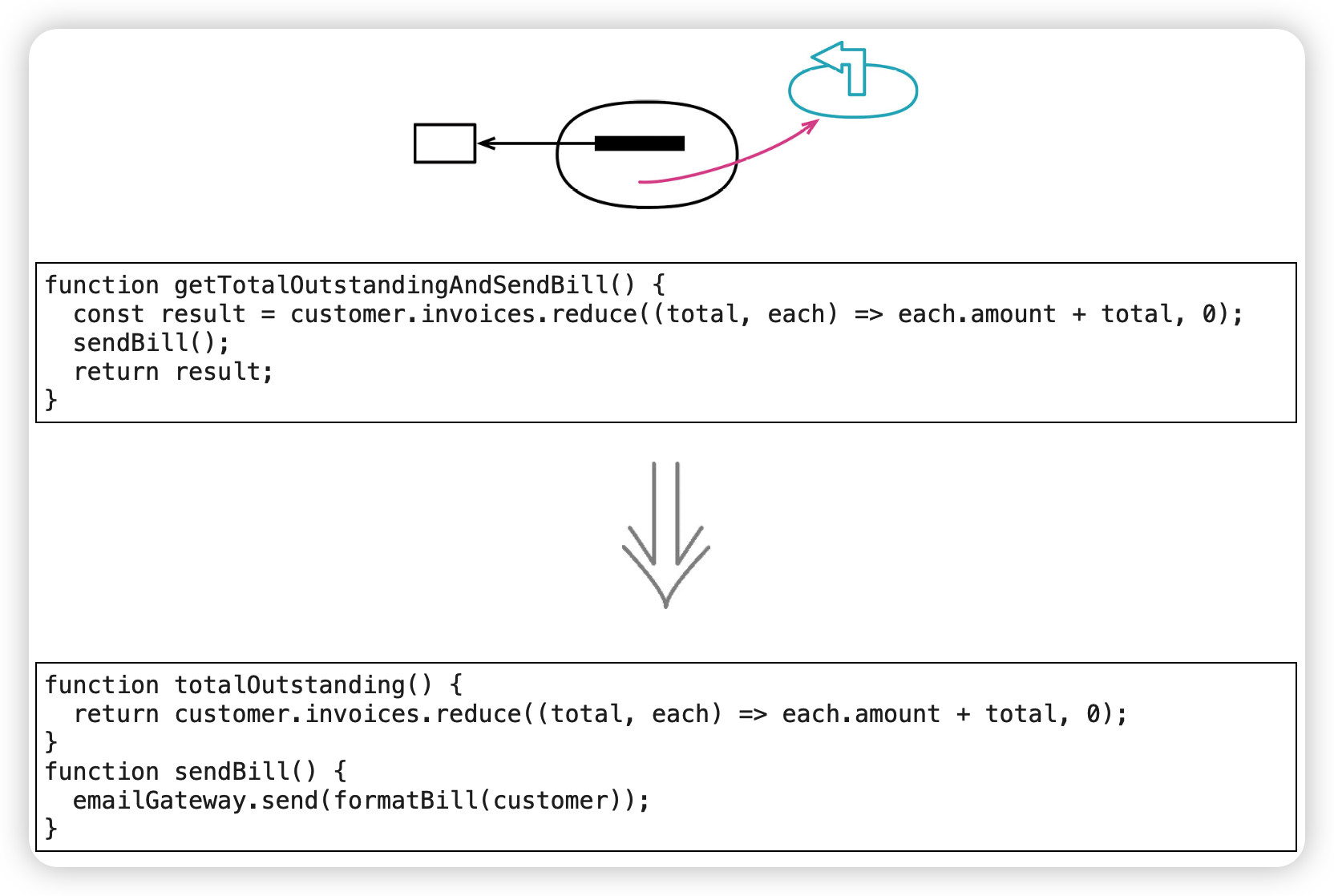
范例
before
After

函数参数化(Parameterize Function)

范例
before
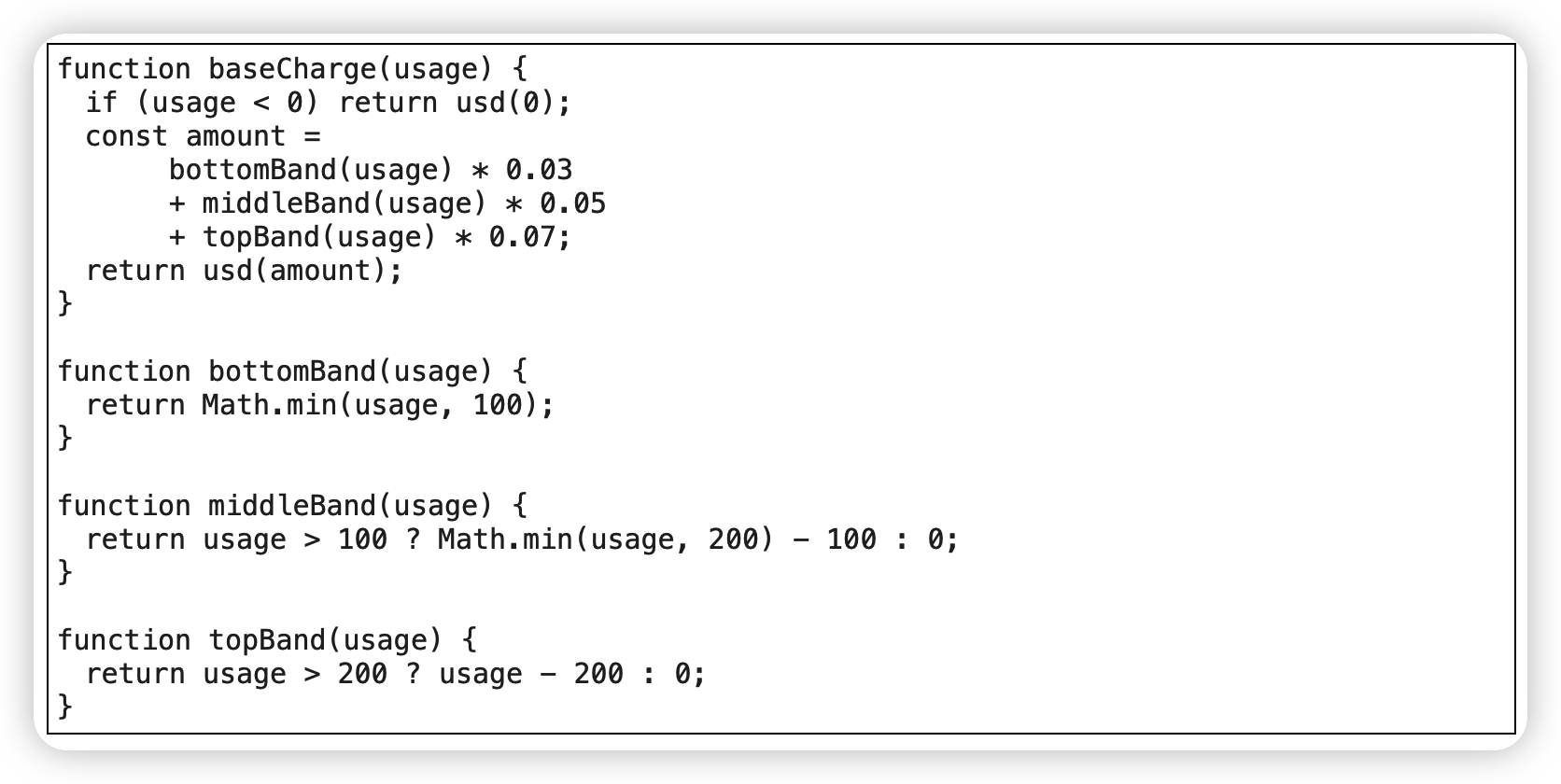
After
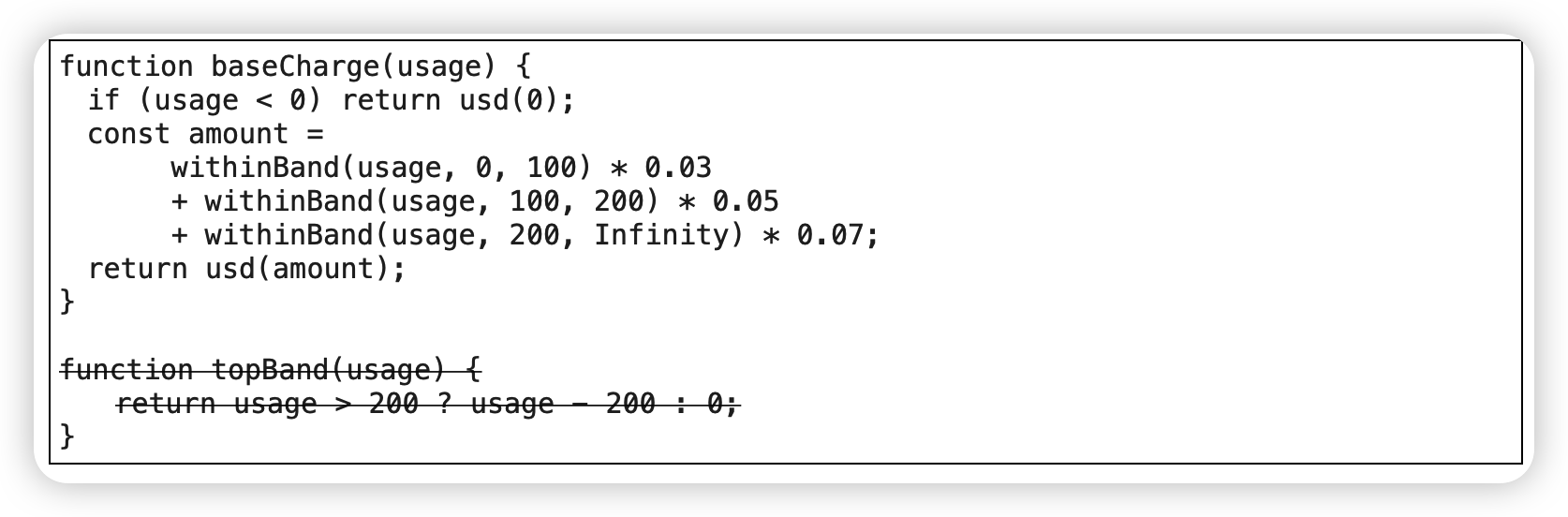
 g)
g)
移除标记参数(Remove Flag Argument)
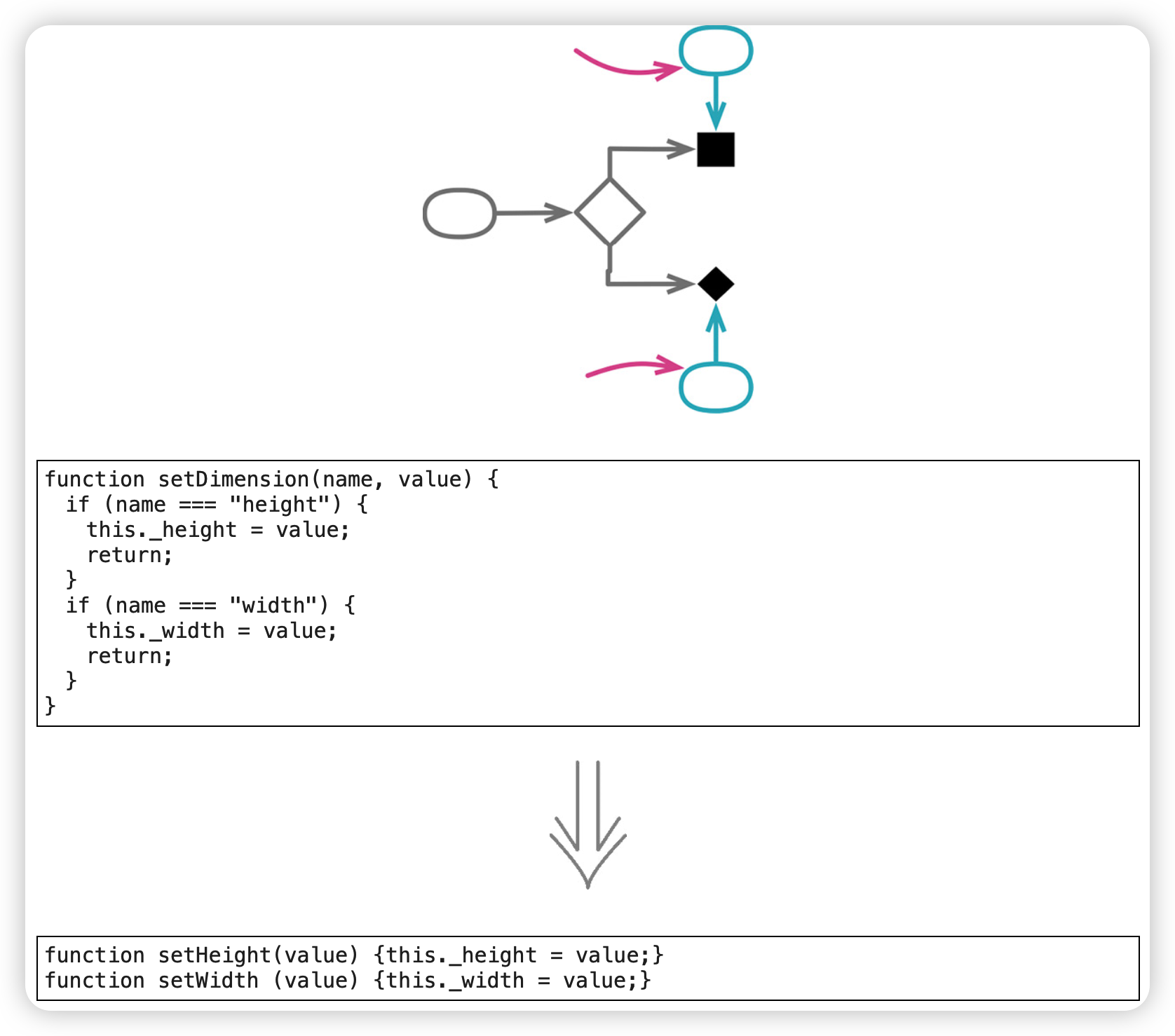
“标记参数"是这样的一种参数:调用者用它来指示被调函数应该执行哪一部分逻辑。
范例
Before
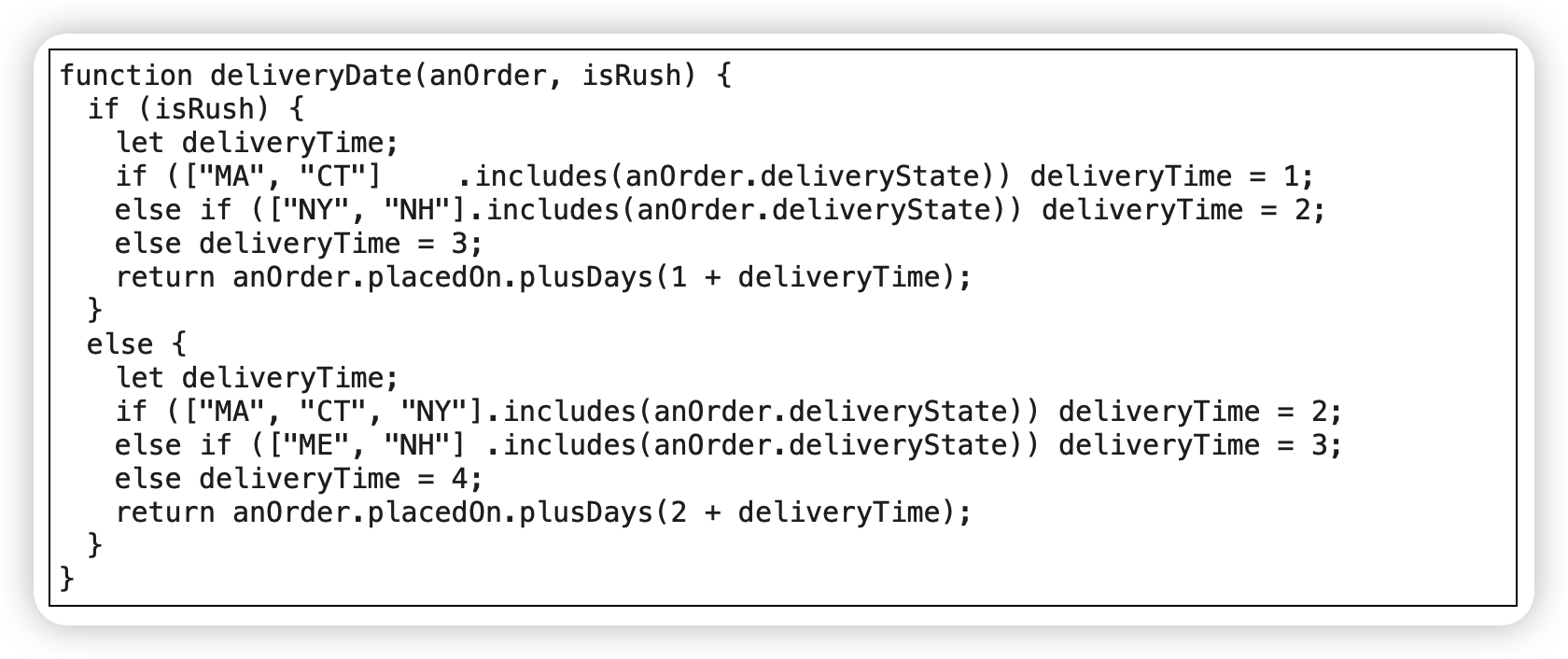
