What are the main MySQL storage engines and their differences?
MySQL supports multiple storage engines, each with distinct characteristics:
InnoDB:
- Default engine since MySQL 5.5
- Supports ACID transactions
- Provides row-level locking
- Supports foreign keys and relationship constraints
- Uses clustered indexes
MyISAM:
- Older engine, used as default before MySQL 5.5
- Non-transactional
- Table-level locking
- Faster for read-heavy operations
- Supports full-text indexing
Memory (HEAP):
- Stores data in RAM for fast access
- Non-persistent (data lost on restart)
- Useful for temporary tables and caches
Archive:
- Designed for storing large amounts of unindexed data
- Compressed storage
- Ideal for logging and data archiving
CSV:
- Stores data in CSV files
- Useful for data interchange with other applications
InnoDB’s Key Components and Principles
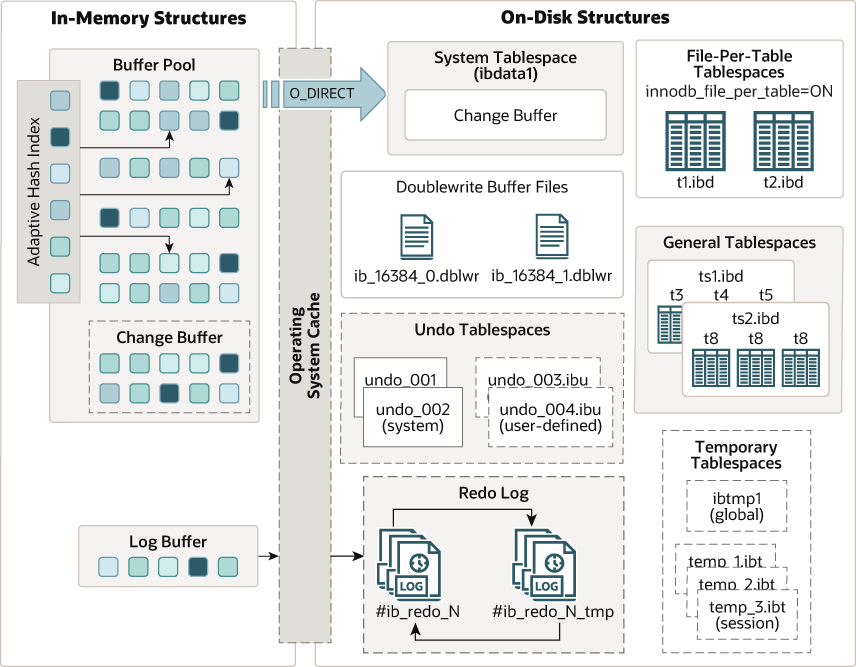
B+ Tree Structure
- Used for all indexes
- Efficiently handles both range and point queries
Buffer Pool
- In-memory cache for data and indexes
- Reduces disk I/O for better performance
Change Buffer
- Caches changes to secondary indexes
- Improves write performance
Redo Log
- Records all changes to ensure durability
- Crucial for crash recovery
Undo Log
- Supports transaction rollback and consistent reads
- Enables multi-version concurrency control (MVCC)
ACID Compliance
- Ensures data integrity and reliability
Row-Level Locking
- Allows high concurrency for multi-user environments
Crash Recovery
- Automatic recovery after system crashes
Foreign Key Support
- Maintains referential integrity between tables
Transactions
- Supports both auto-commit and explicit transactions
What are the main types of MySQL indexes, and how does the B+ tree work?