After
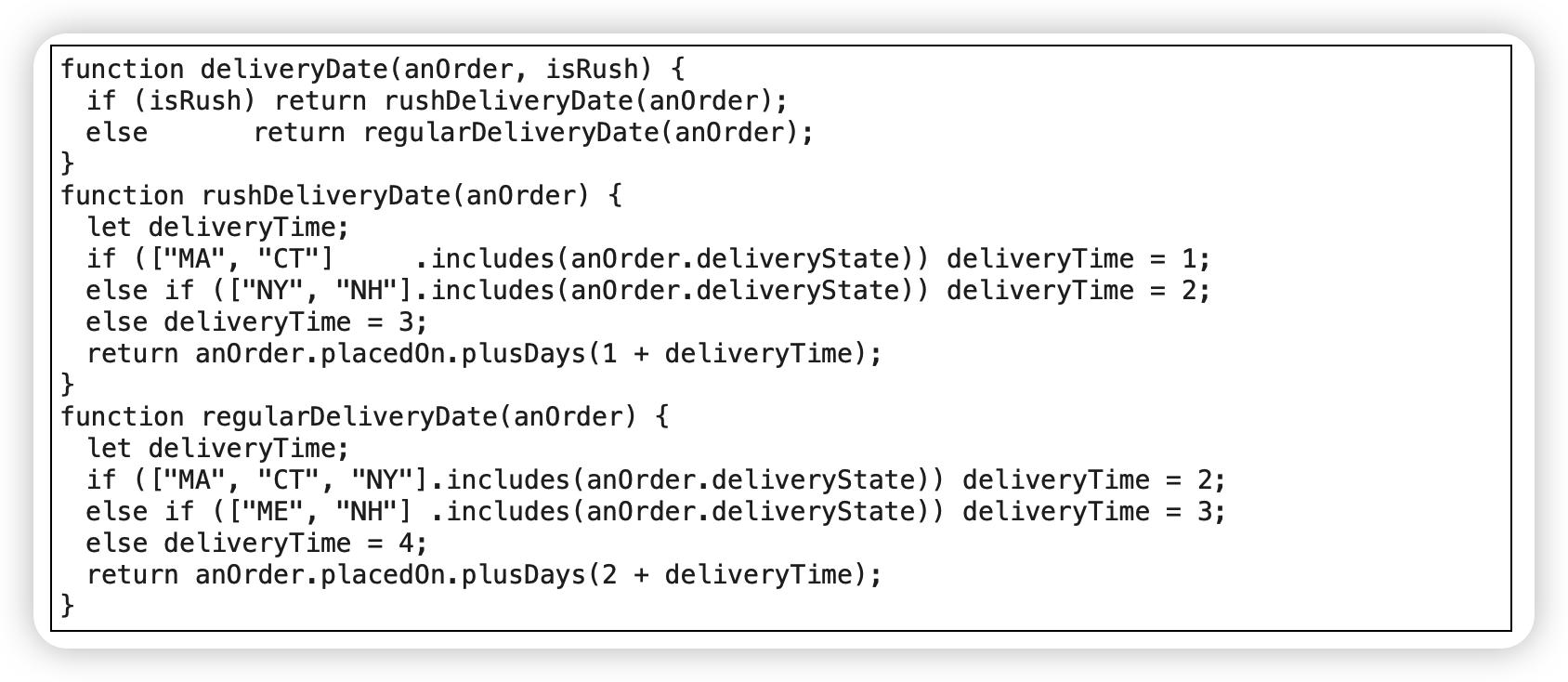
保持对象完整(Preserve Whole Object)
减少函数参数长度,方便后续拓展。
以查询取代参数(Replace Parameter with Query)
函数的参数列表应该总结该函数的可变性,标示出函数可能体现出行为差异的主要方式。和任何代码中的语句一样,参数列表应该尽量避免重复,并且参数列表越短就越容易理解。
使用场景:调用函数时传入了一个值,而这个值由函数自己来获得也是同样容易
什么是"同样容易”:函数可以承担这份原本由调用方所承担的"获得正确的参数值"的责任。
什么时候不适用:移除参数可能会给函数体增加不必要的依赖关系。
留意:如果在处理的函数具有引用透明性(referential transparency,即,不论任何时候,只要传入相同的参数值,该函数的行为永远一致),这样的函数既容易理解又容易测试,不会去除参数,让它访问一个可变的全部变量。
以参数取代查询(Replace Query with Parameter)
好处:改变依赖关系,去掉令人不快的引用。
注意:要考虑责任分配问题,会增加函数调用者的复杂度,而设计接口时又需要考虑易用性。
移除设值函数(Remove Setting Method)
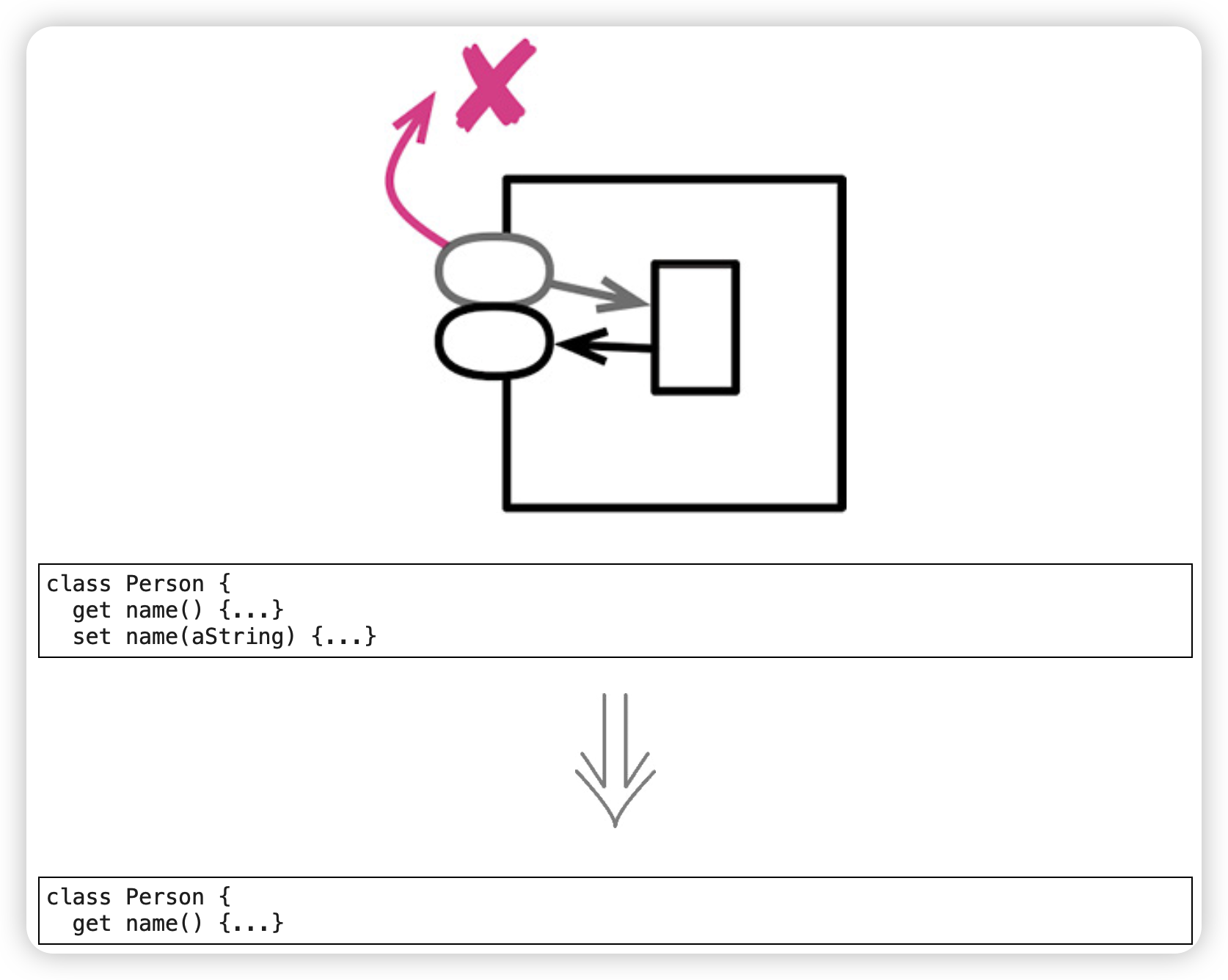
去除不必要的设值函数。
以工厂函数取代构造函数(Replace Constructor with Factory Function)