B+ tree indexes:
- Default index type
- Suitable for comparisons using <, >, =, BETWEEN, and LIKE
Hash indexes:
- Faster for exact lookups
- Not suitable for range queries
- Used internally by Memory tables
Full-text indexes:
- Optimized for full-text searches
- Available in MyISAM and InnoDB (since MySQL 5.6)
Spatial indexes:
- Used for indexing spatial data types
B+ tree structure and characteristics:
- A self-balancing tree structure
- All leaf nodes are at the same level
- Internal nodes store keys and pointers to child nodes
- Leaf nodes store keys and data (or pointers to data)
- Leaf nodes are linked, allowing efficient range queries
B+ tree advantages:
- Maintains sorted data for efficient range queries
- Allows for fast insertions, deletions, and updates
- Provides logarithmic time complexity for search operations
- Reduces disk I/O by storing multiple keys in each node
B+ tree in MySQL:
- InnoDB uses B+ trees for both clustered and secondary indexes
- Clustered index stores the actual data in leaf nodes
- Secondary indexes store the primary key in leaf nodes
When updating large data sets in MySQL, which strategies can be used?
Batch the updates to minimize long transactions. Use transactions for consistency when necessary. Disable and re-enable indexes to speed up the process (Only applicable for non-unique indexes and for tables using the MyISAM storage engine. For InnoDB, this approach won’t work as InnoDB maintains indexes automatically.). Use tools like pt-online-schema-change for large schema changes. Optimize buffer pool size to handle large datasets more efficiently. Monitor the update progress to detect and address performance bottlenecks.
Database Index Concepts
1. Index
An index is a data structure that improves the speed of data retrieval operations on a database table.
2. Key
A key is a column or set of columns in a table that is used to identify a row uniquely.
3. Primary Key
A primary key is a special type of key that uniquely identifies each record in a table. It must contain unique values and cannot contain null values. A table can have only one primary key.
4. Clustered Index
A clustered index determines the physical order of data in a table. In MySQL’s InnoDB, the primary key is always the clustered index.
5. Secondary Index
A secondary index is any index that is not the clustered index. In InnoDB, secondary index leaf nodes contain the indexed columns and a pointer to the primary key value.
Clustered Index vs. Secondary Index
Clustered Index:
Root Node
│
├── Internal Nodes (with key ranges)
│
└── Leaf Nodes (contain actual data rows)
Secondary Index:
Root Node
│
├── Internal Nodes (with key ranges)
│
└── Leaf Nodes (contain indexed column + primary key)
Explain the differences between MyISAM and InnoDB storage engines.
MyISAM:
- Faster for read-heavy operations
- Table-level locking
- Does not support transactions
- Does not support foreign keys
InnoDB:
- Supports ACID transactions
- Row-level locking
- Supports foreign keys
- Better crash recovery
Explain the concept of normalization in databases.
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity.
- First Normal Form (1NF): Eliminate repeating groups
- Second Normal Form (2NF): Eliminate partial dependencies
- Third Normal Form (3NF): Eliminate transitive dependencies
- Boyce-Codd Normal Form (BCNF): A stricter version of 3NF
What is a transaction in MySQL?
A transaction is a sequence of one or more SQL statements that are executed as a single unit of work. The main properties of transactions are often referred to as ACID:
- Atomicity: All operations in a transaction succeed or every operation is rolled back
- Consistency: The database is in a consistent state before and after the transaction
- Isolation: Intermediate transaction states are invisible to other transactions
- Durability: Completed transactions are permanently saved in the database
Explain the different types of joins in MySQL.
- INNER JOIN: Returns rows when there is a match in both tables
- LEFT JOIN: Returns all rows from the left table, and the matched rows from the right table
- RIGHT JOIN: Returns all rows from the right table, and the matched rows from the left table
- FULL JOIN: Returns rows when there is a match in one of the tables
- CROSS JOIN: Returns the Cartesian product of the two tables
What is the difference between CHAR and VARCHAR data types?
- CHAR: Fixed-length string data type. Always uses the specified length, padding with spaces if necessary
- VARCHAR: Variable-length string data type. Uses only as much space as needed, plus one or two bytes to store length
Explain the concept of indexing in MySQL.
Indexing is a data structure technique used to quickly locate and access data in a database. It improves the speed of data retrieval operations but can slow down data insertion and update operations.
What is a stored procedure in MySQL?