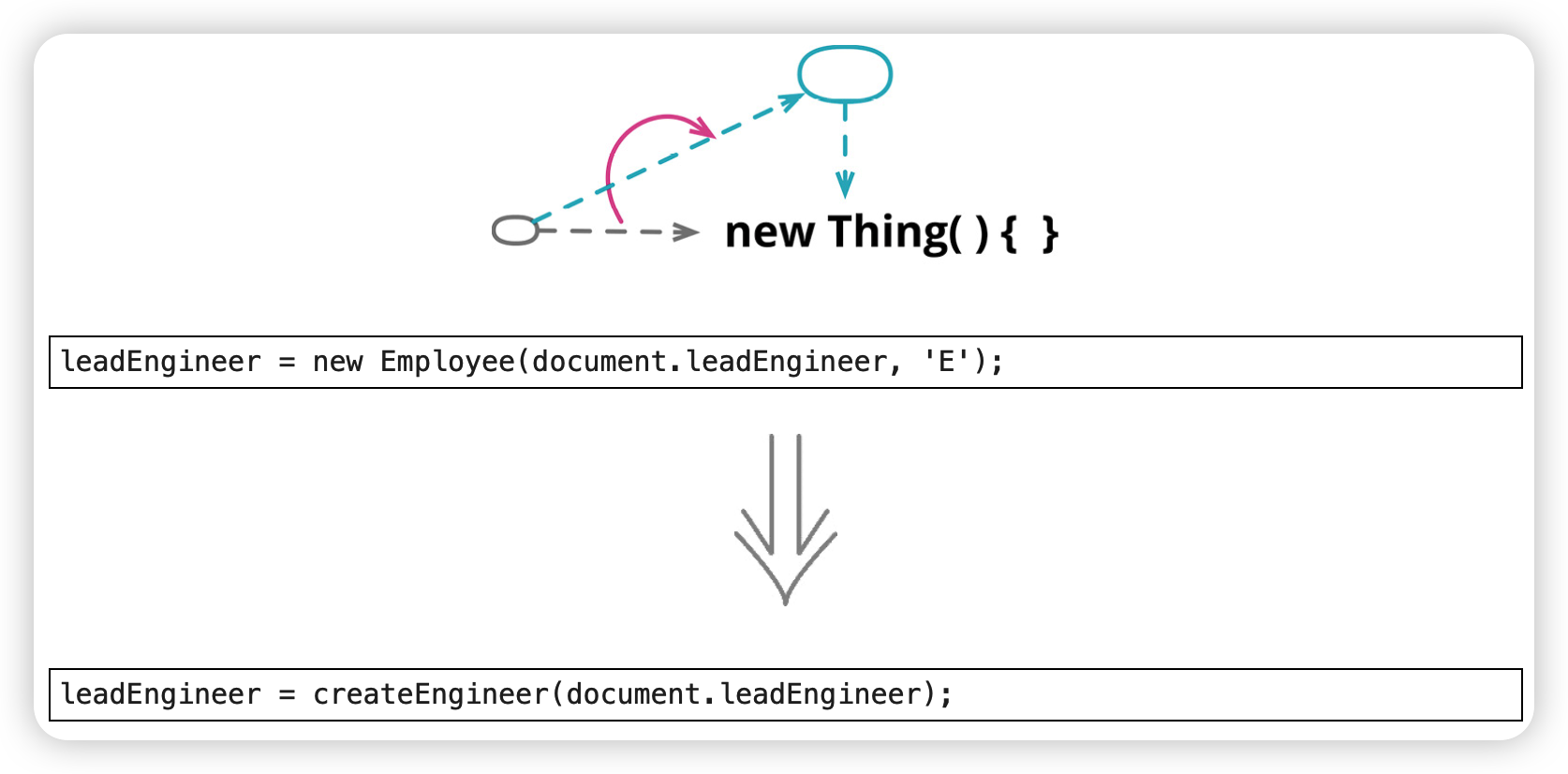
工厂函数的实现更为灵活。
以命令取代函数(Replace Function with Command)
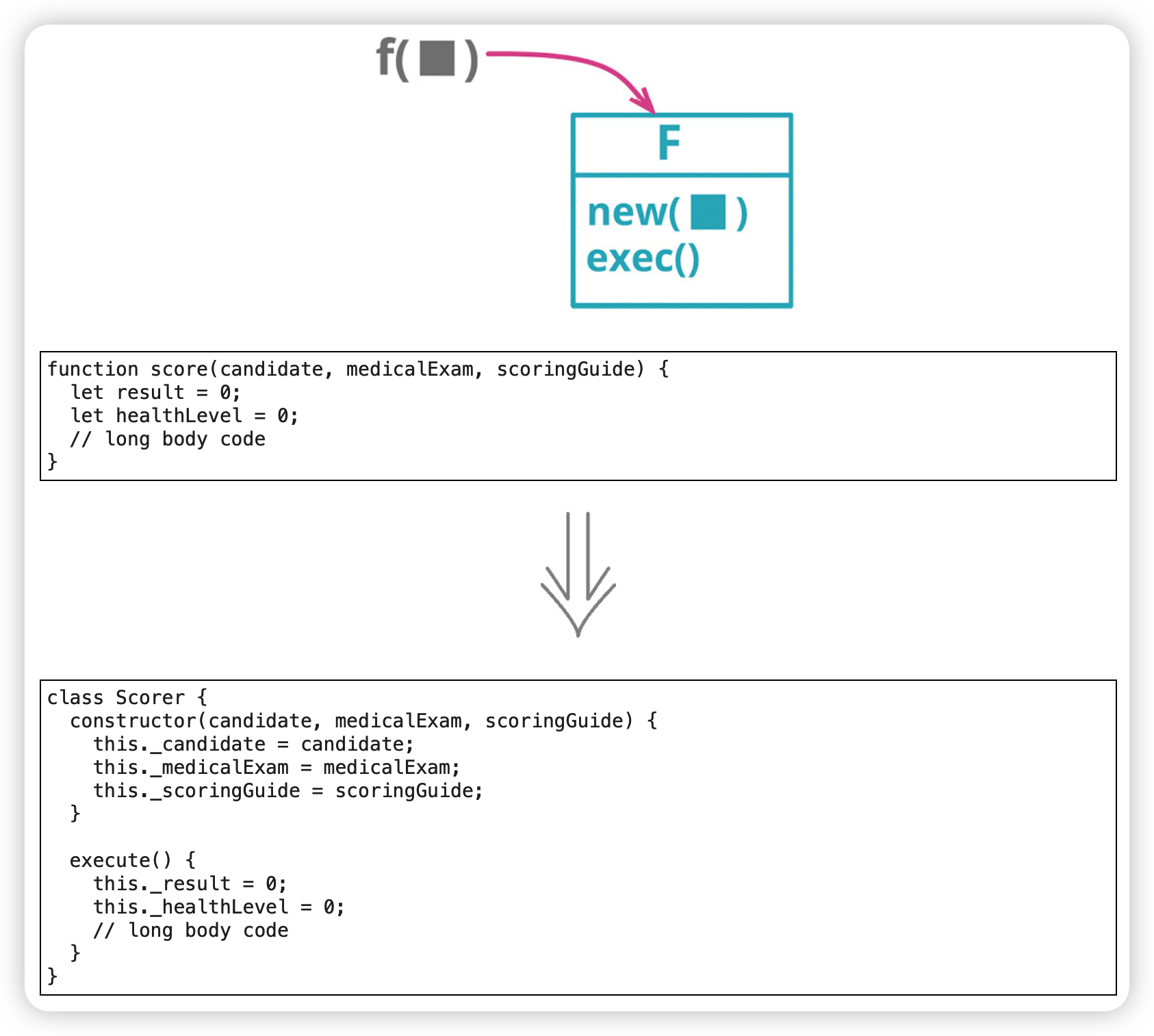
以函数取代命令(Replace Command with Function)
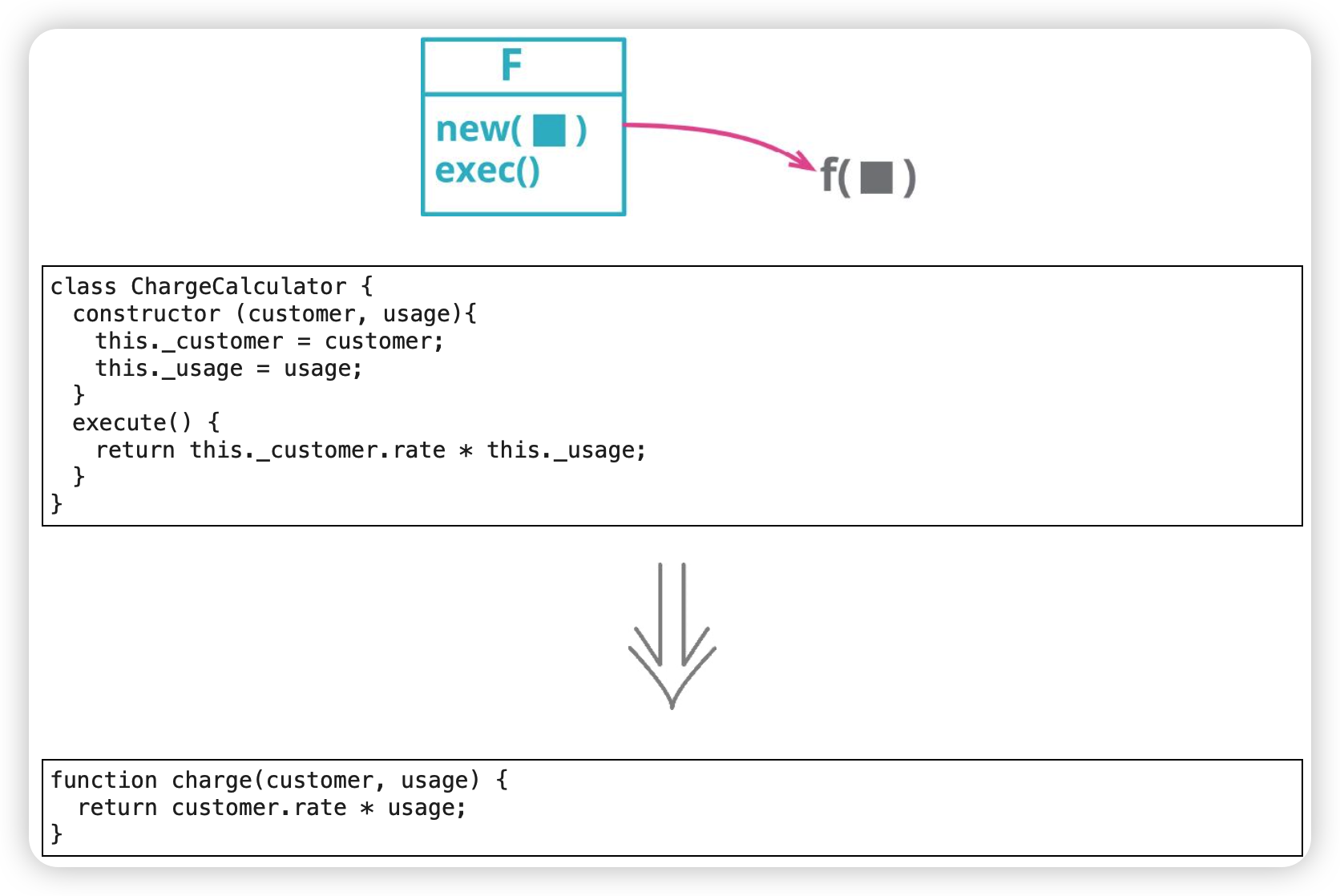
处理的逻辑不是特别复杂,则命令对象可能显得费而不惠。
第12章 处理继承关系
函数上移(Pull Up Method)
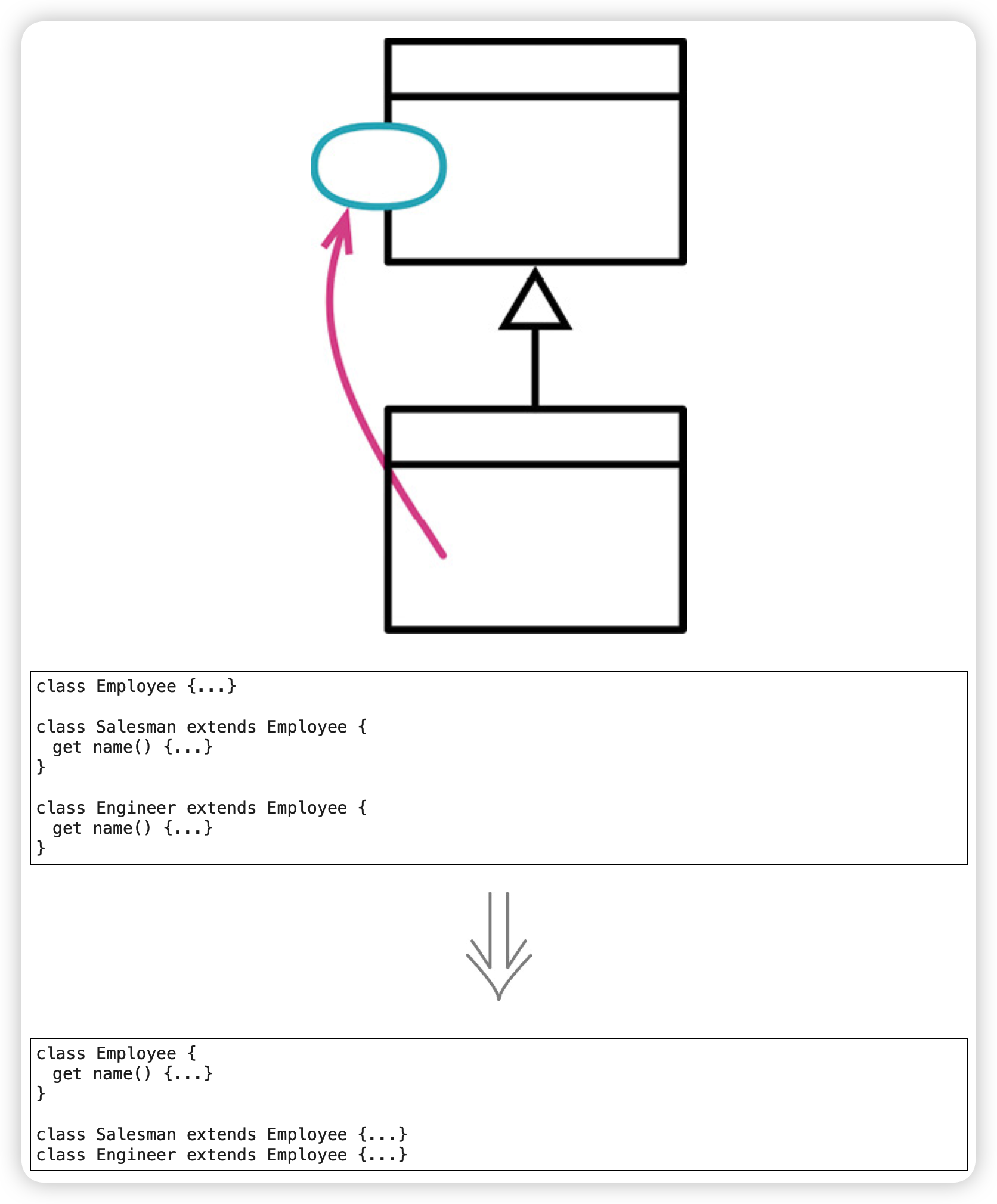
消除重复代码。
字段上移(Pull Up Field)
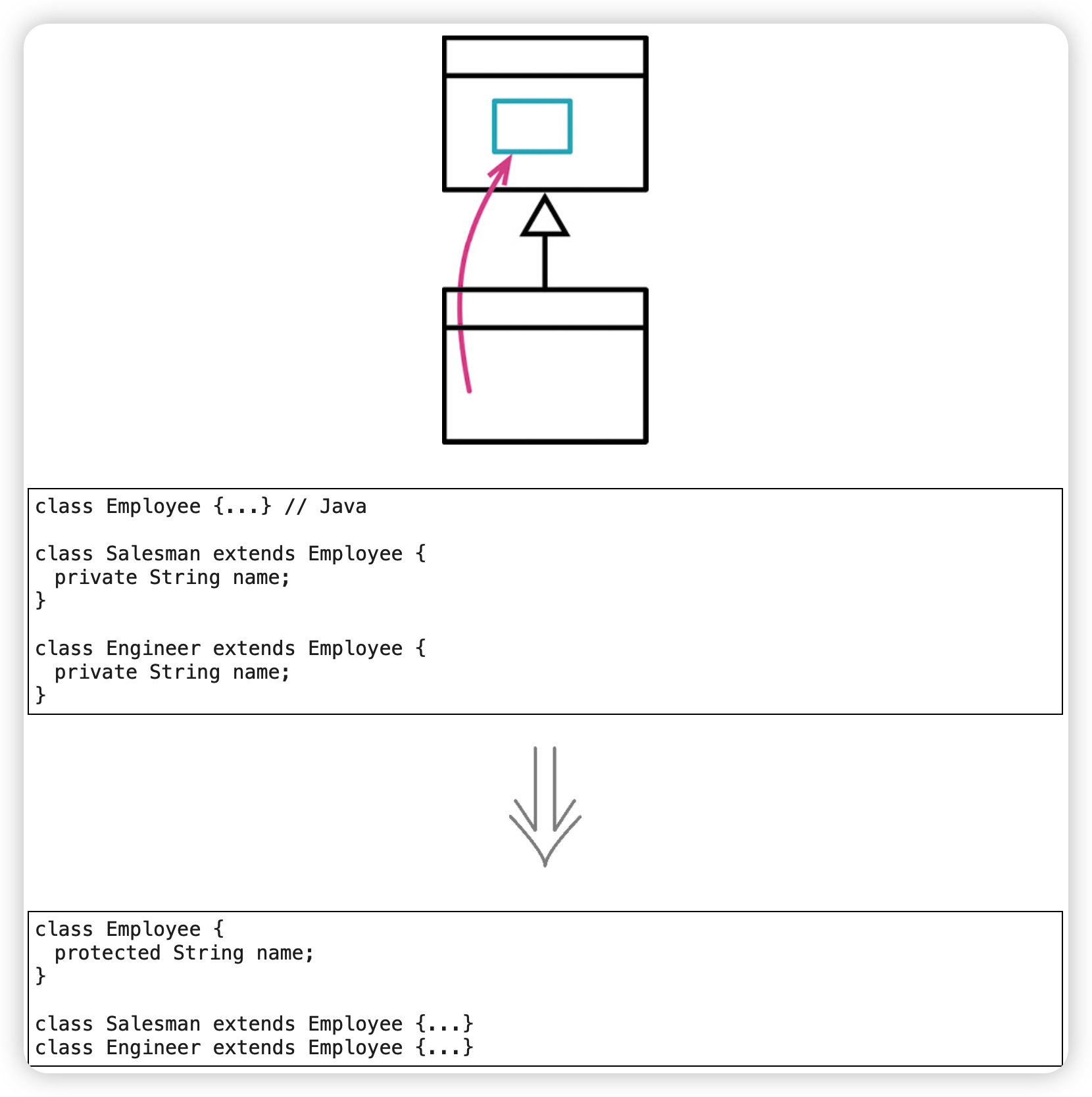
同样也是消除重复代码。
构造函数本体上移(Pull Up Constructor Body)
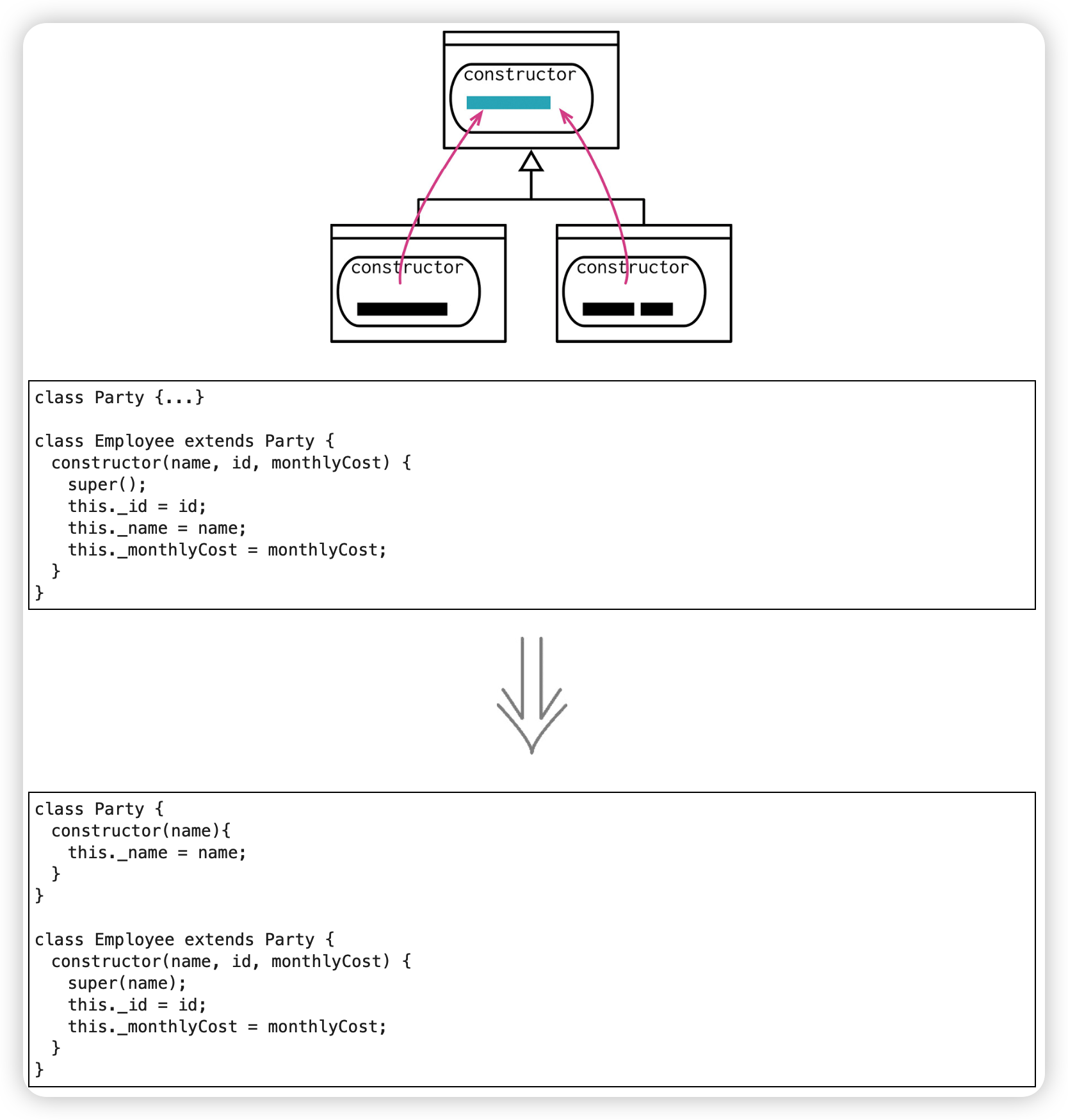
提炼各个子类函数中的重复部分至父类中,同样也是消除重复代码。
函数下移(Push Down Method)
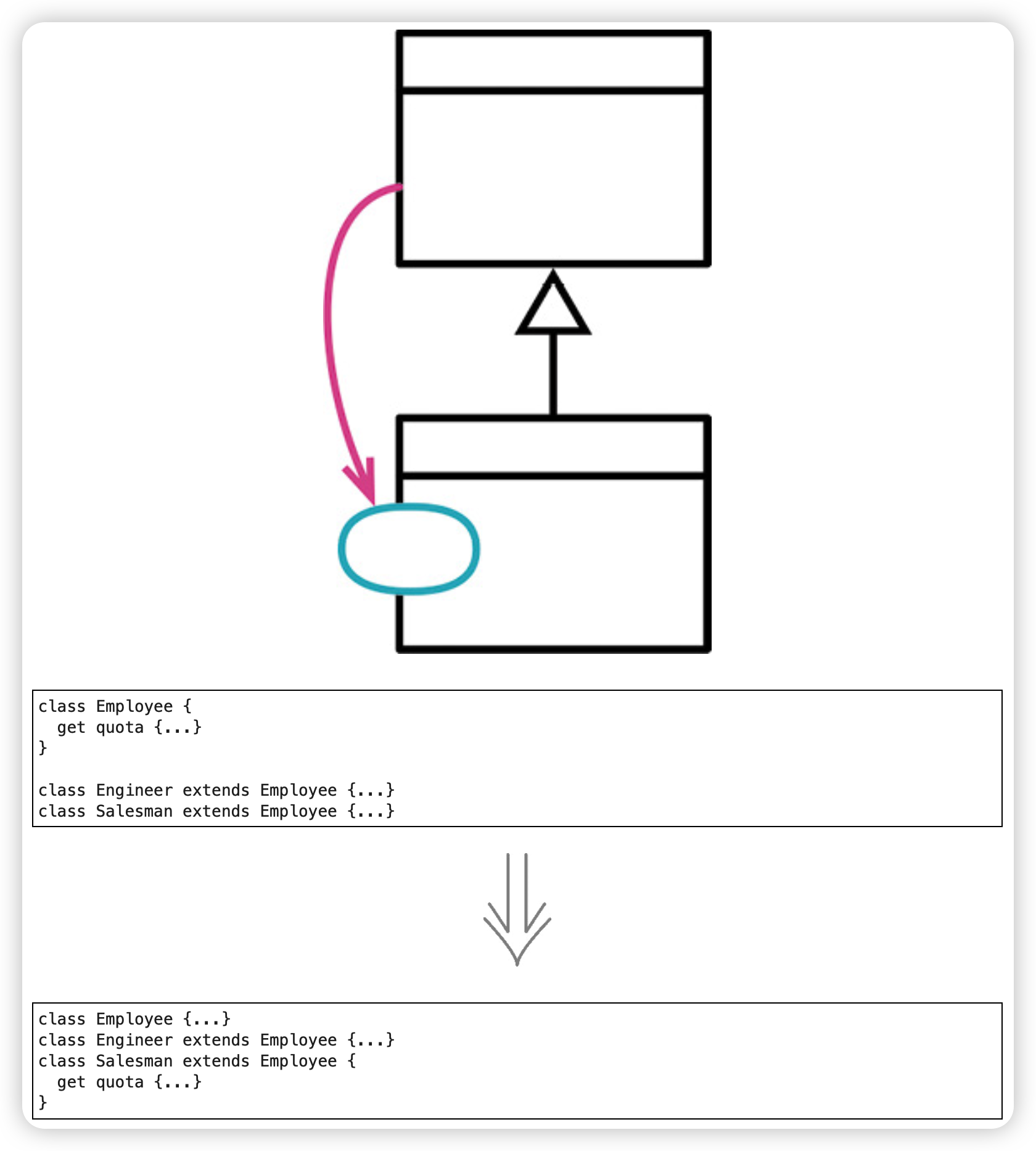
如果超类中的某个函数只与一个(或少数几个)子类有关,那么最好将其从父类中挪走,放到真正关心它的子类中去。
字段下移(Push Down Field)
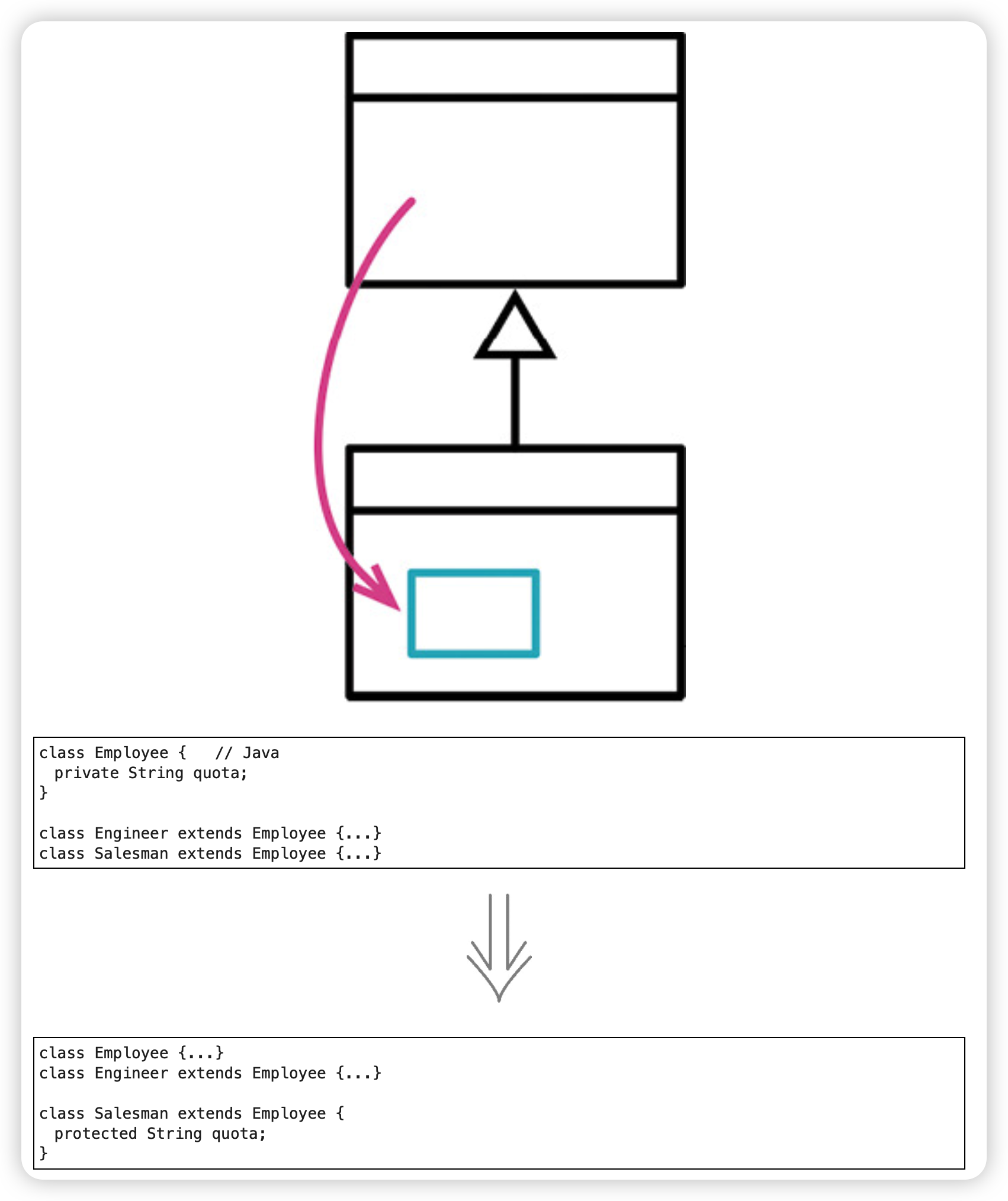