A stored procedure is a prepared SQL code that you can save and reuse. Benefits include:
- Improved performance (compiled once, stored in executable form)
- Reduction in network traffic
- Centralized business logic in the database server
Explain the concept of database sharding.
Sharding is a database architecture pattern related to horizontal partitioning — the practice of separating one table’s rows into multiple different tables, known as partitions. Each partition has the same schema and columns, but entirely different rows.
When using hash index in mysql, it supports ange quesry?
When using a hash index in MySQL, it only supports equality comparisons using the = or <=> operators. It does not support range queries (e.g., using <, >, <=, >=, BETWEEN, LIKE). This is a key limitation of hash indexes compared to B+ tree indexes, which support both equality and range comparisons.
Explain <=> operator
In MySQL, the <=> operator is the NULL-safe equality comparison operator.
It compares two values for equality, but treats NULL values as equal to each other. This is different from the = operator, which considers NULL unequal to any value, including another NULL.
For example:
NULL = NULLevaluates tofalse.NULL <=> NULLevaluates totrue.
Query Processing
MySQL processes queries through several stages:
- Parsing: Checks SQL syntax and creates a parse tree.
- Preprocessing: Checks table and column existence, resolves aliases.
- Query optimization: Determines the most efficient execution plan.
- Execution: Runs the query and returns results.
Key components:
- Query Cache (deprecated in MySQL 8.0)
- Query Optimizer
- Storage Engine API
Transactions and Locking
MySQL supports transactions and various locking mechanisms:
- ACID properties: Ensures data integrity and consistency.
- Isolation levels: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE.
- Locking mechanisms:
- Table-level locks
- Row-level locks (InnoDB)
- Intention locks
- Gap locks and next-key locks (InnoDB)
Query Optimization
Use appropriate indexes:
- Create indexes on frequently queried columns.
- Use composite indexes for multi-column conditions.
Optimize JOIN operations:
- Use proper join types (INNER, LEFT, RIGHT).
- Order tables in joins from smallest to largest.
Utilize EXPLAIN to analyze query execution plans:
- Identify full table scans and inefficient index usage.
- Look for opportunities to add or modify indexes.
Avoid using wildcards at the beginning of LIKE patterns:
- Use
column LIKE 'abc%'instead ofcolumn LIKE '%abc'.
- Use
Use LIMIT for pagination:
- Implement efficient pagination with LIMIT and OFFSET.
Optimize subqueries:
- Rewrite subqueries as JOINs when possible.
- Use correlated subqueries judiciously.
Utilize query hints:
- Use INDEX hints to force specific index usage.
- Apply JOIN_ORDER hints for complex queries.
Implement proper WHERE clause:
- Place most restrictive conditions first.
- Avoid using functions on indexed columns in WHERE clauses.
Use appropriate data types:
- Choose the smallest data type that can hold the required data.
- Use ENUM or SET for columns with a fixed set of values.
Optimize GROUP BY and ORDER BY:
- Add indexes to support these operations.
- Use covering indexes when possible.
Schema Optimization
Normalize tables appropriately:
- Aim for 3NF (Third Normal Form) in most cases.
- Consider denormalization for read-heavy workloads.
Use appropriate data types:
- Use INT for primary keys instead of larger types like BIGINT when possible.
- Use VARCHAR instead of CHAR for variable-length strings.
Implement proper constraints:
- Use foreign key constraints to maintain data integrity.
- Implement CHECK constraints for data validation.
Partition large tables:
- Use range, list, or hash partitioning for better query performance.
- Implement partition pruning for efficient data access.
Use efficient storage engines:
- Use InnoDB for transactional tables.
- Consider MyISAM for read-only or read-heavy tables.
Implement proper indexing strategy:
- Create indexes based on query patterns.
- Avoid over-indexing, which can slow down writes.
Use appropriate character sets and collations:
- Use UTF8MB4 for full Unicode support.
- Choose appropriate collations for sorting and comparison.