如果某个字段只被一个子类(或者一小部分子类)用到,就将其搬移到需要该字段的子类中。
以子类取代类型码(Replace Type Code with Subclasses)
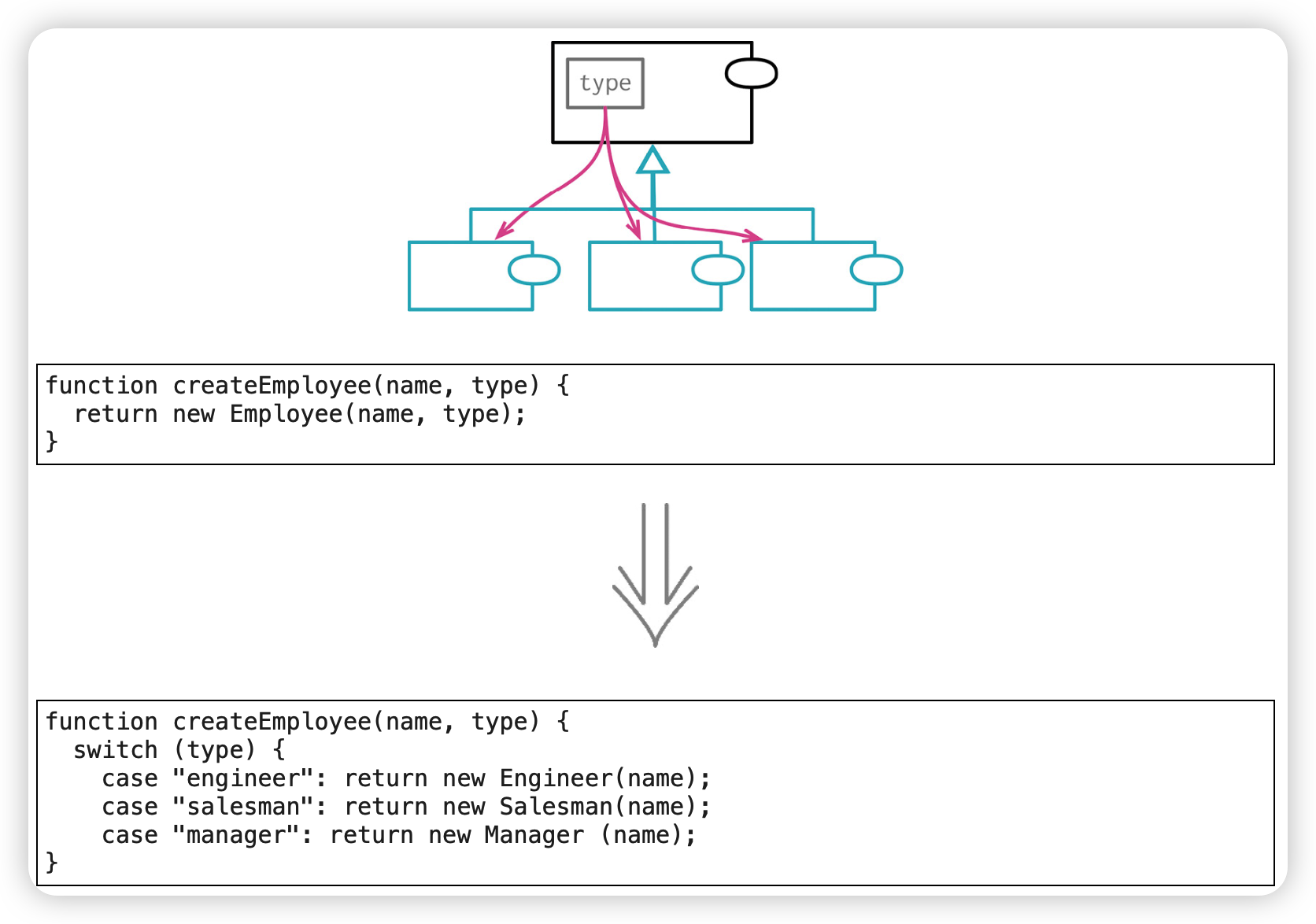
可以用多态来处理条件逻辑,而不是根据不同的类型码采取不同的行为。
有些字段或函数只对特定的类型码取值才有意义,子类的形式能更明确地表达数据与类型之间的关系。
移除子类(Remove Subclass)
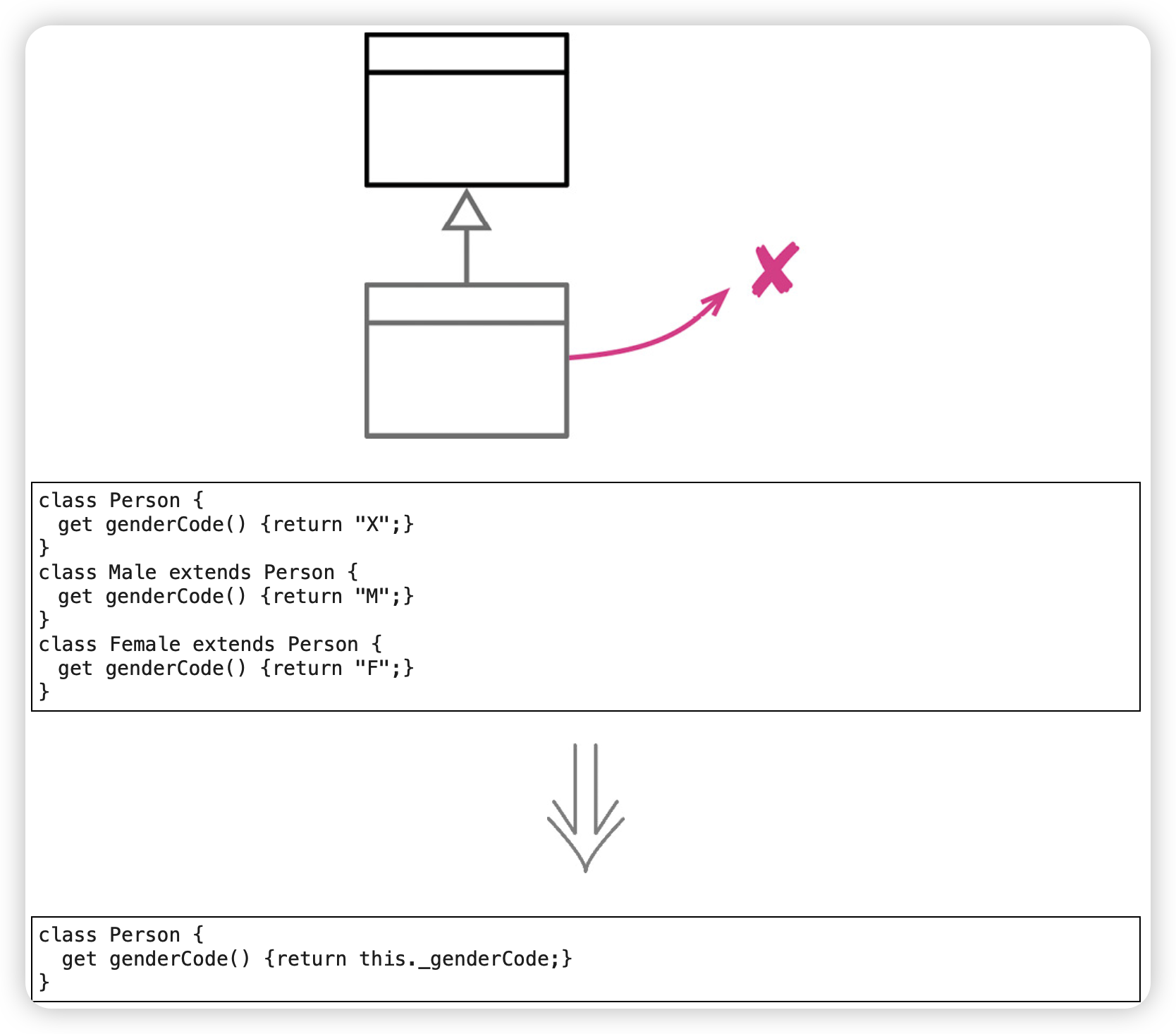
如果子类的用处太少,可以移除子类,将替换为父类的一个字段。
提炼超类(Extract Superclass)