Implement vertical partitioning:
- Split large tables into smaller ones based on column usage patterns.
Use computed columns:
- Implement computed columns for frequently calculated values.
Optimize BLOB and TEXT columns:
- Store large objects separately when possible.
- Use external file storage for very large objects.
Server Configuration Optimization
Optimize MySQL server configuration for better performance:
Adjust buffer pool size:
- Set innodb_buffer_pool_size to 70-80% of available RAM for InnoDB.
Optimize thread handling:
- Set thread_cache_size appropriately to reduce thread creation overhead.
Configure query cache (for versions prior to 8.0):
- Set query_cache_type and query_cache_size based on workload.
Adjust max_connections:
- Set based on expected concurrent connections.
Optimize file system usage:
- Use innodb_file_per_table for easier management of table spaces.
Configure log files:
- Set appropriate sizes for binary log and InnoDB log files.
Optimize I/O subsystem:
- Use innodb_flush_method=O_DIRECT on Linux for improved I/O performance.
Tune sort buffer:
- Adjust sort_buffer_size based on complex query requirements.
Configure temporary tables:
- Set tmp_table_size and max_heap_table_size for in-memory temporary tables.
Optimize network settings:
- Adjust max_allowed_packet for large queries or BLOB data.
Hardware Optimization
Optimize hardware for MySQL performance:
Use SSDs for database storage:
- Significantly improves random I/O performance.
Implement RAID for improved I/O:
- Use RAID 10 for balanced read/write performance.
Allocate sufficient RAM:
- Ensure enough memory for MySQL buffer pool and operating system.
Use multiple CPU cores:
- MySQL can utilize multiple cores for query execution.
Optimize network infrastructure:
- Use high-speed network interfaces and switches.
Implement proper storage layout:
- Separate data files, log files, and temporary files on different disks.
Consider using PCIe NVMe drives:
- Provides extremely high I/O performance for demanding workloads.
Use battery-backed write cache:
- Improves write performance while maintaining data integrity.
Implement proper cooling and power supply:
- Ensure stable environment for consistent performance.
Consider using dedicated database servers:
- Separates database workload from application servers.
Replication
Asynchronous replication:
- Traditional master-slave setup.
- Slaves can lag behind the master.
Semi-synchronous replication:
- Master waits for at least one slave to acknowledge receipt of events.
Group Replication:
- Multi-master update everywhere replication with built-in conflict detection.
Binary log file position-based replication:
- Traditional method using binary log positions.
GTID-based replication:
- Uses Global Transaction Identifiers for easier failover and slave provisioning.
Key features:
- Row-based, statement-based, or mixed replication formats.
- Parallel replication for improved performance.
- Delayed replication for disaster recovery.
Partitioning
MySQL supports table partitioning for improved query performance and data management:
Range partitioning:
- Partitions based on column value ranges.
List partitioning:
- Partitions based on lists of column values.
Hash partitioning:
- Distributes data evenly across partitions using a hash function.
Key partitioning:
- Similar to hash partitioning but uses MySQL’s internal hashing function.
Composite partitioning:
- Combines multiple partitioning methods.
Benefits:
- Improved query performance through partition pruning.
- Easier data archiving and deletion.
- Better distribution of data across multiple disks.
COUNT(*)``COUNT(1)``COUNT(primary_key_field)``COUNT(field)
| Function | Count Content | Affected by NULLs | Performance |
|---|---|---|---|
COUNT(*) | All rows | Not affected | Typically the fastest, highly optimized by DBMS |
COUNT(1) | All rows (equivalent to COUNT(*)) | Not affected | Similar performance to COUNT(*) |
COUNT(primary_key_field) | Number of non-NULL values in the primary key field | Typically not affected (primary keys are usually NOT NULL) | Similar performance to COUNT(*) |
COUNT(field) | Number of non-NULL values in the specified field | Affected | Generally slower than COUNT(*) and COUNT(1), depends on indexing |