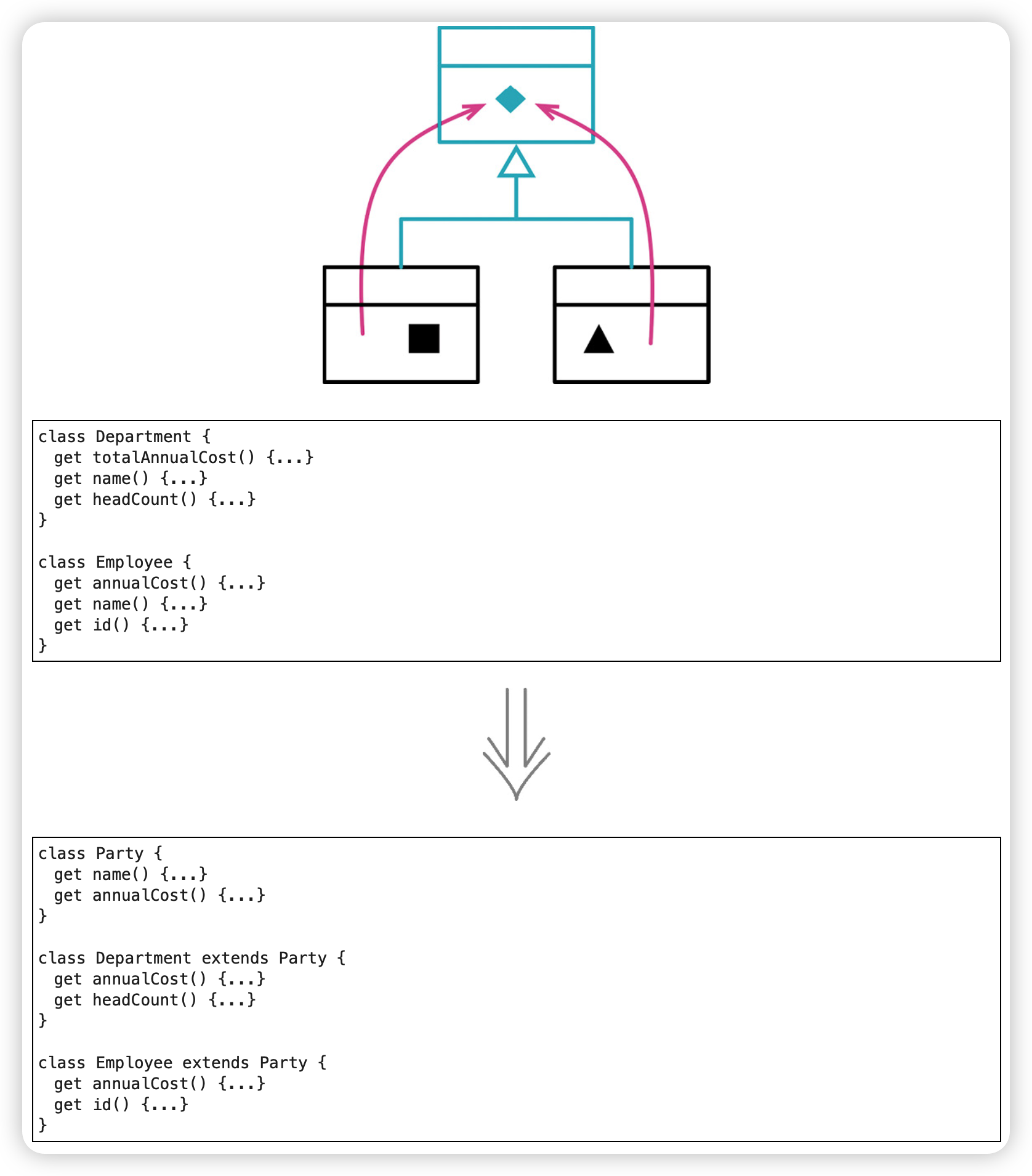
目的在于把重复的行为收拢一处。
折叠继承体系(Collapse Hierarchy)
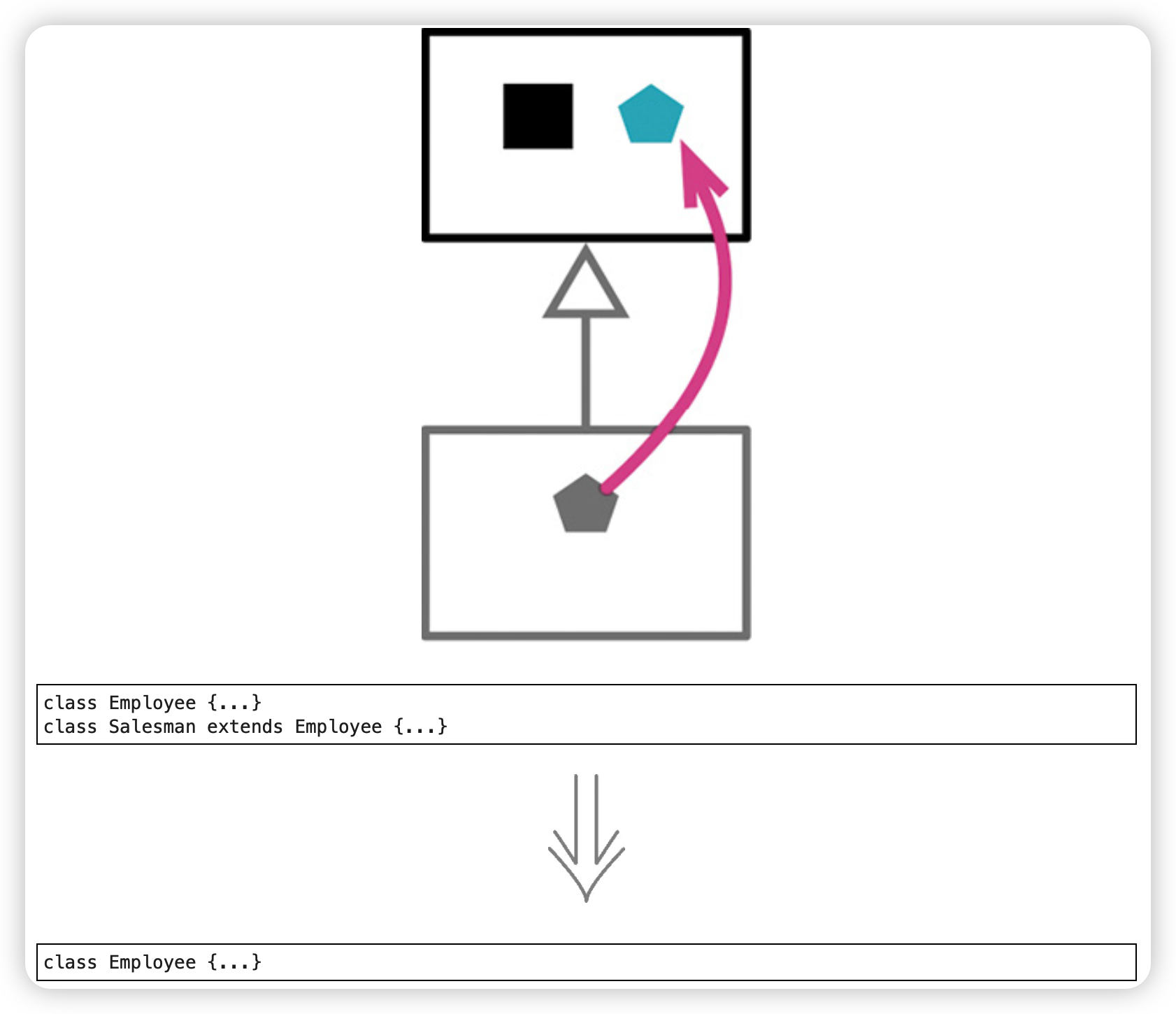
随着继承体系的演化,有时会发现一个类与其父类差别不大,此时可以把父类和子类合并起来。
以委托取代子类(Replace Subclass with Delegate)
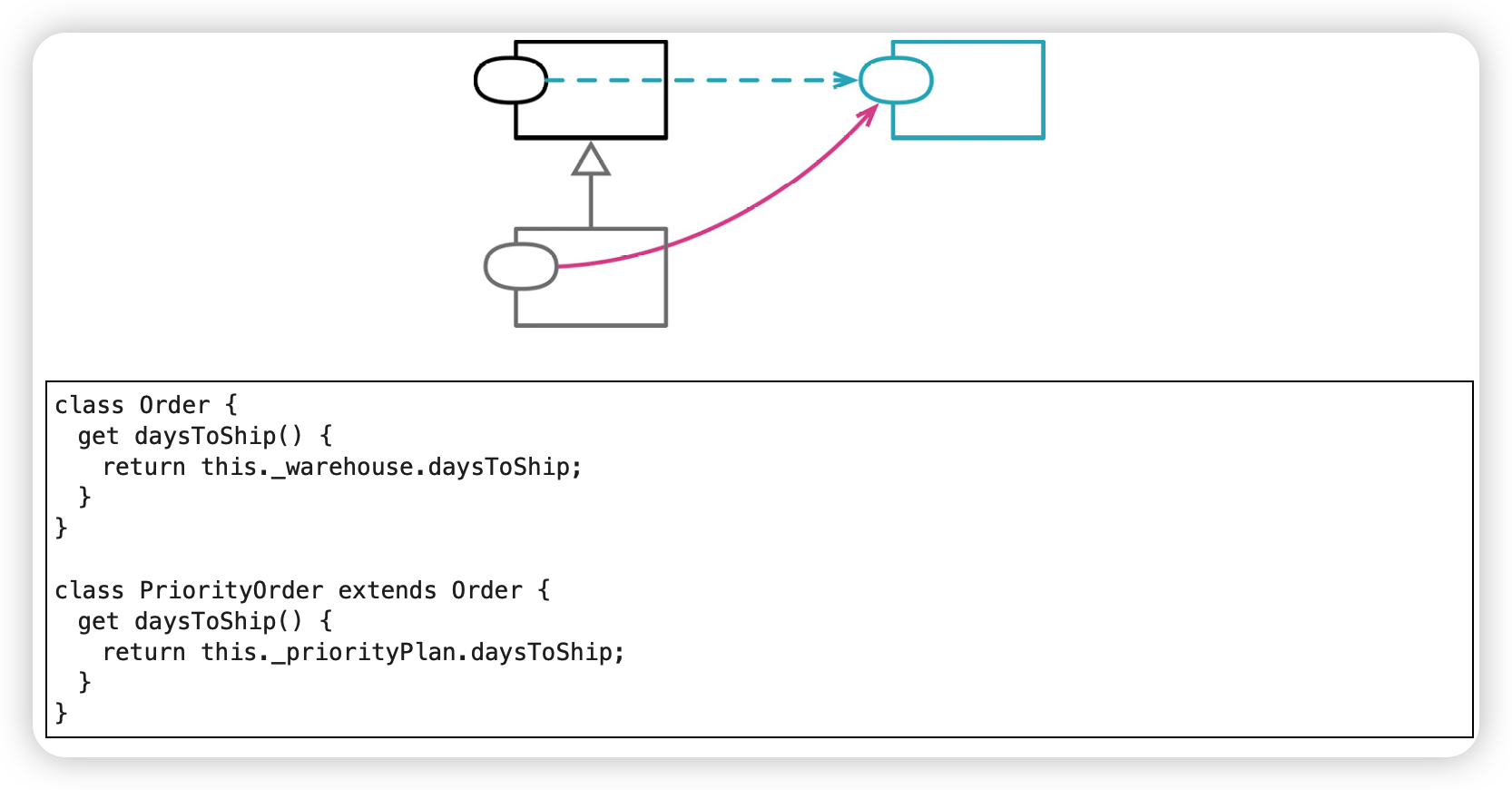

与继承关系相比,使用委托(即组合)关系时接口更清晰、耦合更少。
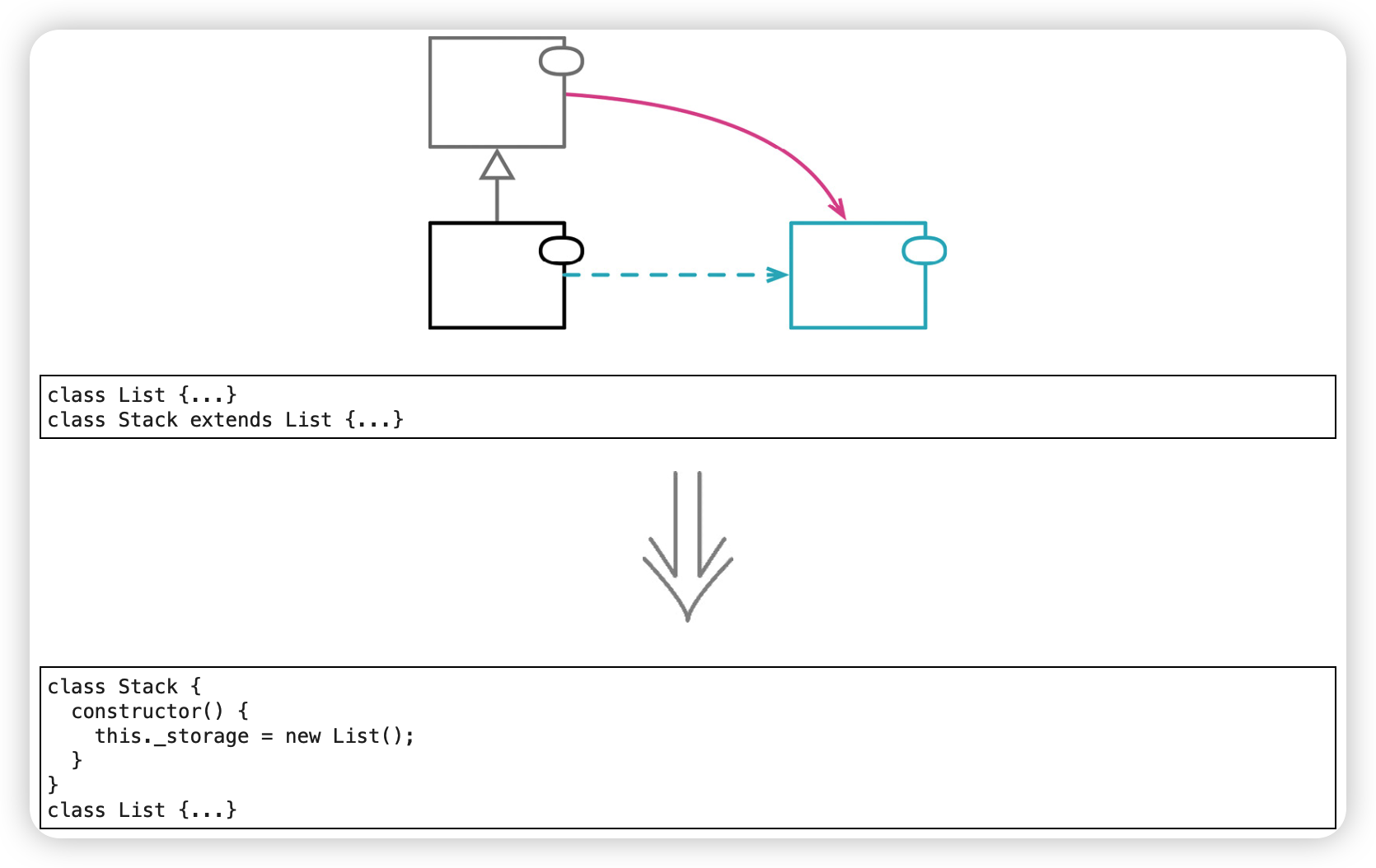
以委托取代超类(Replace Superclass with Delegate)
以组合取代继承。
一个经典的误用继承的例子:让栈(stack)继承列表(list)。这个想法的出发点是想复用列表类的数据存储和操作能力。虽说复用是一件好事,但这个继承关系有问题:列表类的所有操作都会出现在栈类的接口上,然而其中大部分操作对一个栈来说并不适用。更好的做法应该是把列表作为栈的字段,把必要的操作委派给列表就行了。
所以,如果超类的一些函数对子类并不适用,就说明我不应该通过继承来获得超类的功能。
同时也要避免走弯路:完全避免使用继承,如果符合继承关系的语义条件(超类的所有方法都适用于子类,子类的所有实例都是超类的实例),那么继承是一种简洁又高效的复用机制。
建议:首先(尽量)使用继承,如果发现继承有问题,再使用以委托取代超类。